创建一个Tendon-Driven机器人教本身与强化学习走路
阿里Marjaninejad,南加州大学
为什么工业机器人需要团队的工程师和成千上万行代码执行甚至是最基本的,重复性的任务而长颈鹿、马、和许多其他动物出生几分钟内可以走的?
我和我的同事在南加州大学方面动力学实验室开始解决这个问题通过创建一个机器人肢体学会移动,在没有先验知识的结构或环境[1,2]。几分钟后,G2P,强化学习算法在MATLAB中实现®,学会了如何移动肢体推动跑步机(图1)。

Tendon-Driven肢体控制的挑战
机器人肢体结构架构类似于肌肉和肌腱,人类和脊椎动物运动[1,2]。肌腱连接肌肉骨骼,使生物汽车(肌肉)施加力量骨头从远处[3,4]。(人类的灵巧手是通过tendon-driven系统;没有肌肉的手指自己!)
虽然肌腱机械和结构优势,tendon-driven机器人明显比传统的更有挑战性的控制机器人,一个简单的PID控制器直接控制关节角通常是足够的。tendon-driven机器人肢体,多个汽车可能在一个联合行动,这意味着一个给定的电机可能作用于多个关节。结果,同时系统是非线性的,已经决定,我要说,大大增加了控制设计复杂性和呼吁一个新的控制设计方法。
G2P算法
的学习过程G2P (general-to-particular)算法有三个阶段:运动胡说,勘探和开发。电动机呀呀学语是一段五分钟的肢体表演一系列的随机运动类似于运动婴儿脊椎动物用来学习身体的功能。
在电机呀呀学语阶段,G2P算法随机生成一系列步骤改变当前肢体的三个直流电机(图2),在每个肢体关节测量关节角度编码器,角速度,角加速度。

图2。机器人肢体和直流电机。
然后算法生成一个多层感知器人工神经网络(ANN)使用深度学习工具箱™。训练与角测量输入数据和电机电流作为输出数据,安作为逆映射肢体运动学与生产的电机电流(图3)。
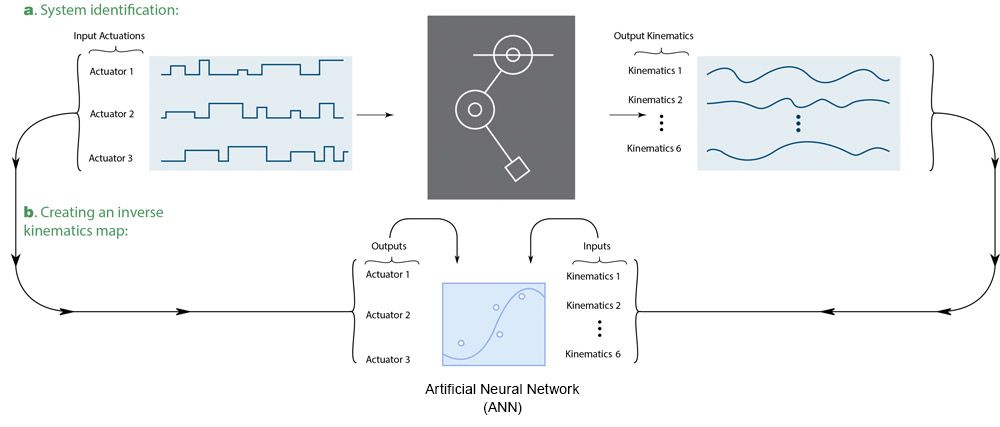
图3。人工神经网络(ANN)培训电动机胡说数据。
接下来,G2P算法进入一个探索阶段,两个阶段的强化学习中的第一个。在探索阶段,该算法指导机器人肢体重复一系列的循环运动,然后G2P算法措施跑步机移动多远。的循环运动,该算法使用一个统一的随机分布生成10分,每个点代表一双关节角。这些10分将插值来创建一个完整的轨迹在关节空间的周期性移动。然后算法计算的角速度和加速度轨迹和使用逆映射来获得相关的运动激活值完成循环。算法提要肢体的三个汽车这些值,重复20次循环之前检查跑步机移动多远。
肢体的距离推动尝试的跑步机的奖励是:距离越大,回报越高。如果奖励很小或者不存在,那么该算法生成一个新的随机周期,使另一个尝试。新的运动学的逆映射算法更新信息在每个尝试。但是,如果奖励超过基线性能阈值(经验决定64毫米),然后算法进入第二强化学习阶段:剥削。
在此阶段,确定了一系列的动作,效果相当好,在算法开始在附近寻找一个更好的解决方案之前测试的轨迹。它通过使用高斯分布生成随机值附近的值用于以前的尝试。如果这个新组的奖励值高于先前的设置,它会继续,回到中心位置上的高斯分布最好新设置的值。当试图产生低于当前最好的奖励,这些值被拒绝的“迄今最佳”值(图4)。
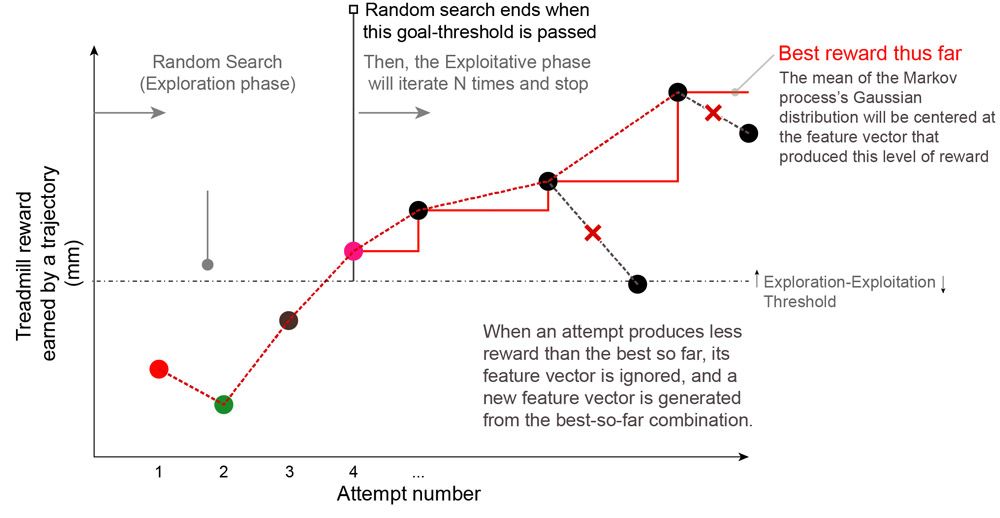
图4。在勘探阶段G2P算法。
独特的步态的出现
每次G2P算法运行时,它开始重新学习,探索机器人的动态新的随机集的肢体动作。偶然,当电机胡说或勘探阶段尤其有效,该算法学习速度更快,需要更少的记者试图联系开发阶段(图5)。该算法并不寻求最优的运动推动跑步机,只有运动不够好。人类和其他生物体也学会使用他们的身体“足够好”,因为有一个与每个实践尝试相关的费用,包括受伤的风险,疲劳,和支出的时间和精力,可以应用到学习其他技能。

图5。跑步机策划反对企图进行奖励的15个不同G2P算法的运行。
一个非凡的结果从随机运动和寻找一个“足够好”的解决方案是,算法产生一个不同的步态每次运行。我们看到G2P算法产生一个各种各样的步态模式,从沉重的跺脚的小心翼翼。我们称这些独特的步态运动个性”,我们的机器人可以开发。我们相信这种方法将使机器人能够在未来有更多的拟人化的特性和特征。
添加反馈和未来的增强
的初始实现G2P完全是前馈。因此,它没有办法应对扰动,如碰撞,除了系统的被动反应。为了解决这个问题,我们实现了一个包含最小的G2P版本反馈[5]。即使在相当漫长的感官的存在延迟(100毫秒),我们发现,除了简单的反馈启用这个新的G2P算法来弥补错误带来的影响或不完美的逆映射。我们还发现,反馈加速学习,需要较短的电机呀呀学语会话,或更少的勘探/开发尝试。
我们计划扩展原则体现在G2P算法两足动物和四足机器人的发展,以及机器人操作。
为什么MATLAB ?
我们的团队决定使用MATLAB为这个项目在其他可用的软件包,原因很多。首先,我们的研究是多学科,涉及神经学家和计算机科学家以及生物医学,机械和电气工程师。无论他们的纪律,团队的每个成员知道MATLAB,共同的语言和合作的一种有效手段。
选择MATLAB的另一个原因是,它使得工作的其他研究人员更容易复制和扩展。我们写的代码可以运行在任何版本的MATLAB。如果我们采用零相位数字滤波使用filtfilt()以MATLAB为例,我们可以相信别人能够使用相同的函数,得到相同的结果。此外,在Python或C,会有担心包或库版本,以及要求更新甚至降级其他包的依赖关系已经在使用。根据我的经验,MATLAB没有这样的限制。
最后,我想说有MATLAB的出色的客户支持。万博1manbetx客户支持团队帮助我们一些问万博1manbetx题,我们正在与我们的数据采集。他们的响应时间和专业知识水平对话题都给我留下了深刻的印象。
我感激地感谢我的同事达里奥Urbina-Melendez和布赖恩•科恩博士以及Francisco Valero-Cuevas方面动力学实验室主任(ValeroLab.org)和π,谁与我在本文中所描述的项目。我还要感谢我们的赞助商包括国防部、美国国防部高级研究计划局,NIH,南加州大学研究生院的支持这个项目。万博1manbetx
2020年出版的
引用
-
[1]Marjaninejad、阿里等。“自治功能运动Tendon-Driven肢体通过经验有限。”arXiv预印本arXiv: 1810.08615 (2018)。
[2]Marjaninejad、阿里等。“自治功能运动tendon-driven肢体通过经验有限。”自然机器智能1.3 (2019):144。
[3]Valero-Cuevas, FJ。Neuromechanics基础。施普林格系列生物系统和生物机器人,斯普林格出版社,伦敦,2016年。
[4]Marjaninejad、阿里和Francisco j . Valero-Cuevas。“拟人化系统应该“冗余”吗?”拟人化的生物力学系统。施普林格,可汗,2019:7-34。
[5]Marjaninejad,阿里,达里奥Urbina-Melendez, Francisco j . Valero-Cuevas。“简单的运动学反馈增强了自主学习在仿生Tendon-Driven系统。”arXiv预印本arXiv: 1907.04539 (2019)。
-
-
-
也seleccionar uno de来说《国家/语言: