FSCNCA
使用邻域分量分析的特征选择进行分类
描述
例子
使用NCA检测数据中的相关功能以进行分类
生成响应变量取决于第3个,第9和第15个预测器的玩具数据。
RNG(0,“旋风”);重复性的%n = 100;x = rand(n,20);y = -ones(n,1);Y(x(:,3)。* x(:,9)./ x(:,15)<0.4)= 1;
拟合邻域成分分析模型进行分类。
mdl = fscnca(x,y,'求解',“sgd”,'verbose',1);
o调整初始学习速率:NumTuning韵= 20,TUNINGSUSESEIZE = 100 | =============================================== ||调整|调谐子集|学习||磨练|有趣的价值|率|| =============================================== | 1 | -3.755936e-01 | 2.000000e-01 | | 2 | -3.950971e-01 | 4.000000e-01 | | 3 | -4.311848e-01 | 8.000000e-01 | | 4 | -4.903195e-01 | 1.600000e+00 | | 5 | -5.630190e-01 | 3.200000e+00 | | 6 | -6.166993e-01 | 6.400000e+00 | | 7 | -6.255669e-01 | 1.280000e+01 | | 8 | -6.255669e-01 | 1.280000e+01 | | 9 | -6.255669e-01 | 1.280000e+01 | | 10 | -6.255669e-01 | 1.280000e+01 | | 11 | -6.255669e-01 | 1.280000e+01 | | 12 | -6.255669e-01 | 1.280000e+01 | | 13 | -6.255669e-01 | 1.280000e+01 | | 14 | -6.279210e-01 | 2.560000e+01 | | 15 | -6.279210e-01 | 2.560000e+01 | | 16 | -6.279210e-01 | 2.560000e+01 | | 17 | -6.279210e-01 | 2.560000e+01 | | 18 | -6.279210e-01 | 2.560000e+01 | | 19 | -6.279210e-01 | 2.560000e+01 | | 20 | -6.279210e-01 | 2.560000e+01 | o Solver = SGD, MiniBatchSize = 10, PassLimit = 5 |==========================================================================================| | PASS | ITER | AVG MINIBATCH | AVG MINIBATCH | NORM STEP | LEARNING | | | | FUN VALUE | NORM GRAD | | RATE | |==========================================================================================| | 0 | 9 | -5.658450e-01 | 4.492407e-02 | 9.290605e-01 | 2.560000e+01 | | 1 | 19 | -6.131382e-01 | 4.923625e-02 | 7.421541e-01 | 1.280000e+01 | | 2 | 29 | -6.225056e-01 | 3.738784e-02 | 3.277588e-01 | 8.533333e+00 | | 3 | 39 | -6.233366e-01 | 4.947901e-02 | 5.431133e-01 | 6.400000e+00 | | 4 | 49 | -6.238576e-01 | 3.445763e-02 | 2.946188e-01 | 5.120000e+00 | Two norm of the final step = 2.946e-01 Relative two norm of the final step = 6.588e-02, TolX = 1.000e-06 EXIT: Iteration or pass limit reached.
绘制选定的特征。不相关特征的权值应该接近于零。
图()绘图(mdl.featureweights,“罗”) 网格在Xlabel('特征索引')ylabel('特征重量')
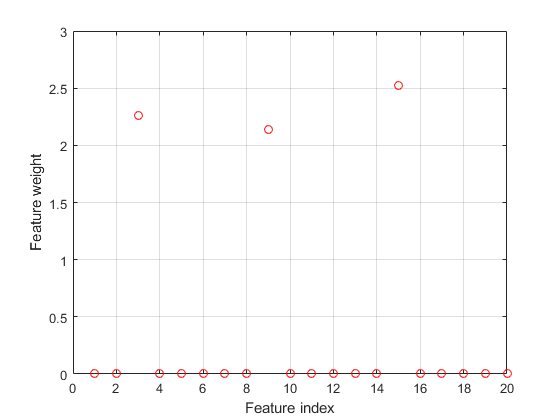
FSCNCA正确检测相关功能。
确定分类的相关功能
加载样本数据
加载卵巢癌;谁是
名称大小字节类属性grp 216x1 25056 cell obs 216x4000 3456000 single
该示例使用使用WCX2蛋白质阵列产生的高分辨率卵巢癌数据集。在某些预处理步骤之后,数据集具有两个变量:obs.和GRP..这obs.变量由4000个功能组成216个观察。每个元素GRP.定义相应行的组obs.属于。
将数据划分为培训和测试集
采用CVPartition.将数据划分为大小160的训练集和大小56的测试集。训练集和测试集都具有大致相同的组比例GRP..
RNG(1);重复性的%本量利= cvpartition (grp,'坚持',56)
CVP =保持交叉验证分区NumObServations:216 NumTestSets:1列塔:160 Testsize:56
奥林匹克广播服务公司(Xtrain = cvp.training:);ytrain = grp (cvp.training:);奥林匹克广播服务公司(Xtest = cvp.test:);欧美= grp (cvp.test:);
确定是否需要特征选择
计算泛化误差而不拟合。
NCA = FSCNCA(XTrain,Ytrain,'fitmethod','没有任何');L =损失(nca, Xtest欧美)
L = 0.0893.
此选项计算使用初始特征权重(在这种情况下提供默认要素权重)的邻域分量分析(NCA)特征选择模型的泛化误差FSCNCA.
没有正则化参数的拟合NCA(Lambda = 0)
NCA = FSCNCA(XTrain,Ytrain,'fitmethod','精确的',“λ”,0,......'求解',“sgd”,'标准化',真正的);L =损失(nca, Xtest欧美)
L = 0.0714.
损失价值的改善表明,特征选择是一个好主意。调整 值通常会改善结果。
使用五倍交叉验证调整NCA的正则化参数
调整 意味着找到 值产生最小分类损失。调 使用交叉验证:
1.将培训数据分为五个折叠,提取验证数(测试)集。每折,CVPartition.将四分之五的数据分配为培训集,以及作为测试集的第五个数据。
cvp = cvpartition(Ytrain,'kfold'5);numvalidsets = cvp.numtestsets;
分配 值并创建一个数组以存储丢失函数值。
n =长度(YTrain);lambdavals = linspace(0,20,20)/ n;lockvals = zeros(长度(lambdavals),numvalidsets);
2.为每个培训NCA模型 值,使用每个折叠中的训练集。
3.使用NCA模型计算折叠中相应的测试集的分类损耗。记录损失值。
4.对所有的折叠重复这个过程 价值观。
为了i = 1:长度(lambdavals)为了k = 1:numvalidsets X = Xtrain(cvp.training(k),:);y = ytrain (cvp.training (k):);Xvalid = Xtrain (cvp.test (k):);yvalid = ytrain (cvp.test (k):);nca = fscnca (X, y,'fitmethod','精确的',......'求解',“sgd”,“λ”,lambdavals(i),......'iterationlimit',30,'gradienttolerance',1e-4,......'标准化',真正的);lossvals (i (k) =损失(nca, Xvalid yvalid,'损失','classiferror');结尾结尾
计算每个折叠的平均损耗 价值。
Meanloss =卑鄙(损失,2);
绘制平均损失值与 价值观。
图()绘图(Lambdavals,Meanloss,'ro-')Xlabel(“λ”)ylabel(“损失(MSE)”) 网格在
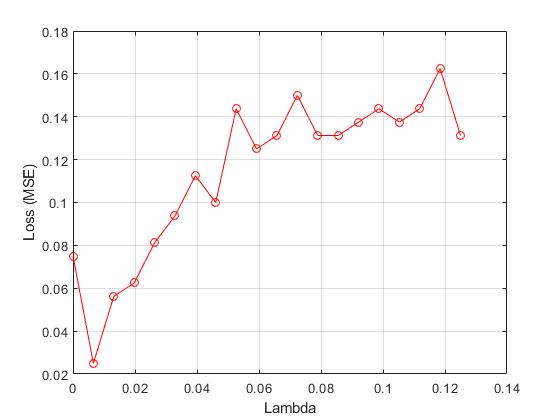
找到与最小平均损耗相对应的最佳Lambda值。
[~, idx] = min (meanloss)%找到索引
Idx = 2
Bestlambda = Lambdavals(IDX)%找到最好的lambda值
Bestlambda = 0.0066.
bestloss = meanloss(idx)
Bestloss = 0.0313
最好地将nca模型应用于所有数据 并绘制特征权重
使用Solver LBFGS并标准化预测值值。
NCA = FSCNCA(XTrain,Ytrain,'fitmethod','精确的','求解',“sgd”,......“λ”,bestlambda,'标准化',真的,'verbose',1);
o调整初始学习速率:NumTuning韵= 20,TUNINGSUSESEIZE = 100 | =============================================== ||调整|调谐子集|学习||磨练|有趣的价值|率|| =============================================== | 1 | 2.403497e+01 | 2.000000e-01 | | 2 | 2.275050e+01 | 4.000000e-01 | | 3 | 2.036845e+01 | 8.000000e-01 | | 4 | 1.627647e+01 | 1.600000e+00 | | 5 | 1.023512e+01 | 3.200000e+00 | | 6 | 3.864283e+00 | 6.400000e+00 | | 7 | 4.743816e-01 | 1.280000e+01 | | 8 | -7.260138e-01 | 2.560000e+01 | | 9 | -7.260138e-01 | 2.560000e+01 | | 10 | -7.260138e-01 | 2.560000e+01 | | 11 | -7.260138e-01 | 2.560000e+01 | | 12 | -7.260138e-01 | 2.560000e+01 | | 13 | -7.260138e-01 | 2.560000e+01 | | 14 | -7.260138e-01 | 2.560000e+01 | | 15 | -7.260138e-01 | 2.560000e+01 | | 16 | -7.260138e-01 | 2.560000e+01 | | 17 | -7.260138e-01 | 2.560000e+01 | | 18 | -7.260138e-01 | 2.560000e+01 | | 19 | -7.260138e-01 | 2.560000e+01 | | 20 | -7.260138e-01 | 2.560000e+01 | o Solver = SGD, MiniBatchSize = 10, PassLimit = 5 |==========================================================================================| | PASS | ITER | AVG MINIBATCH | AVG MINIBATCH | NORM STEP | LEARNING | | | | FUN VALUE | NORM GRAD | | RATE | |==========================================================================================| | 0 | 9 | 4.016078e+00 | 2.835465e-02 | 5.395984e+00 | 2.560000e+01 | | 1 | 19 | -6.726156e-01 | 6.111354e-02 | 5.021138e-01 | 1.280000e+01 | | 1 | 29 | -8.316555e-01 | 4.024186e-02 | 1.196031e+00 | 1.280000e+01 | | 2 | 39 | -8.838656e-01 | 2.333416e-02 | 1.225834e-01 | 8.533333e+00 | | 3 | 49 | -8.669034e-01 | 3.413162e-02 | 3.421902e-01 | 6.400000e+00 | | 3 | 59 | -8.906936e-01 | 1.946295e-02 | 2.232511e-01 | 6.400000e+00 | | 4 | 69 | -8.778630e-01 | 3.561290e-02 | 3.290645e-01 | 5.120000e+00 | | 4 | 79 | -8.857135e-01 | 2.516638e-02 | 3.902979e-01 | 5.120000e+00 | Two norm of the final step = 3.903e-01 Relative two norm of the final step = 6.171e-03, TolX = 1.000e-06 EXIT: Iteration or pass limit reached.
绘制特征权重。
图()绘图(nca.featurewuights,“罗”)Xlabel('特征索引')ylabel('特征重量') 网格在
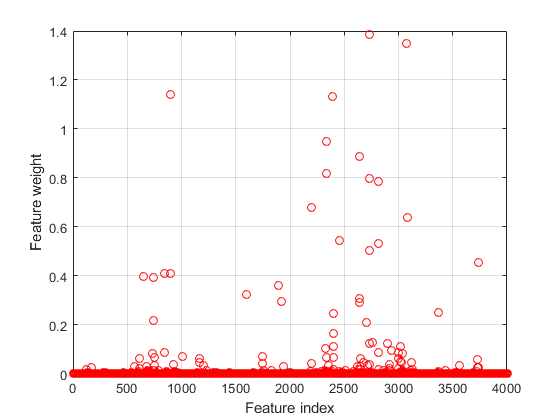
使用要素权重和相对阈值选择功能。
tol = 0.02;selidx = find(nca.featureweights> tol * max(1,max(nca.featureweights)))
Selidx =72×1565 611 654 681 737 743 744 750 754 839⋮
使用测试集计算分类丢失。
L =损失(nca, Xtest欧美)
L = 0.0179.
使用所选功能进行分类观察
从训练数据中提取具有大于0的特征权重的功能。
功能= XTrain(:,SELIDX);
使用所选功能应用万博1manbetx支持向量机分类器到减少的训练集。
svmmdl = fitcsvm(特征,ytrain);
评估训练有素的分类器对未用于选择特征的测试数据的准确性。
L =损耗(SVMMDL,XTEST(:,SELIDX),YTEST)
l =单身的0
输入参数
输出参数
您还可以从以下列表中选择一个网站:
