GPU编码器
Generung Von Cuda-CodeFürnvidia-Grafikkarten

GPU编码器™Generiert Aus Matlab®代码和仿真软件万博1manbetx®-Modellen Optimierten Cuda.®代码。cuda - kernel zur Parallelisierung von Teilen Ihrer深度学习,嵌入式视觉和信号算法Für Hochleistungsanwendungen最优通用代码NVIDIA®CUDA-Bibliotheken wie TensorRT™,cuDNN, cuFFT, cuSolver和cuBLAS auf。一般代码lässt的形式von Quellcode和statischen oder dynamischen Bibliotheken在Ihr项目的einbinden和kann für桌面,服务器和在NVIDIA Jetson™,NVIDIA DRIVE™和andere platform eingebettete Grafikprozessoren kompiliert werden。您的地址是:können den generierten CUDA-Code in MATLAB verwenden, um deep - learning netze and andere berechnungsintensive anteilires algorithm zu beschleunigen。Mit GPU编码器lässt sich außerdem selbst geschriebener CUDA-Code in Ihre algorithm and den neu generierten Code integreren。
Bei Verwendung von GPU编码器MIT嵌入式编码器®Kann Das Numerische Verhalten des Generierten代码Durch Sil-und Pil-Tests(软件 - 循环BZW.处理器 - 循环)GeprüftWerden。
现在beginnen:

Kostenlose白皮书
CUDA-Codegenerierung来自MATLAB
Lizenzgebührenfreie Bereitstellung von Algorithmen
Kompilieren Sie Ihren Generierten代码undführenis ihn aufgängigennvidia-gpus aus - von DesktopsystemenÜberrechenzentren bis hin zu嵌入式硬件。Der Generierte代码ISTLizenzgebührenfrei - Stellen Sie Ihn在Kommerziellen Anwendungen Ihren Kunden Kostenlos ZurVerfügung。

埃尔昆登画廊(Bilder)
Erfolgsberichte zu GPU编码器
您是我们的工程师,我们的图形处理器代码是最常用的cuda代码für。

空中客车Testet原型AUF NVIDIA Jetson TX2 Zur Automatischen Erkennung von Fehlern。
Codegenerierung für unterstützte工具箱和Funktionen
GPU编码器通用代码großen Auswahl von MATLAB-Sprachfunktionen, die von Entwicklungsingenieuren zum Entwurf von Algorithmen als Komponenten größerer Systeme verwendet werden。在MATLAB和zugehörigen工具箱中使用390操作和Funktionen。

Matlab-Sprach- und Toolbox-UnterstützungFürieDodegenerierung。
Einbinden von遗留 - 代码
Mithilfe von Optionen zur集成von vorhandenem代码können Sie bewährten oderstark优化cuda代码zum测试在matlab算法集成和denselben cuda代码anschliessend ausneu aufrufen。

Einbinden von Vorhandenem CUDA代码在Neu Erzeugten代码。
Ausführung von Simulationen和Generierung von optimiertem Code für NVIDIA gpu
Bei Verwendung Mit 万博1manbetxSimulink Coder™Beschleunigt GPU编码器BerechnungsInceTeile von Matlab-Funktionsblöcken在Ihren Simulink-Modellen Auf Nvidia-GPUS。Aus Dem 万博1manbetxSimulink-ModellLässtSichOptimierter CUDA-Code Generieren und In Ihrer ZielanwendungFürdennvidia-Grafikprozessor Bereitstellen。

万博1manbetxSimulink-Modell Einer在Einer GPUAusgeführtenSobel-Kantenerkennung。
BereitStellung von端到端almorithmenfür深深学习
Verwenden verschiedenster trainierter Deep Learning- netze (einschließlich ResNet-50, SegNet和LSTM) aus der Deep Learning Toolbox™in Ihrem simu万博1manbetxlink - modelell and Bereitstellen in nvidia - gpu。代码für die Vor and Nachverarbeitung kann zusammen mit den den trainierten Netzen erzegt werden, um vollständige算法。

Signalprotokollierung, Parameterjustierung和numerische verify ierung des Code-Verhaltens
Zusammen dem Simu万博1manbetxlink编码器和GPU编码器在Echtzeit mit Simulationen外模信号原kollien和参数justieren。Ausführen von SIL- und PIL-Tests(软件在环bzw。处理器在环)麻省理工学院嵌入式编码器和GPU编码器,zur numerischen Bestätigung, dass generierte代码das Simulationsverhalten erfüllt。

MIT DEM外部Modus在Simulink Si万博1manbetxgnale Protokollieren und参数justieren。
BereitStellung von端到端almorithmenfür深深学习
Bereitstellung verschiedenster trainierter Deep Learning- netze (einschließlich ResNet-50, SegNet和LSTM) aus der Deep Learning Toolbox™in nvidia - gpu。深度学习-深度学习-深度学习für您的邮件地址。代码für die Vor and Nachverarbeitung kann zusammen mit den den trainierten Netzen erzegt werden, um vollständige算法。
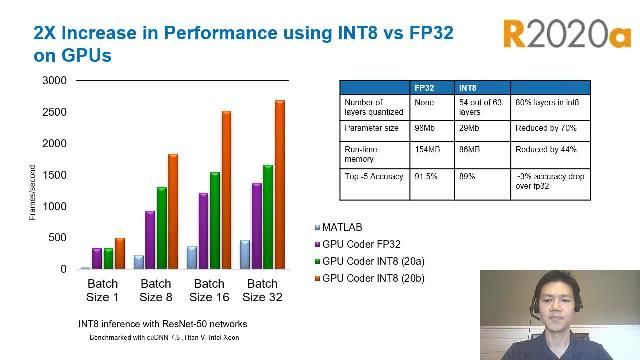
最优代码für Inferenz
Verglichen Mit Anderen Deep Sheath-LösungenErzeugtGPU编码器代码MIT Kleinerem Speicherbedarf,Da Nur DerFürDieferenz Mit Ihrem Konkreten算法Benötigte代码Generiert Wird。der generierte code ruft optimierte bibliotheken wie tensorrt und cudnn auf。

Einzelbild-Inflerzenz MIT VGG-16在Einer Titan V-GPU Mittels Cudnn。
ZusätzlicheOptimierung Mit Tensorrt
Generieren Von Code Zur Integration Mit Nvidia Tensorrt,EinerHochleistungsfähigenOptimierungs- unfzeitumgebungFür深入学习。Wenn Sie Dabei Int8-奥德FP16-DatentyPen Nutzen,Erzielen SieZusätzlicheLeistungssteigerungenGegenüberdmandardmäßigenfp32-demp32-demyp。

Höhere Ausführungsgeschwindigkeit mit TensorRT和int8 - datentpen。
Quantisierung von深入学习
Quantisieren Sie Ihr深入学习 - Netz,UM Den Speicherbedarf Zu Senken und Die Infrenzenzleistung Zu Steigern。Analysieren und Visualisieren Sie Mit Der Dead Network Quanterizer-App Den Kompromiss ZwischenHöhererLeistungund Informenz-Genauigkeit。
最小的程序Datenübertragung zwischen CPU、GPU和最优程序
GPU编码器analysiert,Identifiziert und PartitionIert自动机构,Uhn Endeder在Der CPU Oder Der GPUAuszuführen中。Dadurch Verringert Sich Auch Die Menge Menge Datenkopien Zwischen CPU Und GPU。Verwenden Sie Profiling-Tools,Um Andere PotenzielleEngpässeZuErmitteln。

Profilberichte ZurElmittlungMöglicherGenpässe。
Aufruf优化器Bibliotheken.
麻省理工学院GPU编码器转发器代码Ruft OptimiERTE NVIDIA CUDA-BIBLIOTHEKEN WIE TENTORT,CUDNN,CUSOLVER,CUFFT,CUBLAS und推力AUF。Aus Matlab Toolbox-FunktioNengegerter代码Wird NachMöglichkeitinfer Auf Optimierte Bibliotheken Abgebildet。

Generierter Code, der Funktionen in der optimierten CUDA-Bibliothek cuFFT aufruft。
Verwendung von Entwicklungsvorlagen Zur Weiteren Beschleunigung
Entwicklungsvorlagen Wie Stencil-Verarbeitung Greifen Auf Gemeinsamen Speicher Zu,UM Bandbreite Zu Sparen。Sie Werden Automatisch Bei Verwendung Bestimmter Funktionen Wie Faltung Angewandt。MIT Bestimmten Paradigmen Lassen Sie Sich Auch Manuell Aufrufen。

DieonewicklungsvorlageFürStencen-Verarbeitung。
原型AUF DEN NVIDIA JETSON-und DREV-PLATTFORMEN
NVIDIA的驱动平台dem GPU编码器支持包für NVIDIA-GPU。万博1manbetx

NVIDIA jetson平台的原型。
Zugriff AufPeripheriegeräteundisherenübermatlab und generierten代码
Fernkommunikation Mit Dem Nvidia-Zielsystem von Matlab,UM日期von网络摄像头und AnderenUnterstütztenfilipheregerätenzurysten prototypenentwicklung abzurufen。Stellen Sie Ihren算法在Kombination Mit Perizimenieschnittstellen-Code Auf Einem Board ZurEigenständigenausführungbereit。

Zugriff AufPeripheriegeräteundscaperenübermatlab und generierten代码。
Übergang vom zur样机生产
Verwenden SIE GPU编码器MIT嵌入式编码器,UM Ihren Matlab-Code Interaktiv And Parallel Mit Generiertem CUDA-Code Zu Verfolgen。ÜberprüfenSieDas Numerische Verhalten Des Generierten Codes Bei derAusführungAUF硬件Durch Sil-(循环)und Pil-Tests(循环处理器 - 循环)。

InteraktiverrückverfolgarkeitsberichtMithilfe von GPU编码器MIT嵌入式编码器。
Beschleunigung von algorimen mit gpus在matlab中
如您所提供的cuda代码和matlab代码都是一样的Ausführung我是德国人。我用的是matlab代码。mittel Profiling von generierten mexfunktionen können您Engpässe识别和优化。
Beschleunigung von 万博1manbetxSimulink-Simulateen Mittels Nvidia-GPU
Bei Verwendung Mit 万博1manbetxSimulink Coder Beschleunigt GPU编码器BerechnungsInceTeile von Matlab功能-Blöcken在Ihren Simulink-Modellen Auf Nvidia-GPUS。
万博1manbet万博1manbetxxSimulink-support.
nvidia图形处理器的Simulink-Modellen万博1manbetx
万博1manbet万博1manbetxxSimulink-Support für深度学习:
在Simulink-Modellen auf nvidia - gpu的深度学习netzen万博1manbetx
坚持不懈的variablen
Erzeugen von Persistententem Speicher Auf der GPU
小波工具箱的代码generierung
代码für FFT-basierte FIR-Filterung和kurzeit - fourier transform mit dwt, dwt2, modwt和modwtmra generieren
深度学习
代码für benutzerdefinierte Schichten generieren
多输入 - Netze
代码FÜRNETZEMITMEHRERENEingängenGENIEREN
LSTM-Netze(长短时记忆)
代码FÜRFALTUNGS-LSTM und Netzwerkaktivierungen Generieren
E / A-Block-Bibliothek毛皮NVIDIA-Hardware
Zugriff AUF NVIDIA-Hardware-PeripherieGeräteMitDem GPU编码器支持包FÜR万博1manbetxNVIDIA-GPU
在窝里versionshinweisen.Finden Sie Einzelheiten Zu Jedem Dieser Merkmale und den entsprechenden funktionen。
