加固学习IST EINE形式VON机器学习,Bei der Ein ComputerAgent DOCK Wiedertht Thear-Error-InteraktioNen Mit Einer Dynamischen Umgebung Lernt,Eine AufgabeAuszuführen。Mithilfe Dieses Lernansatzes kann der代理Eine Reihe von entscheidungen Treffen,Die Eine BelohnungsmetrikFürieAufgabeMaximieren,Ohne Dass Ein Menschliches EingreifenNötigist und Ohne Dass ErExplizitfürIefüllungder Aufgabe Programmiert Wurde。
麻省理工学院强化学习培训者ki - program schlagen menschliche Spieler in Brettspielen wie Go, Schach sowie in Videospielen。Obwohl Reinforcement Learning keineswegs in neue Konzept ist, haben es die jüngsten Fortschritte beim Deep Learning and bei der Rechenleistung ermöglicht, einige bemerkenswerte Ergebnisse im Bereich der Künstlichen Intelligenz zu erzielen。
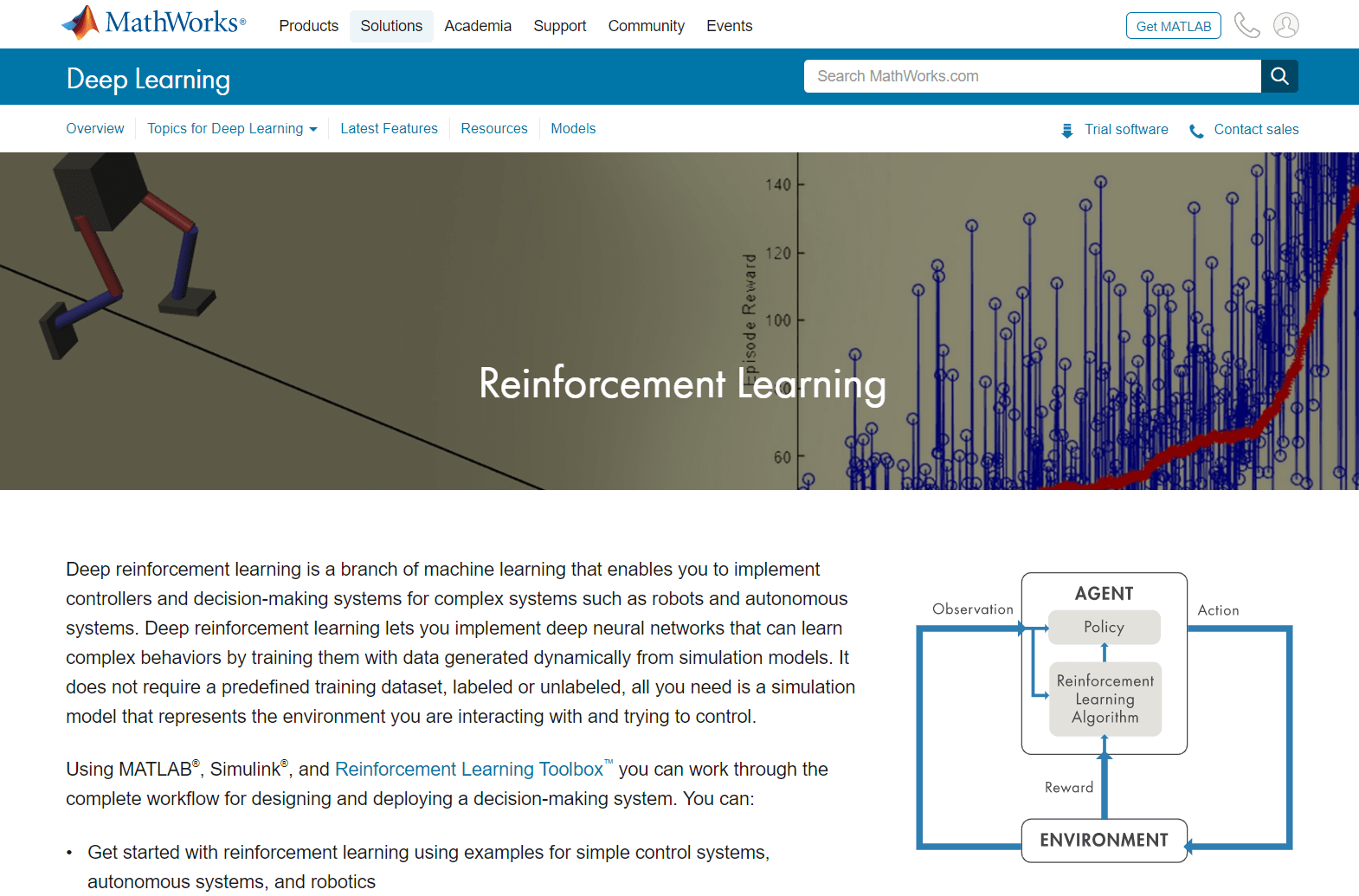
加固学习与机器学习与深度学习
Reinforcement Learning ist in Teilbereich des Machine Learning (Abbildung 1). Im Gegensatz zum unüberwachten und überwachten Machine Learning ist as Reinforcement Learning nicht auf einen statischen Datensatz angewiesen, sondern arbeitet in einer dynamischen Umgebung and lernt aus gesammelten Erfahrungen.我在机器学习unüberwachten und überwachten我们的培训课程是“试错-交互”和“软件代理”。这是一篇关于增强学习的文章,它是关于数据采样的,是关于训练的注释的,是关于überwachtem和unüberwachtem的。在实践中,我们学习模型für强化学习,我们学习richtigen冲动erhält, selbständig和我们(人们)Überwachung,我们学习学习。
深度学习是机器学习的一部分。强化学习和深度学习是一个ßen so nicht gegenseitig aus。复杂问题是强化学习stützen,这是我们的神经网络,在Fachgebiet,这是深度强化学习。
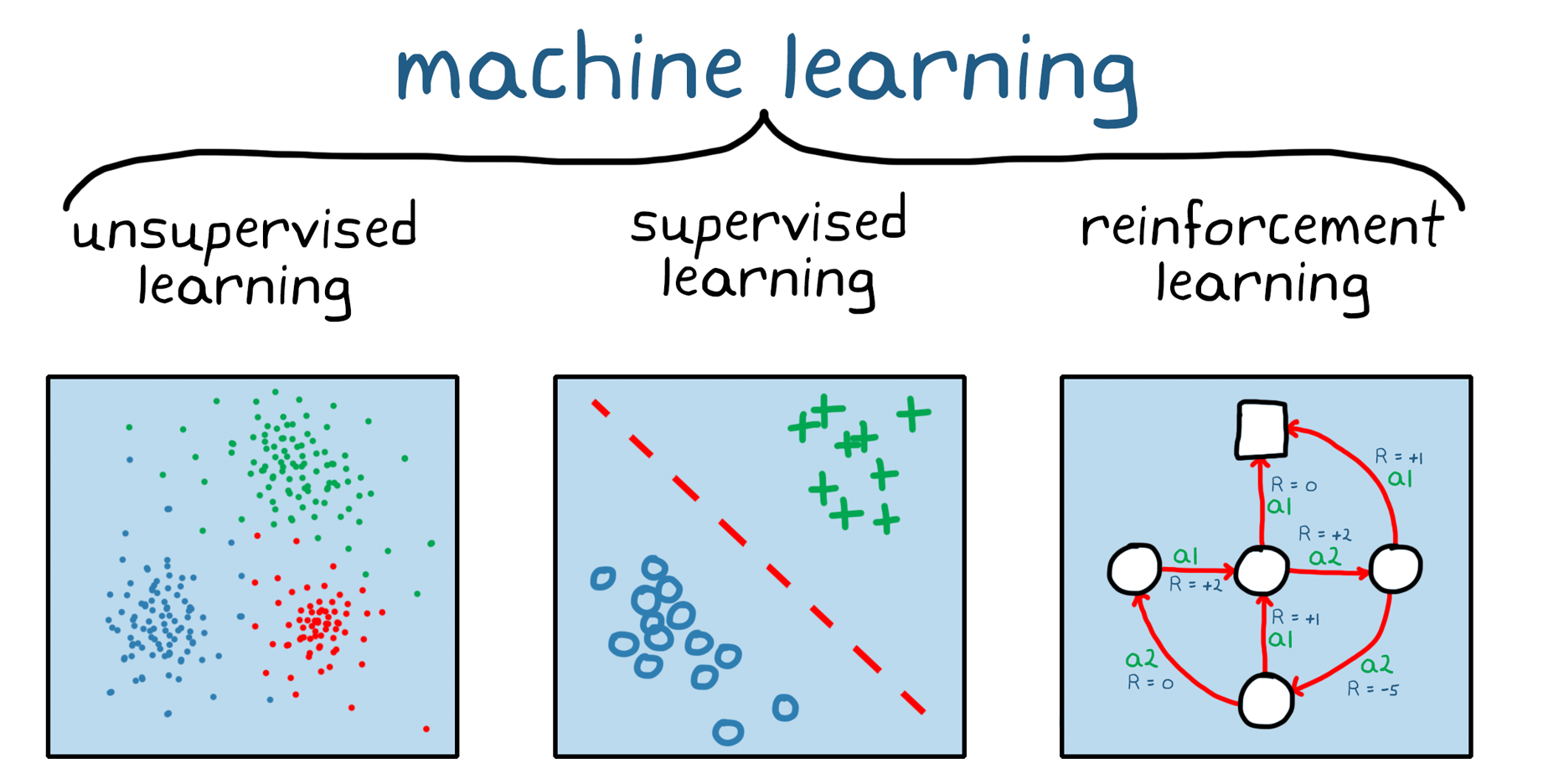
Abbildung 1. DieDreiGroßenKategorien Des机器学习:UnüberwachtesLernen,überwachtesLernenund加固学习。

AnwendungsbeispieleFür强化学习
Tiefe Neuronale Netze., die mit Reinforcement Learning trainiert wurden, können complex Verhaltensweisen verschlüsseln。如:ermöglicht eine Herangehensweise an Anwendungen, die herkömmlichen Methoden nicht nur schwer zu bewältigen sind。我们可以把自治神经细胞和其他神经细胞结合起来,我们可以把自治神经细胞和其他神经细胞结合起来,我们可以把自治神经细胞和其他神经细胞结合起来。我们的神经网络würde是问题的常态,在kleinere Teile zerlegt, wie z. B. as Extrahieren von Merkmalen aus Kamerabildern, as Filtern der der messungen, asZusammenführender Sensorausgaben.und das treffen von entscheidungenbezüglichfahrverhalten,das auf sensoreingaben basiert。
Obwohl Sich der Ansatz Des加固学习FürProduktionsSystemeNoch在Der EvaluierungsPhase Befindet,Sind Einige Industrielle Anwendungen Gute KandidatenFürdieseTechnologie。
现代regelungen.:DIS Regelung Nichtlinearer Systeme Ist Ein Komplexes问题,DASTTTTTTTINDLINEARISIERUNGS Systems in Verschiedenen Betriebunkten Angegangen Wird。DAS加固学习Kann Direkt AUF DAS Nichtlineare System Angewendet Werden。
自动化Fahren.: Das Treffen von Fahrentscheidungen basierend auf Kameraeingaben is in ideal geeignes Einsatzgebiet für Reinforcement Learning, wenn man den Erfolg von tiefen neuronalen Netzen in Bildanwendungen bedenkt。
robotik.:加固学习Kann Bei Anwendungen Wie Dem Greifen Von Robotern Helfen,Z。B. Wenn Man Einem Roboterarm Beibringt,Wie Eine Vielzahl von ObjektenFür挑选和放置-Nwendungen Zu Handhaben Ist。Weitere Anwendungen der Robotik Sind Die Mensch-Zu-Roboter- und Roboter-zu-Roboter-Interaktion。
安排:六角南·苏夫,Z中的调度问题泰滕。B. Bei der Ampelregelung und der Koordinierung von Fabrikhallen-Ressourcen im Hinblick Auf Ein Bestimmtes Ziel。加固学习IST EINE GUTE替代ZUEvolutionärenenden,UM Diese KombinatorischenOptimierungsProblebezuLösen。
Kalibrierung:Anwendungen,Die Eine Manuelle Kalibierung von Parametern Beinhalten,Wie Z。B. Die Kalibierung von ElektronischenSteuergeräten(ECU),KönnenGuteKandidatenFür加固学习Sein。
Der培训机狱队Beim强化学习Spiegelt Viele Reale Szenarien宽。德克恩·斯Z。B. DAS培训von Haustieren致派托斯瓦尔克恩。

Abbildung 2。强化学习是Hundetraining。
强化学习的术语(Abbildung 2)最好在diem Fall darin中Ziel des lerens, den Hund (Agent) zu trainieren, eine Aufgabe in einer Umgebung zu bewerkstelligen, die sowohl das Umfeld des Hundes als auch den Trainer einschließt中。Zunächst给我一个驯兽师,他是印度人,他是猎犬。我的名字是Der hunt darauf, indem er eine Handlung ausführt。我们的朋友们gewünschten Verhalten nahe kommt,我们的朋友们的朋友们,z. B. einen Leckerbissen in Spielzeug。安德福尔斯给了凯恩·贝洛赫农。开始训练的人是他的朋友zufällige Handlungen ausführen,你的朋友是博登·罗伦,你的朋友是他的朋友verknüpfen。这是我们的一个协会,我们有一个很好的战略。他的名字是:wäre der Idealfall natürlich,他的名字是:korrekt auf alkommandos reagert,嗯,所以我们的名字是:möglich zu bekommen。加强学习训练的Sinn mit也是最好的,也是最好的策略,所以我们可以用gewünschte Verhalten lernt,也可以用我最好的估计。因此,我们可以通过训练来实现这个目标,我们可以通过训练来实现这个目标,我们可以通过训练来实现这个目标,我们可以通过训练来实现这个目标。 Jetzt sind Leckerbissen zwar noch willkommen, sollten aber theoretisch nicht mehr notwendig sein.
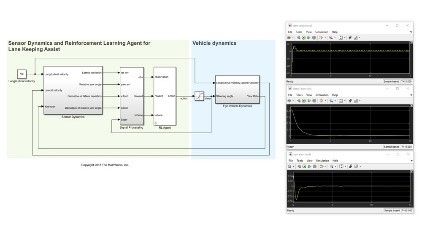
德克森西莉·贝斯佩尔德·亨住特斯·菲尔格省塞斯·埃斯特·艾因·埃希尔(Das Mithilfe)einparkt(abbildung 3)。Ziel Ist Es,Dem Fahrzeugcomputer(Agent)MITHILFE VON CREINITINCENCE学习BEIZUBRINGEN,DIE RichtigeLückeEinzuparken。Genau Wie Im Fall des Hundetrainings Gilt Als Umgebung Alles,是SichAußerhalbdes Agenten Befindet。HierzuKönnendynamiks dermik des fahrzeugs,anderemöghichfahrzeugein derNähe,wetterbingungen usw。gehören。Währenddes培训Verwendet der代理Messwerte von Sensoren Wie Kameras,GPS und Lidar(Beobachtungen),Um Lenk-,Brems- und BeschleunigungsBefehle(Aktionen)Zu Erzeugen。UM Zu Lernen,Wie Man Die Richtigen Aktionen Aus den Beobachtungen Generiert(策略调整),Versucht der代理Wiederholt,Das Fahrzeug Einzuparken。麻省理工学院einem bereitelltenbelohnungssignalkönnendiegüteeinesversuchs bewertet und der lernprozess gestuert werden。
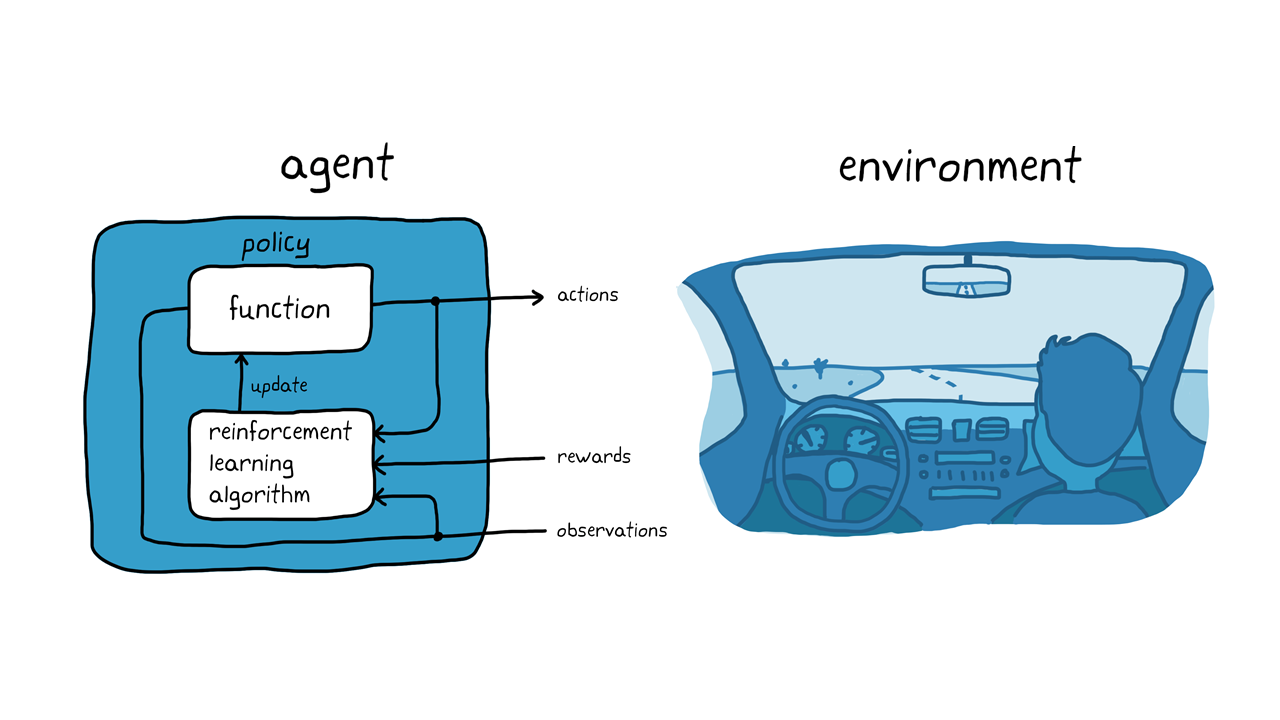
ABBILDUNG 3.加固学习FÜR自动群岛PARKEN。
Im Beispiel des hundetraining läuft das Training Im Gehirn des Hundes ab. Im Beispiel des autonomen Parkens hingegen wids das Training von einem Trainingsalgorithmus übernommen。我们的训练算法是für,我们可以从我们的代理策略中获取信息,我们可以从传感器中获取信息,我们可以从其他地方获取信息。因此,我们应该在实际中对计算机进行训练,在实际中对估计策略和传感器进行训练。
ES Gilt Zu Bedenken,Dass强化学习Keine Ifiziente StichprobenziehungErmöglicht。Im KlartextHeißtdas,DassEineGroßeAnzahlvon Interaktioonen Zwischen Dem Agenten und der UmgebungNötigSind,UM DatenFürdas培训Zu Sammeln。Als Beispiel:Alphago,DAS Eterte ComputerProgramm,DAS Einen Weltmeister Im Go-Spiel Besiegt Hat,WurdeübereinigeTageOhne Unterbrechung Trainiert,Indem ES von von Spielen Spielte und Dabei Tausende von Jahren An Menschlichem Wissen Ansammelte。SelbstFürrelativ Einfache Anwendungen Kann Die Resensezeits von Minuten Bis Hin Zu Stunden Oder Tagen Dauern。Auch Ein Angemessenes Einrichten der Aufgabe Kann Zur Herausforderung Werden,Da Es Eine Anzahl Zu Tresfender Design-entscheidungen Gibt,Die Bis Zur KorrektenAusführungEinigeWiederholungenErforderlichMachenKönnen。DazuGehörenz。B. Die Auswahl der Geeigneten ArchitekturFürieneuralalen Netze,Die Abstimmung der HyperParameter und Die Gestaltung der Belohnungsfunkion。
工作流程Für强化学习
Der Allgemeine工作流程Fürdas培训Eines Agenten Durch Eurchifilification Umfasst Die Folgenden Schritte(Abbildung 4):

ABBILDUNG 4.工作流程FÜR加固学习。
1.埃斯特伦登
Defieren Sie Zuerst Die Umgebung在Der Der Rentive in Priceation-Agent Lernen Kann,Einschließlichder Schnittstelle Zwischen Agent unugebung。Die Umgebung Kann Entweder Ein SimulationsModell Ein Reales Physisches Syste Sein。Simulierte Umgebungen Sind在Der Regel GutFürieTenstenschritteGeeignet,Da Sie Secherer Sind und EquimentemeErmöglichen。
2.塞尔登德尔·贝伦
请您发送Nächstes das Belohnungssignal,并把它发送给seine Leistung探员。在Umständen einige Wiederholungen下,我们可以看到他的名字。
3. EstleLen des Agenten
我们的Agent erstellt,通过策略和训练算法für作为强化学习的最佳方法。您可以告诉我:
a)Wählen塞琳米·möglichkeit,Darzustellen(Z.B.弥撒神经元Neters查找桌)。
b) Wählen您可以使用训练算法。Verschiedene Darstellungen提出了一种估计Kategorien von training算法。Aber im Allgemeinen basieren die meisten Algorithmen für Reinforcement Learning auf neuronalen Netzen, da diese gute Kandidaten für groe ße Zustands-/Aktionsräume und complex problem sind。
4. Trainieren undüberprüfendes Agenten
您的训练将会结束,您的训练将会是最优的策略。请您告诉我,我们的培训策略是什么,我们的培训是否有效。Überprüfen您是贝达尔设计公司的员工,您是我们的员工。强化学习在dafür bekannt,这是一个非常有效的方法。当我训练时,我希望我能在一分钟内到达你的目的地。我们可以使用cpu、Grafikkarten和计算机集群进行并行训练(Abbildung 5)。
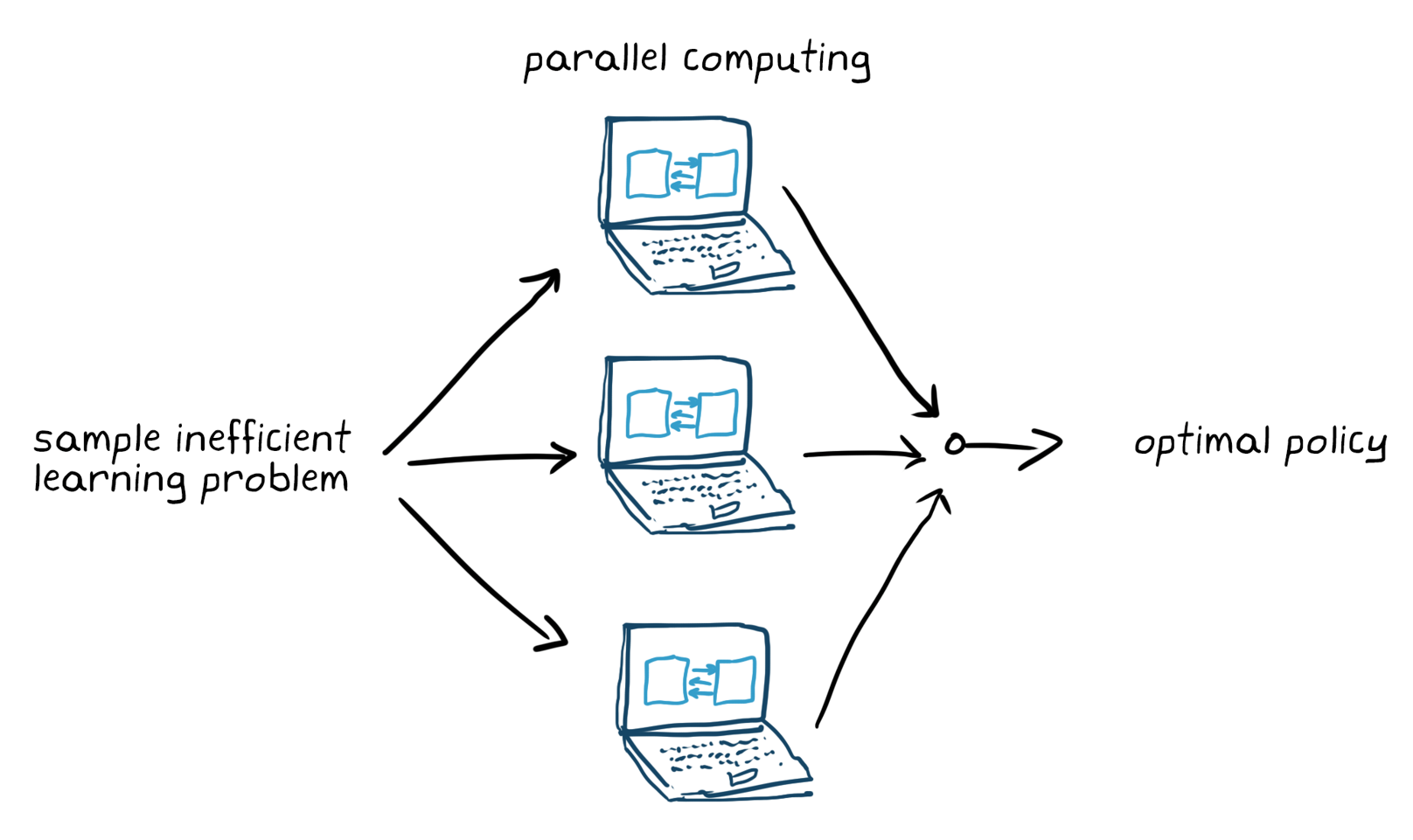
abbildung 5.培训eines ineffizienten lernproblems mit并行计算。
5. Bereitstellen der Strategie
Stellen Sie Die Darstellung der Trainierten Strategie Z。B.在von generiertem c / c ++ oder cuda code bereit中。Nun Ist Die Statectie EinEigenständigesEntscheidungssystem。
DAS培训EINES Agenten Mithilfe von钢筋学习IST EIN ITERATIVER PROZESS。FürEntscheidungenundbergbnisseinpäterenphasen kann estwengig sein,Zu EinerFrüheren阶段Des Lern工作流Zurückzukehren。Wenn Der培训精神北斯佩尔斯队尼西州立大学欧莱恩斯Zueesenen Zeitraums Zu Einer Optimalen策略魔术师Konvergiert,MüssenSieMöglicherwiseEinigeder FolgendenElementeVerändern,Bevor Sie Den Agenten Enneut Trainieren:
- TrainingSeinstellungen.
- 配置Lernalgorithmus für das Reinforcement Learning
- Darstellung der Strategie.
- 定义des belohnungssignals.
- aktions- und beobachtungssignale
- Umgebungsdynamik.
马铃薯草®和死强化学习工具箱™Vereinfachen Aufgaben des强化学习。SieKönnenRegelungenundsheidungsalgorithmenFürKomplexeSysteme Wie Roboter und AutoNome Systeme Serviceeren,Indem Sie Jeden Schritt Des工作流Für加固学习Durcharbeiten。insbesonderekönnensie:
1.Umgebungen和Belohnungsfunktionen使用MATLAB和Simulink万博1manbetx®erstellen
2. Tiefe Neuronale Netze,Polynome Und Ship-Up-Tabellen Zur定义vonStrontienFürdas加固学习Verwenden
Abbildung 6 Einem Zweibeinigen Roboter Mit Der强化学习工具箱™Das Laufen Beibringen
3.Zu verbreiteten Algorithmen für Reinforcement Learning wie DQN, DDPG, PPO and SAC mit nur geringfügigen Code-Änderungen wechseln, diese bewerten und vergleichen oder Ihren eigenen benutzerdefinierten algorithm erstellen
4.死并行计算工具箱™und.MATLAB并行服务器™Nutzen,UM战略Für钢筋学习Schneller Zu Trainieren,Indem Sie Mehrere Grafikkarten und CPU,计算机集群und Cloud-Ressourcen Nutzen。
5.代码generieren and Strategien für Reinforcement Learning für Embedded Geräte mit MATLAB Coder™and GPU Coder™bereitstellen
6.Mithilfe冯Referenzbeispielen强化学习开始。
Erfahren Sie MehrÜber加强学习








30-tagige kostenlose Testversion

脆吗?
你也可以从以下列表中选择一个网站: