我2C2利用MATLAB对来自牛奶加工厂的数据进行预处理和对齐,并对数据进行分析和可视化,开发出能够预测奶粉功能特性的机器学习模型。
在Matlab工作,我2C2研究人员从Fonterra数据库中提取的加载过程数据。清洁和对齐数据涉及使用插值缺少数据的估计值,并通过解释以多种格式生成的时间戳来对齐不同的数据集。
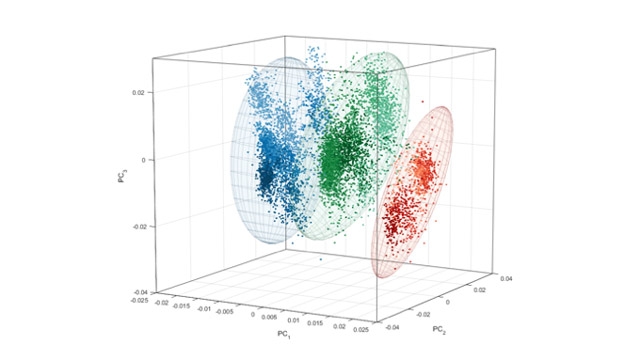
一旦团队进行了干净的数据集,他们使用统计和机器学习工具箱,使用主成分分析(PCA)和部分最小二乘(PLS)回归来执行统计分析。该团队补充了Matlab 3D直方图,散点图和其他图表的多变量分析,以可视化结果并与Fonterra工程师分享他们的调查结果。
继续在MATLAB中,I2C2团队使用最小绝对收缩和选择算子(LASSO)方法实现了更高级的回归模型,并评估了各种机器学习分类器。
最初,分类器达到了小于50%的预测精度。这是因为培训数据仅包括牛奶粉处理参数显着变化时记录的几个数据实例。虽然较少数量的此类实例让运营人员高兴,但它没有提供足够的模型建筑数据。要纠正此问题,该团队在培训数据中提升了不合标准的样本,并下采样剩余的样本。
为了提高预测的准确性,他们使用重新采样的训练数据来评估其他分类器类型。通过Classification Learner应用程序,他们快速评估了20多个分类器,包括支持向量机、k近邻和各种决策树,包括推进树和袋装决策树。万博1manbetx他们最终发现,提高树木的效果最好,预测准确率接近95%。
我2C2研究人员目前正在将自动图像处理集成到他们的分析工作流中。利用图像处理工具箱™,该团队分析了数千张奶粉颗粒的照片,计算了颗粒大小、凹凸度、圆度和其他形状因素,并将这些指标与奶粉的功能特性关联起来。