统计和机器学习工具箱
使用统计学和机器学习分析和建模数据

统计和机器学习工具箱™提供描述,分析和模型数据的功能和应用。您可以使用描述性统计,可视化和聚类来进行探索数据分析;适合数据的概率分布;为Monte Carlo模拟生成随机数,并执行假设测试。回归和分类算法允许您使用AutomL使用分类和回归学习者应用程序的数据和建立预测模型的推论,并使用Automal使用Automl。
对于多维数据分析和特征提取,工具箱提供主成分分析(PCA),正常化,维数减少和特征选择方法,可让您识别具有最佳预测功率的变量。
工具箱提供监督、半监督和非监督机器学习算法,包括支持向量机(svm)、增强决策树、k-means和其他聚类方法。万博1manbetx您可以应用部分依赖图和LIME等可解释性技术,并自动生成用于嵌入式部署的C/ c++代码。许多工具箱算法可以用于太大而无法存储在内存中的数据集。
开始:

免费电子书
掌握机器学习:使用MATLAB逐步指南
可视化
使用概率绘图,盒子图,直方图,分位数 - 分位数和多变量分析的高级绘图探索数据,例如树木图,双针和安德鲁斯图。

使用多维散点图探索变量之间的关系。

使用分组方式和差异探索数据。
聚类分析
通过使用K-Means,K-METOIDS,DBSCAN,分层和光谱聚类和高斯混合和隐藏的Markov模型进行分组数据来发现模式。

将DBSCAN应用于两个同心组。
特征提取
使用无监督的学习技术从数据中提取特征,例如稀疏过滤和重建ICA。您还可以使用专门的技术来提取图像,信号,文本和数字数据的特征。

从移动设备提供的信号中提取特征。
功能选择
自动识别提供最佳预测电源的功能子集,可以在建模数据中。特征选择方法包括逐步回归,顺序特征选择,正则化和集合方法。

NCA有助于选择保留模型的最精确度的功能。
特征转换和减少维度
通过将现有(非分类)特征转换为新的预测变量来减少维度,其中可以丢弃更少的描述性功能。特征转换方法包括PCA,因子分析和非负矩阵分解。

PCA可以将高维向量投影到具有保存的大多数信息的低维正交坐标系上。
火车,验证和曲调预测模型
比较各种机器学习算法,选择功能,调整HyperParameters,并评估许多流行分类和回归算法的性能。构建并自动使用交互式应用程序优化预测模型,并逐步改进具有流数据的模型。

模型解释性
通过应用已建立的可解释性方法,包括部分依赖图、个体条件期望(ICE)和局部可解释性模型不可知论解释(LIME),提高黑箱机器学习模型的可解释性。

LIME在局部地区建立复杂模型的简单近似。
自动机器学习
通过自动调整超参数,选择功能和模型以及通过成本矩阵寻址数据集不平衡来提高模型性能。

优化贝叶斯优化有效地优化超级参数。
线性和非线性回归
从许多线性和非线性回归算法中选择多个预测器或响应变量对复杂系统的行为进行建模。拟合具有嵌套和/或交叉随机效应的多层次或层次化、线性、非线性和广义线性混合效应模型,以执行纵向或面板分析、重复测量和增长建模。

与回归学习者应用交互式回归模型。
非参数回归
使用支持向量机、随机森林、高斯过程和高斯核,在不指定描述预测器和响应之间关系的模型的情况下生成精确的拟合。

识别使用大分回归的异常值。
方差分析(ANOVA)
将样本方差分配给不同的源,并确定各种群体中是否出现在不同人群中。使用单向,双向,多路,多变量和非参数ANOVA,以及协方差分析(ANOCOVA)和反复措施的方差分析(RANOVA)。

使用多道ANOVA的测试组。
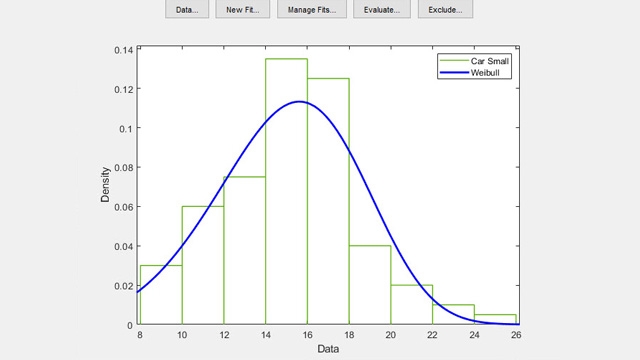
使用Distribution Fitter应用程序交互式地适合发行版。

交互式生成随机数。
假设检验
执行T检验,分配测试(Chi-Square,Jarque-Bera,Lipleiefors和Kolmogorov-Smirnov),以及一个,配对或独立样品的非参数测试。测试自动鼠标和随机性,以及比较分布(两个样本Kolmogorov-Smirnov)。

在单面T检验中的抑制区域。

应用Box-Behnken设计来生成高阶响应曲面。
统计过程控制(SPC)
通过评估过程可变性来监测和改进产品或过程s manbetx 845。创建控制图,估算过程能力,并执行量具重复性和再现性研究。

使用控制图监控制造过程。
可靠性和生存分析
通过执行COX比例危险回归和拟合分布,可视化和分析故障时间数据。计算经验危险,幸存者和累积分布函数,以及内核密度估计。

失效数据作为“审查”值的一个例子。
分析高阵列的大数据
使用具有许多分类,回归和聚类算法的高阵列和表,以在不改变代码的情况下培训不适合内存的数据集的模型。


加快并行计算工具箱或MATLAB并行服务器的计算。
云和分布式计算
使用云实例加快统计和机器学习计算。在MATLAB Online™中执行完整的机器学习工作流程。

在Amazon或Azure云实例上执行计算。
代码生成
生成便携式和可读的C或C ++代码,用于推理分类和回归算法,描述性统计和使用MATLAB编码器™的概率分布。使用固定点Designer™的精度降低,并使用固定点设计器™的精度降低,并在不重新生成预测码的情况下更新部署模型的参数。

要部署的两条路径:生成C代码或编译MATLAB代码。
与Simulink集成万博1manbetx
将机器学习模型与Simulink模型集成,以便部署到嵌入式硬件或用于系统仿真、万博1manbetx验证和验证。
与应用程序和企业系统集成
将统计和机器学习模型作为独立,MapReduce或Spark™应用部署;作为Web应用程序;或作为微软®excel.®使用Matlab Compiler™的加载项。构建C / C ++共享库,Microsoft .NET程序集,Java®课程和python®使用Matlab Compiler SDK™的包。

使用MATLAB编译器整合空气质量分类模型。
自动化
自动选择最佳模型和相关超参数进行回归(fitrauto)
可解释性
获取当地可解释的模型 - 不可知的解释(石灰)
SVM预测块
在Simulink中模拟和生成SVM模型的代码万博1manbetx
增量学习
逐步训练线性回归和二元分类模型
半监督学习
使用图和自训练模型(fitsemigraph, fitself)将部分类标签外推到整个数据集
代码生成
为预测生成单精度C/ c++代码
性能
加快SVM模型的培训
看到发行说明有关这些功能的详细信息和相应的功能。

机器学习ondramp.
交互式介绍用于分类问题的实际机器学习方法。

{kind=link}