rlDQNAgent
深度q -网络强化学习代理
描述
深度q -网络(DQN)算法是一种无模型、在线、非策略的强化学习方法。DQN代理是一种基于价值的强化学习代理,它训练批评者来估计回报或未来的回报。DQN是q学习的一种变体,它只在离散的动作空间内运行。
有关更多信息,深Q-Network代理.有关不同类型的强化学习代理的更多信息,请参见强化学习代理.
创建
语法
描述
从观察和操作规范中创建代理
代理= rlDQNAgent (observationInfo,actionInfo)observationInfo以及动作规范actionInfo.
代理= rlDQNAgent (observationInfo,actionInfo,initOpts)initOpts对象。有关初始化选项的更多信息,请参见rlAgentInitializationOptions.
从评论家表示创建代理
代理= rlDQNAgent (评论家)
指定代理选项
代理= rlDQNAgent (评论家,agentOptions)AgentOptions财产agentOptions输入参数。在前面语法中的任何输入参数之后使用此语法。
输入参数
属性
对象的功能
例子
从观察和操作规范创建DQN代理
创造一个具有离散动作空间的环境,并获得其观察和动作规范。对于本示例,请加载示例中使用的环境使用深度网络设计器创建代理和使用图像观察训练.这个环境有两个观测值:一个50乘50的灰度图像和一个标量(钟摆的角速度)。这个动作是一个标量,有五个可能的元素(一个扭矩是-2, -1,0,1,或2Nm适用于摆动杆)。
加载预定义环境env = rlPredefinedEnv (“SimplePendulumWithImage-Discrete”);%获得观察和行动规范obsInfo = getObservationInfo (env);actInfo = getActionInfo (env);
代理创建函数随机初始化参与者和批评者网络。您可以通过固定随机生成器的种子来确保重现性。为此,取消下面一行的注释。
% rng (0)
创建一个深度q网络代理,从环境观察和行动规范。
代理= rlDQNAgent (obsInfo actInfo);
要检查你的代理,使用getAction从随机观察中返回动作。
getAction(代理,{兰特(obsInfo (1) .Dimension),兰德(obsInfo (2) .Dimension)})
ans = 1
现在可以在环境中测试和培训代理。
使用初始化选项创建DQN代理
创造一个具有离散动作空间的环境,并获得其观察和动作规范。对于本示例,请加载示例中使用的环境使用深度网络设计器创建代理和使用图像观察训练.这个环境有两个观测值:一个50乘50的灰度图像和一个标量(钟摆的角速度)。这个动作是一个标量,有五个可能的元素(一个扭矩是-2, -1,0,1,或2Nm适用于摆动杆)。
加载预定义环境env = rlPredefinedEnv (“SimplePendulumWithImage-Discrete”);%获得观察和行动规范obsInfo = getObservationInfo (env);actInfo = getActionInfo (env);
创建一个代理初始化选项对象,指定网络中每个隐藏的完全连接层必须具有128神经元(而不是默认的数字,256).
initOpts = rlAgentInitializationOptions (“NumHiddenUnit”, 128);
代理创建函数随机初始化参与者和批评者网络。您可以通过固定随机生成器的种子来确保重现性。为此,取消下面一行的注释。
% rng (0)
根据环境观察和操作规范创建策略梯度代理。
代理= rlPGAgent (obsInfo actInfo initOpts);
将批判学习率降低到1e-3。
评论家= getCritic(代理);critic.Options.LearnRate = 1 e - 3;代理= setCritic(代理、批评);
从两个批评家中提取深度神经网络。
criticNet = getModel (getCritic(代理));
默认的DQN代理使用多输出q值评估逼近器。多输出近似器将观察值作为输入,状态行为值作为输出。每个输出元素表示从观察输入所指示的状态中采取相应离散行动的预期累积长期回报。
显示批评网络的各层,并验证每个隐藏的全连接层有128个神经元
criticNet。层
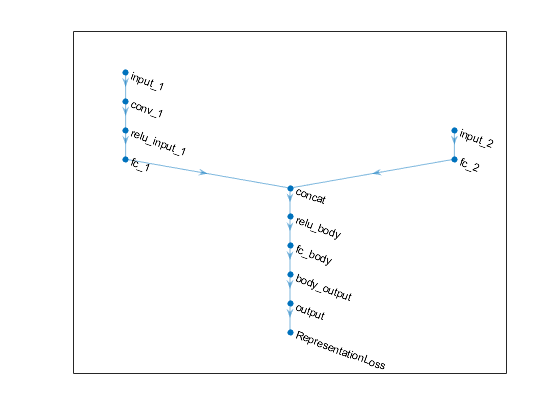
ans = 12x1 Layer array with layers:1的concat串联连接2输入沿着维度3 2的relu_body ReLU ReLU 3“fc_body”完全连接128完全连接层4的body_output ReLU ReLU 5 input_1的图像输入50 x50x1图片6 conv_1卷积64 3 x3x1旋转步[1]和填充[0 0 0 0]7‘relu_input_1 ReLU ReLU 8 fc_1完全连接10 'fc_2' fully connected 128 fully connected layer 11 'output' fully connected 1 fully connected layer 12 'RepresentationLoss' Regression output mean-平方误差
策划评论家网络
情节(criticNet)
要检查你的代理,使用getAction从随机观察中返回动作。
getAction(代理,{兰特(obsInfo (1) .Dimension),兰德(obsInfo (2) .Dimension)})
ans =1 x1单元阵列{[2]}
现在可以在环境中测试和培训代理。
使用多输出评论家表示创建DQN代理
创建一个环境界面,并获取其观察和操作规范。在本例中,加载用于培训DQN员工平衡车杆系统的例子。这个环境有一个连续的四维观察空间(车和杆的位置和速度)和一个离散的一维作用空间,由两个可能的力的应用组成,-10N或10N。
加载预定义环境env = rlPredefinedEnv (“CartPole-Discrete”);%获得观察和行动规范对象obsInfo = getObservationInfo (env);actInfo = getActionInfo (env);
对于具有离散操作空间的代理,您可以选择创建多输出批评表示,这通常比可比的单输出批评表示更有效。
一个多输出批评家只有观察作为输入,输出向量有尽可能多的元素作为可能的离散动作的数量。当采取相应的离散行动时,每个输出元素表示从作为输入的观测结果开始的预期累积长期回报。
使用深度神经网络近似器创建多输出批评表示。
%创建一个深度神经网络近似器%观测输入层必须有4个元素(obsInfo.Dimension(1))%动作输出层必须有2个元素(长度(actInfo.Elements))dnn = [imageInputLayer([obsInfo.Dimension(1) 1 1]),“归一化”,“没有”,“名字”,“状态”) fullyConnectedLayer(24日“名字”,“CriticStateFC1”) reluLayer (“名字”,“CriticRelu1”) fullyConnectedLayer(24日“名字”,“CriticStateFC2”) reluLayer (“名字”,“CriticCommonRelu”) fullyConnectedLayer(长度(actInfo.Elements),“名字”,“输出”));为评论家设置一些选项criticOpts = rlRepresentationOptions (“LearnRate”, 0.01,“GradientThreshold”1);%创建基于网络近似器的批评家评论家= rlQValueRepresentation(款、obsInfo actInfo,“观察”, {“状态”}, criticOpts);
指定代理选项,并使用评论家创建DQN代理。
agentOpts = rlDQNAgentOptions (...“UseDoubleDQN”假的,...“TargetUpdateMethod”,“周期”,...“TargetUpdateFrequency”4...“ExperienceBufferLength”, 100000,...“DiscountFactor”, 0.99,...“MiniBatchSize”, 256);代理= rlDQNAgent(评论家,agentOpts)
agent = rlDQNAgent带有属性:AgentOptions: [1x1 rl.option.]rlDQNAgentOptions] ExperienceBuffer: [1x1 rl.util.ExperienceBuffer]
要检查你的代理,使用getAction从随机观察中返回动作。
getAction(代理,{兰德(4,1)})
ans = 10
现在可以根据环境测试和培训代理。
使用单一输出评论家表示创建DQN代理
创建一个环境界面,并获取其观察和操作规范。在本例中,加载用于培训DQN员工平衡车杆系统的例子。这个环境有一个连续的四维观察空间(车和杆的位置和速度)和一个离散的一维作用空间,由两个可能的力的应用组成,-10N或10N。
加载预定义环境env = rlPredefinedEnv (“CartPole-Discrete”);%获得观察和规格信息obsInfo = getObservationInfo (env);actInfo = getActionInfo (env);
使用深度神经网络近似器创建一个单输出批评家表示。它必须同时有观察和操作作为输入层,并且有一个标量输出,表示从给定的观察和操作之后的预期累积长期回报。
%创建一个深度神经网络近似器%观测输入层必须有4个元素(obsInfo.Dimension(1))%操作输入层必须有1个元素(actInfo.Dimension(1))%输出必须是一个标量statePath = [featureInputLayer(obsInfo.Dimension(1)),“归一化”,“没有”,“名字”,“状态”) fullyConnectedLayer(24日“名字”,“CriticStateFC1”) reluLayer (“名字”,“CriticRelu1”) fullyConnectedLayer(24日“名字”,“CriticStateFC2”));actionPath = [featureInputLayer(actInfo.Dimension(1)),“归一化”,“没有”,“名字”,“行动”) fullyConnectedLayer(24日“名字”,“CriticActionFC1”));commonPath =[附加路径]“名字”,“添加”) reluLayer (“名字”,“CriticCommonRelu”) fullyConnectedLayer (1,“名字”,“输出”));criticNetwork = layerGraph (statePath);= addLayers(criticNetwork, actionPath);criticNetwork = addLayers(criticNetwork, commonPath);criticNetwork = connectLayers (criticNetwork,“CriticStateFC2”,“添加/三机一体”);criticNetwork = connectLayers (criticNetwork,“CriticActionFC1”,“添加/ in2”);为评论家设置一些选项criticOpts = rlRepresentationOptions (“LearnRate”, 0.01,“GradientThreshold”1);%创建基于网络近似器的批评家评论家= rlQValueRepresentation (criticNetwork obsInfo actInfo,...“观察”, {“状态”},“行动”, {“行动”}, criticOpts);
指定代理选项,并使用评论家创建DQN代理。
agentOpts = rlDQNAgentOptions (...“UseDoubleDQN”假的,...“TargetUpdateMethod”,“周期”,...“TargetUpdateFrequency”4...“ExperienceBufferLength”, 100000,...“DiscountFactor”, 0.99,...“MiniBatchSize”, 256);代理= rlDQNAgent(评论家,agentOpts)
agent = rlDQNAgent带有属性:AgentOptions: [1x1 rl.option.]rlDQNAgentOptions] ExperienceBuffer: [1x1 rl.util.ExperienceBuffer]
要检查代理,请使用getAction从随机观察返回操作。
getAction(代理,{兰德(4,1)})
ans = 10
现在可以根据环境测试和培训代理。
用递归神经网络创建DQN Agent
在本例中,加载用于培训DQN员工平衡车杆系统的例子。
env = rlPredefinedEnv (“CartPole-Discrete”);
获取观察和行动信息。这个环境有一个连续的四维观察空间(车和杆的位置和速度)和一个离散的一维作用空间,由两个可能的力的应用组成,-10N或10N。
obsInfo = getObservationInfo (env);actInfo = getActionInfo (env);
为你的批评者创建一个循环的深层神经网络。要创建递归神经网络,请使用sequenceInputLayer作为输入层,并包含lstmLayer作为其他网络层之一。
对于DQN代理,只有多输出q值函数表示支持递归神经网络。万博1manbetx对于多输出q值函数表示,输出层元素的数量必须等于可能动作的数量:元素个数(actInfo.Elements).
[sequenceInputLayer(obsInfo.Dimension(1)),“归一化”,“没有”,“名字”,“状态”) fullyConnectedLayer (50,“名字”,“CriticStateFC1”) reluLayer (“名字”,“CriticRelu1”) lstmLayer (20“OutputMode”,“序列”,“名字”,“CriticLSTM”);fullyConnectedLayer (20,“名字”,“CriticStateFC2”) reluLayer (“名字”,“CriticRelu2”) fullyConnectedLayer(元素个数(actInfo.Elements),“名字”,“输出”));
用递归神经网络为你的批评者创建一个表示法。
criticOptions = rlRepresentationOptions (“LearnRate”1 e - 3,“GradientThreshold”1);评论家= rlQValueRepresentation (criticNetwork obsInfo actInfo,...“观察”,“状态”, criticOptions);
指定用于创建DQN代理的选项。要使用递归神经网络,必须指定SequenceLength大于1。
agentOptions = rlDQNAgentOptions (...“UseDoubleDQN”假的,...“TargetSmoothFactor”, 5 e - 3,...“ExperienceBufferLength”1 e6,...“SequenceLength”, 20);agentOptions.EpsilonGreedyExploration.EpsilonDecay = 1的军医;
创建代理。演员和评论家网络是随机初始化的。
代理= rlDQNAgent(评论家,agentOptions);
使用getAction检查您的代理,以从随机观察返回操作。
getAction(代理,兰德(obsInfo.Dimension))
ans = -10
你也可以从以下列表中选择一个网站: