Die ClusterAnalyse Befasst Sich Mit der Anwendung von聚类 - algorithmenen und der Erkennung verseckter Mater oder Gruppierungen在einem datensatz。Sie Wird DaherHäufig在Der Proforativen DateNanalyse Eingesetzt,Eignet Sich Aber Auch Zur Erkennung von Anomalien und Zur VorverarbeitungBeimÜberwachtenLernen。
Clustering-Algorithmen Bilden Gruppierungen AUF eine Weise,Dass Daten Insianhalb Einer Gruppe(Oter Eines Clusters)EinHöheresMaßAnnhnlichkeitAufweisen Als Laten在Anderen Clustern。EsKönnenverschiedeneähnlichkeitsmaßeHerangezogenWerden,Z。B. Euklidisch,Probabilistisch oder Kosinusabstand und Korrelation。Die Meisten Dermen desunuberwachten Lernens从聚类分析的形式。
在ZweiGroßeGruppen的聚集算法Lassen Sich Minteilen:
- Das harte群集,bei dem jder Datenpunkt ausschließlich zu einem群集gehört, wie z. B. die beliebtek-Means-Methode。
- Das Weiche Clustering,Bei Dem Jeder DateNpunkt Zu Mehr als einem集群Gehörenkann,wie z。B. Bei derGaußschenPerteilungskurve。Als Beispiele Seien Phoneme在Der Sprache Genannt,Die Als Kombination Aus Mehreren Grundlauten ModelliertWerdenkönnen,Sowie Gene,Die AN A Mehreren Biologischen Prozessen Beteiligt SeinKönnen。

Das K-Persion-ClusteringRepräsentiertGruppen Durch Ihren Schwerpunkt - Den Durchschnitt der Einzelnen Elemente,Dargesellt Durch Decen Decred Oben。
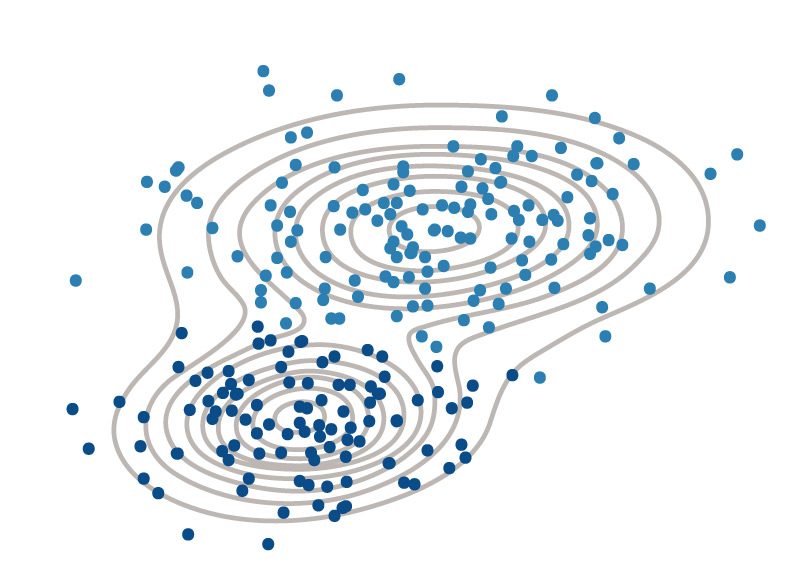
Die Gaußsche Verteilungskurve, Die Wahrscheinlichkeiten für Die Zugehörigkeit zu clusterzuweist和Die Stärke der联合麻省verschiedenen clusterdarstellt。
在einer Vielzahl von Domänen和Anwendungen eingesett的聚类分析中,um Muster and Sequenzen zu identifiieren:
- 簇können在Datenkomprimierungsverfahren die Daten anstelle des Rohsignals darstellen。
- 聚类在分割算法中的应用。
- 在生物信息学中发现的遗传学聚类和序列分析。
聚类技术我们可以使用以下方法:Ähnlichkeit zwischen gelabelten und ungelabelten Daten beim teilüberwachten Lernen(半监督学习)herzustellen,我们可以使用以下方法建立模型:最小的gelabelten Daten erstellt werden und dazu verwendet werden, den ursprünglich ungelabelten Daten Label zuzuweisen。Im Gegensatz dazu bezieht das teilüberwachte Clustering verfügbare Informationen über die Clusterin den Clustering- prozess ein, so zum Beispiel, wenn bekannt ist, dass eige Beobachtungen zum selben Cluster gehören, oder wenn mehrere Cluster mit einer bgebnisvarilen assoziiert werden。
MATLAB®unterstützt viele gängige Algorithmen zur clusteranalysis:
- Hierarchisches集群Erzeugt Eine Mehrstufige Hierarchie von Clustern,Indem ES Einen Clusterbaum Etersellt。
- k-Means-ClusteringTebilt Laten在unterschiedlichek-Cluster Basierend AUF DEM Abstand Zum Schwerpunkt欧洲群群AUF。
- GaußschePerteilungskurve.聚类是一种多变量正常的聚类。
- 双拟杆菌räumliches聚类(auch als DBSCAN bekannt)gruppiert Punkte, die nahe beieinander liegen, in Bereichen mit hoher Dichte and behält dabei Ausreißer in Regionen mit geringer Dichte im Blick。我很相信我的看法。
- Selbstorganisierende卡特Verwenden Neuronale Netze,Die Die Topologie und Verteilung der Daten Erlernen。
- 谱聚类überträgt die Eingangsdaten in eine graphenbasierte Darstellung, in der die Cluster deutlicher voneinander getrennt sind als im ursprünglichen Merkmalsraum。我们的聚类可以在geschätzt werden的本征图中找到。
Wesentliche Punkte.
- De DermentanAnalyse WirdHäufig在Der Proplorativen Datenanalyse,Zur Erkennung von Anomalien und Segmentierung Sowie Als VorverarbeiTungFürÜberwachtesLernenEingesetzt。
- k- 梅斯 - 聚类sowie hierarchisches聚类bleiben weiterhin gefragt,aberfürnichtkonvexe formen sind fortbeschrittenere technen wie dbscan und spectral clustering erforderlich。
- Weitere unüberwachte Methoden, die zur Erkennung von Gruppierungen in Daten verwendet werden können, sind Verfahren zur Dimensionalitätsreduktion and as Feature Ranking。