特征选择是一种维度减少技术,可选择具有在建模一组数据的建模中提供最佳预测电源的特征(预测变量)的子集。
功能选择可用于:
- 防止过度装备:避免使用过多数量的特征建模,这些功能更容易对学习的特定培训示例更容易受到影响
- 降低模型尺寸:通过高维数据提高计算性能或准备模型,以便存储器可能有限。
- 提高可解释性:使用较少的特性,这可能有助于识别那些影响模型行为的特性
特征选择有几种常见方法。
迭代地更改功能设置以优化性能或损耗
逐步回归顺序地添加或删除功能,直到预测没有改善。它与线性回归或广义线性回归算法一起使用。同样,SAD.屏幕特征选择建立一个功能集,直到精度(或自定义性能测量)停止改进。
基于内在特征的等级特征
这些方法估算了特征的排名,这又可以用于选择最大排名的特征。最小冗余最大相关性(MRMR)找到功能最大化功能和响应变量之间的相互信息,并最大限度地减少特征本身之间的相互信息。相关方法根据Laplacian评分的等级特征或使用单个特征是否与响应独立以确定特征重要性的统计测试。
邻里分量分析(NCA)和Relieff
这些方法通过基于成对距离和导致错误分类结果的惩罚预测器来最大化预测精度来确定特征权重。
学习特征重要性以及模型
一些有监督的机器学习算法在训练过程中估计特征的重要性。在训练完成后,这些估计可以用来对特征进行排序。具有内置特征选择的模型包括线性支持向量机、增强决策树及其集合(随机森林)和广义线性模型。同样,在套索正则化收缩估计器在训练期间将冗余特征的权重(系数)降低到零。
马铃薯®万博1manbetx支持以下功能选择方法:
| 算法 | 训练 | 类型的模型 | 精度 | 警告 |
|---|---|---|---|---|
| NCA. | 温和的 | 更好的基于距离的模型 | 高 | 需要手动调整正则化lambda |
| MRMR. | 快速地 | 任何 | 高 | 只对分类 |
| refieff | 温和的 | 更好的基于距离的模型 | 中等的 | 无法区分相关预测器 |
| 顺序 | 减缓 | 任何 | 高 | 并没有对所有功能进行排名 |
| F试验 | 快速地 | 任何 | 中等的 | 回归。无法区分相关预测器。 |
| Chi-Square | 快速地 | 任何 | 中等的 | 进行分类。无法区分相关预测器。 |
作为特征选择的一种替代方法,特征转换技术将现有特征转换为新的特征(预测变量),并去掉描述性较弱的特征。特征变换方法包括:
有关使用MATLAB的功能选择的更多信息,包括机器学习,回归和转换,请参阅统计和机器学习工具箱™。
要点
- 特征选择是提高模型性能的先进技术(特别是在高维数据上),提高解释性,减少尺寸。
- 首先考虑具有“内置”功能选择的模型之一。否则MRMR实际上适用于分类。
例子
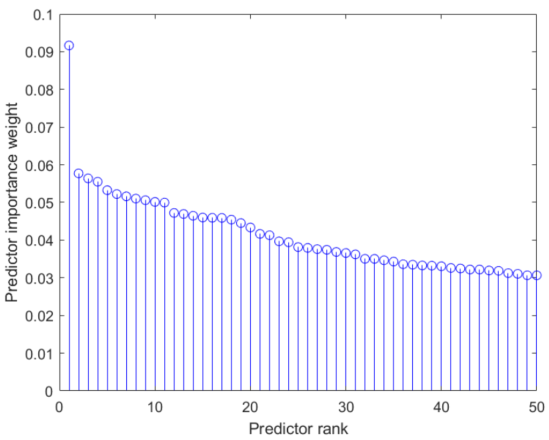
功能选择可以帮助选择通过应用小波散射自动生成的数百个功能的合理子集。下图显示了通过应用MATLAB函数获得的前50个功能的排名fscmrmr从人类活动传感器数据自动生成小波特征。