fsrnca
使用邻域分量分析来选择回归的功能选择
描述
例子
利用NCA进行回归,检测数据中的相关特征
生成玩具数据,其中响应变量依赖于第3、第9和第15个预测因子。
RNG(0,“旋风”);再现性的百分比N = 100;X =兰德(N, 20);y = 1 + X(:, 3) * 5 +罪(X(: 9)。/ X (:, 15) + 0.25 * randn (N - 1));
拟合邻域成分分析模型进行回归。
mdl = fsrnca (X, y,'verbose',1,“λ”,0.5 / n);
o Solver = LBFGS, HessianHistorySize = 15,LineSearchMethod = weakwolfe |====================================================================================================| | ITER | |娱乐价值规范研究生| |规范一步曲线|γ|α|接受 | |====================================================================================================| | 0 e + 00 | 1.636932 | 3.688 e-01 |0.000 e + 00 | | 1.627 e + 0.000 e + 00 00 | |是| | 1 | 8.304833 e-01 e-01 | 1.083 | 2.449 e + 00 |好| 9.194 e + 4.000 e + 00 00 | |是| | 2 | 7.548105 e-01 e-02 | 1.341 | 1.164 e + 00 |好01 | 1.000 | 1.095 e + e + 00 |是| | 3 | 7.346997 e-01 e 03 | 9.752 | 6.383 e-01 |好01 | 1.000 | 2.979 e + e + 00 |是| | 4 | 7.053407 e-01 e-02 | 1.605 | 1.712 e + 00 5.809 e + 01 | | | OK1.000 e + 00 |是| | 5 | 6.970502 e-01 e 03 | 9.106 | 8.818 e-01 |好01 | 1.000 | 6.223 e + e + 00 |是| | 6 | 6.952347 e-01 e 03 | 5.522 | 6.382 e-01 |好01 | 1.000 | 3.280 e + e + 00 |是| | 7 | 6.946302 e-01 e-04 | 9.102 | 1.952 e-01 |好01 | 1.000 | 3.380 e + e + 00 |是| | 8 | 6.945037 e-01 e-04 | 6.557 | 9.942 e-02 |好01 | 1.000 | 8.490 e + e + 00 |是| | |e-04 e-01 6.943908 | 1.997 | 1.756 e-01 |好e + 02 | 1.124 | 1.000 e + 00 |是| | 10 | 6.943785 e-01 e-04 | 3.478 | 7.755 e-02 |好01 | 1.000 | 7.621 e + e + 00 |是| | 11 | 6.943728 e-01 e-04 | 1.428 | 3.416 e-02 |好01 | 1.000 | 3.649 e + e + 00 |是| | 12 | 6.943711 e-01 e-04 | 1.128 | 1.231 e-02 |好01 | 1.000 | 6.092 e + e + 00 |是| | 13 e-01 | 6.943688 | 1.066 e-04 |2。326e-02 | OK | 9.319e+01 | 1.000e+00 | YES | | 14 | 6.943655e-01 | 9.324e-05 | 4.399e-02 | OK | 1.810e+02 | 1.000e+00 | YES | | 15 | 6.943603e-01 | 1.206e-04 | 8.823e-02 | OK | 4.609e+02 | 1.000e+00 | YES | | 16 | 6.943582e-01 | 1.701e-04 | 6.669e-02 | OK | 8.425e+01 | 5.000e-01 | YES | | 17 | 6.943552e-01 | 5.160e-05 | 6.473e-02 | OK | 8.832e+01 | 1.000e+00 | YES | | 18 | 6.943546e-01 | 2.477e-05 | 1.215e-02 | OK | 7.925e+01 | 1.000e+00 | YES | | 19 | 6.943546e-01 | 1.077e-05 | 6.086e-03 | OK | 1.378e+02 | 1.000e+00 | YES | |====================================================================================================| | ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT | |====================================================================================================| | 20 | 6.943545e-01 | 2.260e-05 | 4.071e-03 | OK | 5.856e+01 | 1.000e+00 | YES | | 21 | 6.943545e-01 | 4.250e-06 | 1.109e-03 | OK | 2.964e+01 | 1.000e+00 | YES | | 22 | 6.943545e-01 | 1.916e-06 | 8.356e-04 | OK | 8.649e+01 | 1.000e+00 | YES | | 23 | 6.943545e-01 | 1.083e-06 | 5.270e-04 | OK | 1.168e+02 | 1.000e+00 | YES | | 24 | 6.943545e-01 | 1.791e-06 | 2.673e-04 | OK | 4.016e+01 | 1.000e+00 | YES | | 25 | 6.943545e-01 | 2.596e-07 | 1.111e-04 | OK | 3.154e+01 | 1.000e+00 | YES | Infinity norm of the final gradient = 2.596e-07 Two norm of the final step = 1.111e-04, TolX = 1.000e-06 Relative infinity norm of the final gradient = 2.596e-07, TolFun = 1.000e-06 EXIT: Local minimum found.
绘制选定的特征。不相关特征的权值应该接近于零。
图()图(mdl。FeatureWeights,“罗”) 网格在Xlabel(“功能指数”)ylabel(“功能重量”)
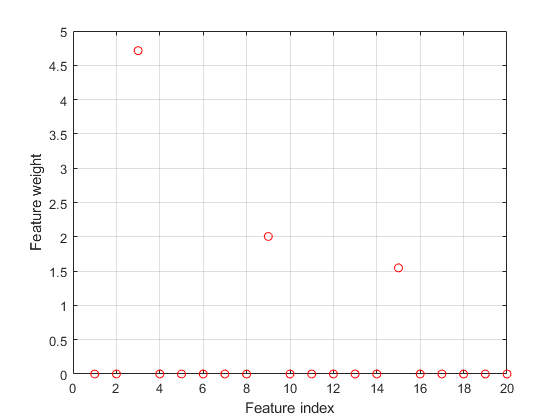
fsrnca正确检测此响应的相关预测器。
回归NCA中的曲调正则化参数
加载样本数据。
负载robotarm.mat
的robotarm(pumadyn32nm)数据集是使用一个机器人手臂模拟器创建的,具有7168个训练观测和1024个测试观测,具有32个特征[1][2]。这是原始数据集的预处理版本。数据经过减去线性回归拟合的预处理,然后将所有特征归一化到单位方差。
使用默认值进行邻域成分分析(NCA)特征选择 (正则化参数)的价值。
NCA = FSRNCA(Xtrain,Ytrain,“FitMethod”,'精确的',...'求解',“lbfgs”);
绘制选定的值。
图(nca阴谋。FeatureWeights,“罗”)Xlabel(“功能指数”)ylabel(“功能重量”) 网格在
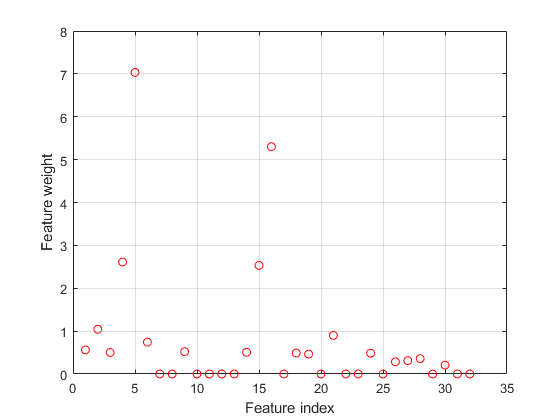
超过一半的特征权重是非零。使用所选功能使用测试设置为性能的量度计算丢失。
L =损失(nca, Xtest欧美)
L = 0.0837
试着提高你的表现。调整正则化参数 使用五倍交叉验证进行特征选择。调优 意味着找到 产生最小回归损失的值。调优 使用交叉验证:
1.将数据分成5个部分。对于每一个褶皱,cvpartition指定4/5的数据作为训练集,1/5的数据作为测试集。
rng (1)再现性的百分比n =长度(YTrain);cvp = cvpartition(长度(yTrain),“kfold”5);numvalidsets = cvp.numtestsets;
分配
值的搜索。将响应值乘以一个常数使损失函数项增加常数的一个因子。因此,包括STD(YTrain)因素
值平衡默认的损失功能('疯狂的',平均绝对偏差)项和目标函数中的正则化项。在这个例子中STD(YTrain)因子是一个,因为加载的样本数据是原始数据集的预处理版本。
lambdavals = linspace(0,50,20)* std(ytrain)/ n;
创建一个数组来存储损失值。
lossvals = 0(长度(lambdavals), numvalidsets);
2.为每个培训NCA模型 值,使用每个折叠中的训练集。
3.使用NCA模型计算折叠中相应测试集的回归损失。记录损失值。
4.对每个人重复这个 价值和每一折。
为i = 1:长度(lambdavals)为k = 1:numvalidsets X = Xtrain(cvp.training(k),:);y = ytrain (cvp.training (k):);Xvalid = Xtrain (cvp.test (k):);yvalid = ytrain (cvp.test (k):);nca = fsrnca (X, y,“FitMethod”,'精确的',...'求解','minibatch-lbfgs',“λ”,lambdavals(i),...“GradientTolerance”,1e-4,“IterationLimit”, 30);lossvals (i (k) =损失(nca, Xvalid yvalid,'损失','妈妈');结束结束
计算每个折叠的平均损耗 价值。
Meanloss =卑鄙(损失,2);
绘制平均损失与 值。
图绘图(Lambdavals,Meanloss,'ro-')Xlabel(“λ”)ylabel(“损失(MSE)”) 网格在
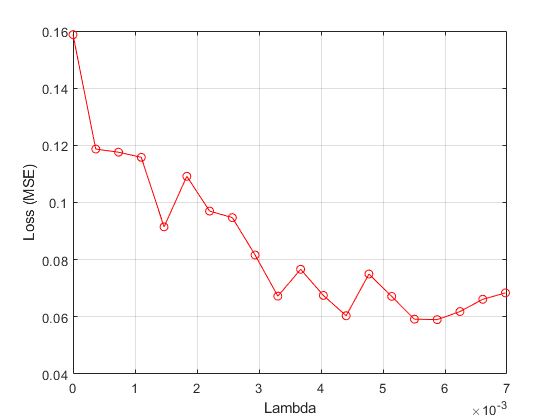
找到 给出最小损失值的值。
[~, idx] = min (meanloss)
Idx = 17.
bestlambda = lambdavals (idx)
bestlambda = 0.0059
bestloss = meanloss (idx)
bestloss = 0.0590
拟合NCA特征选择模型进行回归使用最佳 价值。
NCA = FSRNCA(Xtrain,Ytrain,“FitMethod”,'精确的',...'求解',“lbfgs”,“λ”, bestlambda);
绘制选定的特征。
图(nca阴谋。FeatureWeights,“罗”)Xlabel(“功能指数”)ylabel(“功能重量”) 网格在
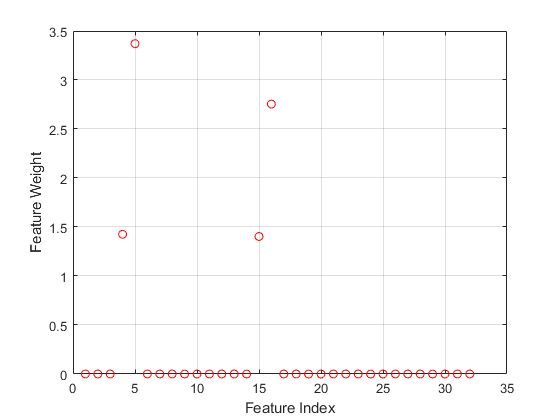
大多数特征权重为零。fsrnca确定四个最相关的特征。
计算测试集的损失。
L =损失(nca, Xtest欧美)
L = 0.0571
调整正则化参数, ,消除了更多不相关的特性,提高了性能。
比较NCA和ARD功能选择
本例使用了鲍鱼数据[3][4]来自UCI机器学习存储库[5].
下载数据并将其保存在当前文件夹中'abalone.csv'.
URL =.“https://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data”;WebSave('abalone.csv',URL);
将数据读入表中。显示前7行。
台= readtable ('abalone.csv',“文件类型”,'文本',“ReadVariableNames”、假);tbl.Properties.VariableNames = {“性”,'长度','直径',“高度”,...'womeight',“SWeight”,“VWeight”,“ShWeight”,“NoShellRings”};台(1:7,:)
ANS =.7×9表性别长度直径高度WWeight SWeight VWeight ShWeight NoShellRings _____ ______ ________ ______ _______ _______ ________ ____________ { 'M'} 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 15 { 'M'} 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 7 { 'F'} 0.530.42 0.135 0.677 0.2565 0.1415 0.21 9 { 'M'} 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 10 { 'I'} 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 7 { 'I'} 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12 8 { 'F'0.53 0.415 0.15 0.7775 0.237 0.1415 0.33 20
数据集有4177个观察。目标是从八个物理测量预测鲍鱼的年龄。最后变量,shell环的数量,显示了鲍鱼的年龄。第一预测器是一个分类变量。表中的最后一个变量是响应变量。
准备预测器和反应变量fsrnca.最后一栏资源描述包含shell rings的数量,即响应变量。第一个预测变量,性别是分类的。您必须创建虚拟变量。
y = table2array(资源描述(:,结束));X (:, 1:3) = dummyvar(分类(tbl.Sex));X = [X, table2array(资源描述(:,2:end-1)));
使用四倍交叉验证来调整NCA模型中的正则化参数。首先将数据分成4个部分。
rng (“默认”)再现性的百分比n =长度(y);本量利= cvpartition (n,“kfold”4);numtestsets = cvp.NumTestSets;
cvpartition将数据分成四个分区(折叠)。在每个折叠中,大约四分之三的数据被分配为训练集,四分之一被分配为测试集。
产生各种各样 (正则化参数)用于拟合模型以确定最佳的值 价值。创建一个向量以从每个拟合中收集损耗值。
lambdavals = linspace(0,25,20)* std(y)/ n;lockvals =零(长度(lambdavals),numtestsets);
行的行lossvals对应于
值和列对应于折叠。
使用NCA模型进行回归使用fsrnca从每个折叠中提取数据
价值。使用来自每个折叠的测试数据计算每个型号的损耗。
为i = 1:长度(lambdavals)为Xtrain = X(cvp.training(k),:);ytrain = y (cvp.training (k):);Xtest = X (cvp.test (k):);欧美= y (cvp.test (k):);NCA = FSRNCA(Xtrain,Ytrain,“FitMethod”,'精确的',...'求解',“lbfgs”,“λ”,lambdavals(i),'标准化',真正的);lossvals (i (k) =损失(nca, Xtest,欧美,'损失','妈妈');结束结束
计算折叠的平均损耗,即计算第二维的平均值lossvals.
Meanloss =卑鄙(损失,2);
绘图 值与四倍的平均损失。
图绘图(Lambdavals,Meanloss,'ro-')Xlabel(“λ”)ylabel(“损失(MSE)”) 网格在
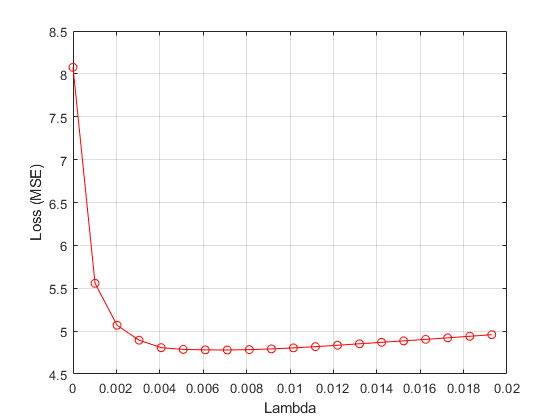
找到 使平均损失最小化的值。
[~, idx] = min (meanloss);bestlambda = lambdavals (idx)
bestlambda = 0.0071
计算最佳损失值。
bestloss = meanloss (idx)
Bestloss = 4.7799.
使用最佳数据适用于所有数据的NCA模型 价值。
nca = fsrnca (X, y,“FitMethod”,'精确的','求解',“lbfgs”,...'verbose',1,“λ”,Bestlambda,'标准化',真正的);
o Solver = LBFGS, HessianHistorySize = 15,LineSearchMethod = weakwolfe |====================================================================================================| | ITER | |娱乐价值规范研究生| |规范一步曲线|γ|α|接受 | |====================================================================================================| | 0 e + 00 | 2.469168 | 1.266 e-01 |0.000 e + 00 | | 4.741 e + 0.000 e + 00 00 | |是| | 1 | 2.375166 e + 00 e-02 | 8.265 | 7.268 e-01 |好01 | 1.000 | 1.054 e + e + 00 |是| | 2 | 2.293528 e + 00 e-02 | 2.067 | 2.034 e + 00 |好01 | 1.000 | 1.569 e + e + 00 |是| | 3 | 2.286703 e + 00 e-02 | 1.031 | 3.158 e-01 |好01 | 1.000 | 2.213 e + e + 00 |是| | 4 | 2.279928 e + 00 e-02 | 2.023 | 9.374 e-01 | | 1.953 e + 01 |1.000 e + 00 |是| | 5 | 2.276258 e + e 03 00 | 6.884 | 2.497 e-01 |好01 | 1.000 | 1.439 e + e + 00 |是| | 6 | 2.274358 e + e 03 00 | 1.792 | 4.010 e-01 |好01 | 1.000 | 3.109 e + e + 00 |是| | 7 | 2.274105 e + e 03 00 | 2.412 | 2.399 e-01 |好01 | 1.000 | 3.557 e + e + 00 |是| | 8 | 2.274073 e + e 03 00 | 1.459 | 7.684 e-02 |好01 | 1.000 | 1.356 e + e + 00 |是| | |e-04 2.274050 e + 00 | 3.733 | 3.797 e-02 |好01 | 1.000 | 1.725 e + e + 00 |是| | 10 | 2.274043 e + 00 e-04 | 2.750 | 1.379 e-02 |好01 | 1.000 | 2.445 e + e + 00 |是| | 11 | 2.274027 e + 00 e-04 | 2.682 | 5.701 e-02 |好01 | 1.000 | 7.386 e + e + 00 |是| | 12 | 2.274020 e + 00 e-04 | 1.712 | 4.107 e-02 |好01 | 1.000 | 9.461 e + e + 00 |是| | 13 e + 00 | 2.274014 | 2.633 e-04 |6.720e-02 | OK | 7.469e+01 | 1.000e+00 | YES | | 14 | 2.274012e+00 | 9.818e-05 | 2.263e-02 | OK | 3.275e+01 | 1.000e+00 | YES | | 15 | 2.274012e+00 | 4.220e-05 | 6.188e-03 | OK | 2.799e+01 | 1.000e+00 | YES | | 16 | 2.274012e+00 | 2.859e-05 | 4.979e-03 | OK | 6.628e+01 | 1.000e+00 | YES | | 17 | 2.274011e+00 | 1.582e-05 | 6.767e-03 | OK | 1.439e+02 | 1.000e+00 | YES | | 18 | 2.274011e+00 | 7.623e-06 | 4.311e-03 | OK | 1.211e+02 | 1.000e+00 | YES | | 19 | 2.274011e+00 | 3.038e-06 | 2.528e-04 | OK | 1.798e+01 | 5.000e-01 | YES | |====================================================================================================| | ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT | |====================================================================================================| | 20 | 2.274011e+00 | 6.710e-07 | 2.325e-04 | OK | 2.721e+01 | 1.000e+00 | YES | Infinity norm of the final gradient = 6.710e-07 Two norm of the final step = 2.325e-04, TolX = 1.000e-06 Relative infinity norm of the final gradient = 6.710e-07, TolFun = 1.000e-06 EXIT: Local minimum found.
绘制选定的特征。
图(nca阴谋。FeatureWeights,“罗”)Xlabel(“功能指数”)ylabel(“功能重量”) 网格在

无关的特征具有零重量。根据该图,未选择特征1,3和9。
采用回归子子集法进行参数估计,完全独立条件法进行预测,拟合高斯过程回归(GPR)模型。使用ARD平方指数核函数,它为每个预测者分配一个单独的权重。规范预测。
gprMdl = fitrgp(资源描述,“NoShellRings”,“KernelFunction”,'ardsquaredexponential',...“FitMethod”,“老”,“PredictMethod”,膜集成电路的,'标准化',真的)
gprmdl = regressiongp predictornames:{'性'长度''直径'直径''height''wweight''sweight''vweight''shweight''shweight'} resplaceName:'noshellrings'pationoricalpricictors:1 responsefransform:'none'numobservations:4177 kernelmunction:'ARDSQUAREDExponential'KERELINFORMATION:[1×1结构]基本功能:'常数'β:11.4959 SIGMA:2.0282预测:[10×1双]预测:[10×1双] alpha:[1000×1双] ActiveSetVectors:[1000×10 Double]预测:'FIC'ActiveSete:1000 FitMethod:'SR'ActiveSetMethod:'随机'isactiveEtvector:[4177×1逻辑] loglikelihove:-9.0019e + 03 ActiveSetory:[1×1 struct] bcdinfination:[]属性,方法
计算培训模型的培训数据(Resubstuite损失)的回归损失。
l = RERUBLOS(GPRMDL)
L = 4.0306
使用最小的交叉验证损失fsrnca与使用带有ARD核的探地雷达模型得到的损失相当。
输入参数
输出参数
参考文献
[1] Rasmussen, C. E., R. M. Neal, G. E. Hinton, D. van Camp, M. Revow, Z. Ghahramani, R. Kustra, R. Tibshirani。《DELVE手册》,1996,http://mlg.eng.cam.ac.uk/pub/pdf/RasNeaHinetal96.pdf。
[2]电脑科学部多伦多大学。delve datasets。http://www.cs.toronto.edu/~delve/data/datasets.html。
纳什、w.j.、t.l.塞勒斯、s.r.塔尔博特、a.j.考索恩和w.b.福特。鲍鱼的种群生物学(石决明物种)的塔斯马尼亚岛。I.黑唇鲍鱼(h . rubra)来自北海岸和低音海峡群岛。“海洋渔业部,技术报告第48号1994年。
[4] Waugh,S。“扩展和基准级联相关性:跨相关架构的延伸和前馈监督人工神经网络的基准。”塔斯马尼亚大学计算机科学系毕业论文, 1995年。
[5] Lichman, m.l UCI机器学习知识库。加州欧文:加州大学信息与计算机科学学院,2013。http://archive.ics.uci.edu/ml。
你也可以从以下列表中选择一个网站:
