主要内容
textrankScores
具有Textrank算法的文档评分
描述
例子
文件的重要性
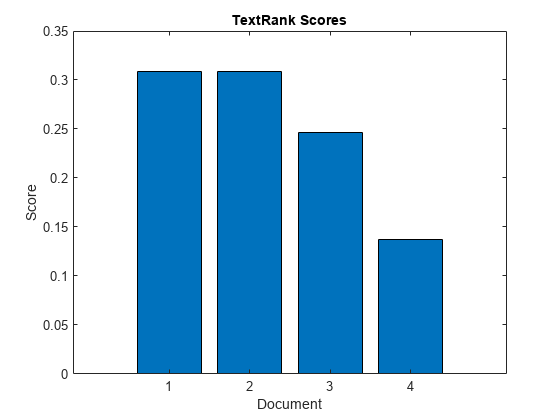
创建一个标记文档数组。
str = [那只敏捷的棕色狐狸跳过了那只懒狗那只敏捷的棕色狐狸跳过了那只懒狗那只懒狗坐在那里什么事也不干"其他动物坐在那里看着"];文件= tokenizedDocument (str)
8个token: the lazy dog sit there and did nothing 6个token: the other animals sit there watching .懒狗坐在那里什么也不做
计算Textrank分数。
成绩= textrankScores(文件);
在条形图中可视化分数。
图酒吧(分数)包含(“文档”)ylabel(“分数”)标题(“TextRank分数”)
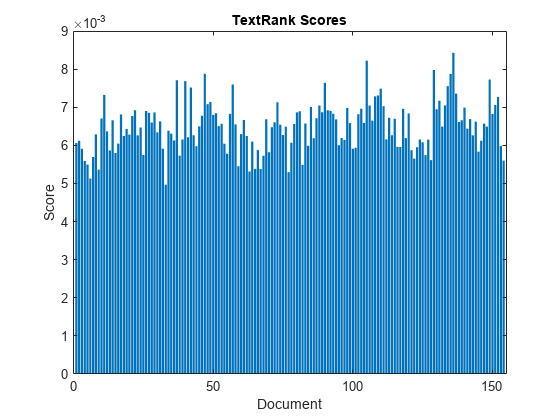
使用单词袋模型的分数
中的文本数据创建一个词袋模型Sonnets.csv.。
文件名=“sonnets.csv”;台= readtable(文件名,“TextType”,“字符串”);textdata = tbl.sonnet;文档= tokenizeddocument(textdata);BAG = BAGOFWORDS(文件)
[1x3527字符串]NumWords: 3527 NumDocuments: 154
计算Textrank分数。
得分= textrankscores(包);
在条形图中可视化分数。
图酒吧(分数)包含(“文档”)ylabel(“分数”)标题(“TextRank分数”)
输入参数
输出参数
参考
[1] Mihalcea,Rada和Paul Tarau。“Textrank:将订单融入文字中。”在自然语言处理中的经验方法2004年会议论文集, 404 - 411页。2004.
另请参阅
bleuEvaluationScore|bm25Similarity|cosineSimilarity|extractSummary|lexrankScores|mmrScores|rougeEvaluationScore|tokenizedDocument
介绍了R2020a
你也可以从以下列表中选择一个网站:
