trainingOptions
前额侧红神经元深度学习
Descripcion
选项= trainingOptions (solverName)solverName.红色的中间部分,使用中间部分的操作方法funcióntrainNetwork.
选项= trainingOptions (solverName,名称=值)
包括
特别的情话
Cree un conjunto de opciones para entrenar una红色中间梯度下降estocástico现在。Reduzca la tasa de aprendizaje por un factor de 0.2 cada 5 épocas。建立联系número máximo de épocas para entrenamiento en 20 y use un minilote con 64 observaciones en cada iteración。活跃的la gráfica精神进步。
选项= trainingOptions(“个”,...LearnRateSchedule =“分段”,...LearnRateDropFactor = 0.2,...LearnRateDropPeriod = 5,...MaxEpochs = 20,...MiniBatchSize = 64,...情节=“训练进步”)
options = TrainingOptionsSGDM与属性:动量:0.9000 InitialLearnRate: 0.0100 LearnRateSchedule: 'piecewise' LearnRateDropFactor: 0.2000 LearnRateDropPeriod: 5 L2Regularization: 1.0000e-04 GradientThresholdMethod: 'l2norm' GradientThreshold: Inf MaxEpochs: 20 MiniBatchSize: 64 Verbose: 1 VerboseFrequency: 50 ValidationData: [] ValidationFrequency: 50 ValidationPatience: Inf Shuffle: 'once' CheckpointPath: " CheckpointFrequency: 1 CheckpointFrequencyUnit: "'epoch' ExecutionEnvironment: 'auto' WorkerLoad: [] OutputFcn: [] Plots: 'training-progress' SequenceLength: 'longest' SequencePaddingValue: 0 SequencePaddingDirection: 'right' DispatchInBackground: 0 ResetInputNormalization: 1 BatchNormalizationStatistics: 'population' OutputNetwork: 'last-iteration'
深度学习进程监测
Este ejemplo muestra cómo深度学习监测程序。
深度学习,suele ser útil监测技术进步。代表不同的métricas durante el proceso, puede compprobar cómo este progress。我爱你,我爱你precisión我爱你está我爱你qué我爱你está我爱你,我爱你está我爱你。
在我们的世界里有一个地方cómo在我们中间的地方有一个地方funcióntrainNetwork.这段话的意思是,这段话的意思是,这段话的意思是,这段话的意思是,这段话的意思是trainingProgressMonitor副代表métricas持久的友谊。Para obtener más información, consulte监控定制培训循环进度.
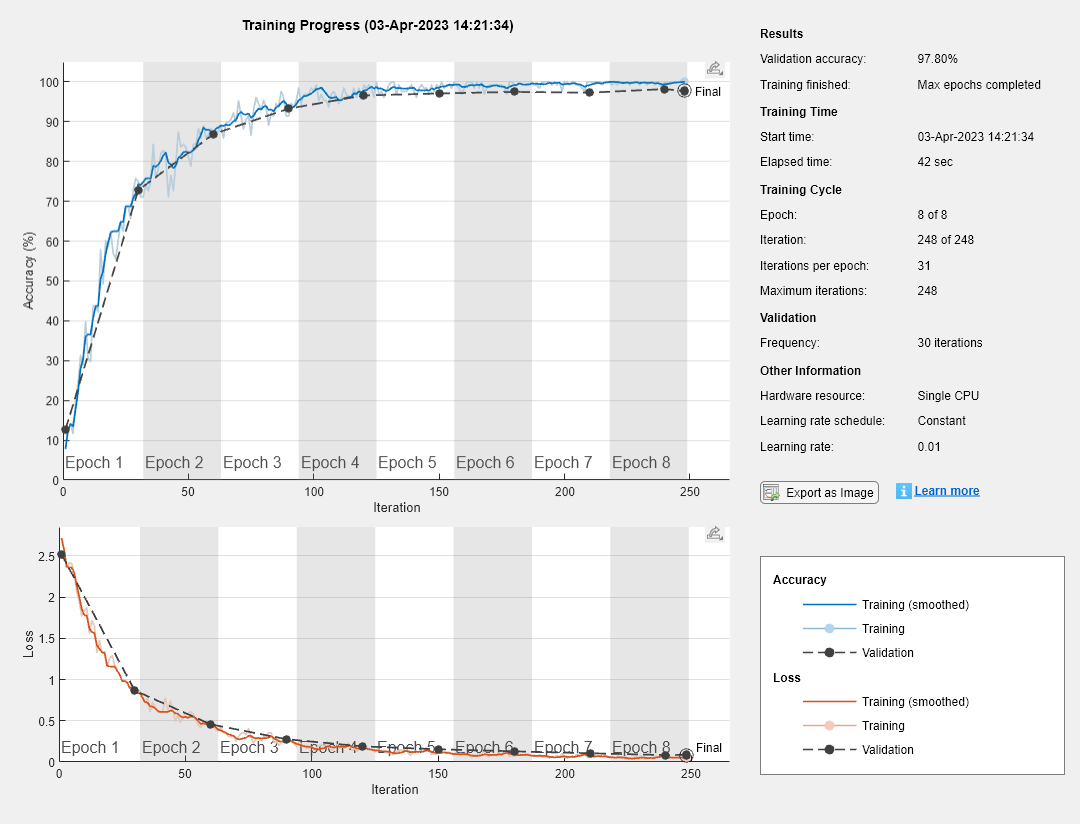
Cuando establishment la opción de entrenamiento情节在“训练进步”帕拉trainingOptions我爱你,爱你,trainNetwork造物之魂métricas心灵之心iteración。卡达iteración es una estimación del gradiente y una actualización de los parámetros de la red。Si se especifican los datos de validación entrainingOptions, la figura muestra las métricas de validación cada vez quetrainNetworkValida la red。La figura representation lo siguiente:
Precisión del entrenamiento: precisión de la clasificación en cada minilote个人。
Precisión你的内心世界: precisión你的天堂,你的天堂,你的天堂,你的天堂,你的天堂precisión你的天堂。我们的生活是美好的precisión我们的生活是美好的detección我们的发展趋势。
Precisión de validación: precisión de la clasificación en todo el conjunto de validación
trainingOptions).Pérdida恩爱之门,Pérdida你的内心世界yPérdida de validación: la pérdida en cada minilote, su versión suavizada y la pérdida en el conjunto de validación,分别。La capa final de La red es una
classificationLayer, por lo que la función de pérdida es la pérdida de entropía cruzada。Para obtener más información清醒的大脑pérdida Para los问题regresión y clasificación,咨询输出层.
En el caso de las redes de regresión, la figura el error cuadrático medio raíz (RMSE En lugar de la precisión。
La figura marca cadaEpoca与联合国的友谊相伴。Una época es Una pasada completa por el conjunto de datos。
Durante el entrenamiento, puede detenerlo和下放el estado实际de la red haciendo clic en el botón de stop de la esquina superior derecha。有一个可能的地方precisión有一个可能的地方mejorará más。那是我们的天堂botón停,那是我们的天堂podría那是我们的天堂。Una vez completado,trainNetworkDevuelve la red entrenada
和你在一起,我很高兴ResultadosQue indican la precisión de validación finalizada y la razón por la Que se ha finalizado el entrenamiento。Si la opción de entrenamientoOutputNetwork斯塔恩“最后一次迭代的”(英勇的预先决定),las métricas结束对应la última iteración de entrenamiento。Si la opción de entrenamientoOutputNetwork斯塔恩“best-validation-loss”, las métricas finalizadas对应la iteración con la pérdida de validación más baja。La iteración a partir de La cual se calculan las métricas de validación finales se etiqueta como最后En las gráficas。
Si la red contene capas de normalización de lotes, la métrica de validación最终的puede ser diente a la métrica de validación evaluada durante el entrenamiento。为了看一幅画estadísticas看一幅画estadísticas看一幅画normalización看一幅画después看一幅画完整的图画。祝你好运opción祝你好运BatchNormalizationStatisics斯塔恩“人口”, después del proceso, el software finaliza las estadísticas de normalización de lotes pasando por los datos de entramiento una vez más y利用la media和la varianza result。Si la opción de entrenamientoBatchNormalizationStatisics斯塔恩“移动”, el software proxima las estadísticas durante el entrenamiento utility zando una estimación continua y utility za los últimos valores de las estadísticas。
A la derecha, vea la información清醒的时代和调整的时代。Para obtener más información清醒的心灵连线,协商参数设置与卷积神经网络训练.
Para guardar la gráfica生命的进步出口培训地块enla ventana del entrenamiento。Puede guardar la gráfica como档案PNG, JEPG, TIFF o PDF。También puede guardar de forma个人las gráficas de pérdida, precisión y错误cuadrático medio raíz con la barra de herramientas de los ejes。
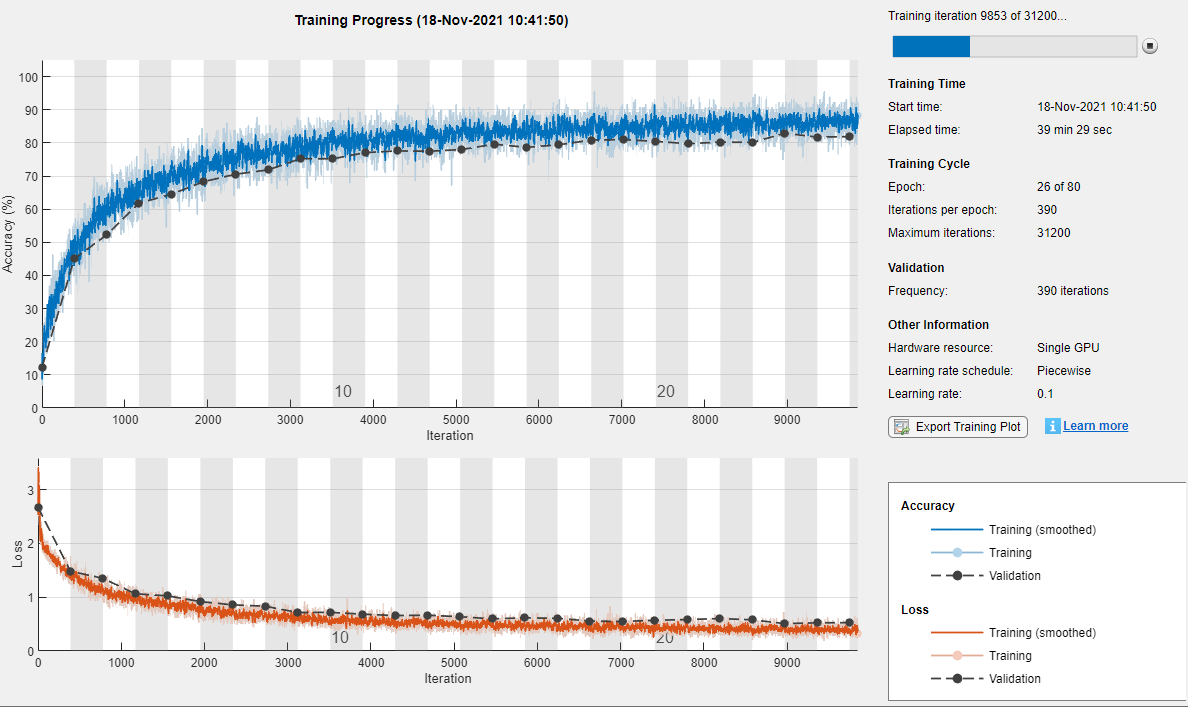
这是一种进步,一种友谊,一种误解
红色的永恒代表着永恒的进步。
欧洲的货物5000 imágenes de dígitos。储备1000 de las imágenes para la validación de la red。
[XTrain,YTrain] = digitTrain4DArrayData;idx = randperm(size(XTrain,4),1000);XValidation = XTrain(:,:,:,idx);XTrain(:,:,:,idx) = [];YValidation = YTrain(idx);YTrain(idx) = [];
蔚蓝蔚蓝蔚蓝蔚蓝蔚蓝蔚蓝蔚蓝蔚蓝蔚蓝蔚蓝蔚蓝imágenes蔚蓝蔚蓝蔚蓝蔚蓝dígitos。
图层= [imageInputLayer([28 28 1])卷积2dlayer(3,8,填充=“相同”) batchNormalizationLayer reluLayer maxPooling2dLayer(2,Stride=2) convolution2dLayer(3,16,Padding=“相同”) batchNormalizationLayer reluLayer maxPooling2dLayer(2,Stride=2) convolution2dLayer(3,32,Padding=“相同”batchNormalizationLayer reluLayer fullyConnectedLayer(10) softmaxLayer classificationLayer];
特别的行动,para el entrenamiento de la red。Para validar la red a intervalos regulares durante el entrenamiento,特别是los datos de validación。伊利亚·埃尔英勇ValidationFrequency赤手空脚的人época。在这段历史中,建立了opción历史情节在“训练进步”.
选项= trainingOptions(“个”,...MaxEpochs = 8,...ValidationData = {XValidation, YValidation},...ValidationFrequency = 30,...Verbose = false,...情节=“训练进步”);
Entrene la red。
net = trainNetwork(XTrain,YTrain,图层,选项);
entrada论证
solverName- - - - - -求解器para entrenar la red
“个”|“rmsprop”|“亚当”
解决问题,在红色的问题上,特别是在其他的问题上:
“个”: usar el optimizador de gradiente descent estocástico con momentento (SGDM)。在中间时刻的英勇opción在中间时刻的英勇动力.“rmsprop”: usar el optimizador RMSProp。Puede speciificar la tasa de decaimiento de la media móvil de gradiente cuadrado mediante la opción de entrenamientoSquaredGradientDecayFactor.“亚当”usar el optimizador亚当。Puede特别las tasas de decaimiento de la media móvil de gradiente y de gradiente cuadrado mediante las opciones de entrenamientoGradientDecayFactorySquaredGradientDecayFactor, respectivamente。
Para obtener más información sobre los different solvers, consulte梯度下降estocástico.
英勇论争
特别的论点是相互的Name1 = Value1,…,以=家,在哪里的名字这就是所谓的论点价值英勇的通讯员。英雄论después英雄论。罪恶禁运,一切都不重要。
在R2021a之前的版本中,使用另一种昏迷方式的名字澳德之间。
比如:InitialLearnRate = 0.03, L2Regularization = 0.0005, LearnRateSchedule =“分段”具体的la tasa de aprendizaje主要como 0.03 y el因子regularizaciónl2Como 0.0005 y dirige指令软件para que reduzca la tasa aprendizaje cada cierto número de épocas multiplicándola por UN determinado factor。
情节- - - - - -Gráficas红色的景象
“没有”|“训练进步”
Gráficas红色的视觉持续时间,以及与此相关的信息:
“没有”: no visualizar gráficas durante el entrenamiento。“训练进步”:国家进步代表。La gráfica muestra información清醒La pérdida y La precisión de minilotes y La pérdida y La precisión de validación, así como información adicional清醒el progreso del entrenamiento。La gráfica incluye el botón de detención En la esquina superior derecha。Haga clic el botón para detener el entramiento y devolver el estado actual de la red。守护星球gráfica地球上有一个星球出口培训地块.Para obtener más información清醒的la gráfica精神进步,协商深度学习进程监测.
En la esquina superior derecha。Haga clic el botón para detener el entramiento y devolver el estado actual de la red。守护星球gráfica地球上有一个星球出口培训地块.Para obtener más información清醒的la gráfica精神进步,协商深度学习进程监测.

详细的- - - - - -指数para mestar información庄严的进步
1(verdadero)(predeterminado) |0(falso)
最理想的指示información战士们冷静地前进,特别是战斗1(verdadero) o0(falso)。
La salida detallada muestra La siguiente información:
clasificación
| 坎波 | Descripcion |
|---|---|
时代 |
Número de épocas。Una época对应的Una pasada完成了所有的数据。 |
迭代 |
Número de iteraciones。Una iteración对应一个un miniilote。 |
时间 |
一分钟一秒地穿越时空。 |
Mini-batch准确性 |
Precisión de clasificación en el minilote。 |
验证准确性 |
Precisión de clasificación en los datos de validación。Si no especifica datos de validación, la función no muestra este campo。 |
Mini-batch损失 |
Pérdida en el minilote。我爱你,我爱你ClassificationOutputLayer, la pérdida es la pérdida de entropía cruzada para问题de clasificación de varias clases con clases mutuamente excluyentes。 |
确认损失 |
Pérdida en los datos de validación。我爱你,我爱你ClassificationOutputLayer, la pérdida es la pérdida de entropía cruzada para问题de clasificación de varias clases con clases mutuamente excluyentes。Si no especifica datos de validación, la función no muestra este campo。 |
基础学习率 |
Tasa de aprendizaje基地。软件的多重因素,在工作中,在工作中,在工作中。 |
regresión
| 坎波 | Descripcion |
|---|---|
时代 |
Número de épocas。Una época对应的Una pasada完成了所有的数据。 |
迭代 |
Número de iteraciones。Una iteración对应一个un miniilote。 |
时间 |
一分钟一秒地穿越时空。 |
Mini-batch RMSE |
错误cuadrático medio raíz (RMSE) en el minilote。 |
验证RMSE |
RMSE en los datos de validación。Si no especifica datos de validación, el software no muestra este campo。 |
Mini-batch损失 |
Pérdida en el minilote。我爱你,我爱你RegressionOutputLayer, la pérdida es el error cuadrático medio didido。 |
确认损失 |
Pérdida en los datos de validación。我爱你,我爱你RegressionOutputLayer, la pérdida es el error cuadrático medio didido。Si no especifica datos de validación, el software no muestra este campo。 |
基础学习率 |
Tasa de aprendizaje基地。软件的多重因素,在工作中,在工作中,在工作中。 |
我们的爱人,我们的爱人razón我们detención。
Para especificdatos de validación,使用la opción de entrenamientoValidationData.
数据提示:单|双|int8|int16|int32|int64|uint8|uint16|uint32|uint64|逻辑
VerboseFrequency- - - - - -Frecuencia de impresión detallada
50(predeterminado) |entero positivo
我们在一起impresión我们在一起,我们在一起número我们在一起impresión我们在一起,我们在一起。Esta opción tiene efecto cuando la opción de entrenamiento详细的西文1(verdadero)。
我的爱人,我的爱人,trainNetworkTambién突击队员们的英勇行动validación。
数据提示:单|双|int8|int16|int32|int64|uint8|uint16|uint32|uint64
salida的论证
Sugerencias
在深度学习的过程中,有一段时间,有一段时间,有一段时间。Para ver un ejemplo de cómo usar la transferencia del aprendizaje Para volver a entrar una red神经元convolucional Para category un nuevo conjunto de imágenes, consulteEntrenar redes de深度学习para classification nuevas imágenes.Como alternativa, puede crear y entrenar redes desde cero usando objects
layerGraph恶作剧trainNetworkytrainingOptions.Si la función
trainingOptions没有一定比例的权利和权利,没有必要的权利和权利,没有必要的权利和权利diferenciación automática。Para obtener más información, consulte为自定义训练循环定义深度学习网络.
Algoritmos
Referencias
[1]毕晓普c.m.模式识别与机器学习.施普林格,纽约,纽约,2006。
[2]墨菲,k.p.。机器学习:一个概率的视角.麻省理工学院出版社,剑桥,马萨诸塞州,2012年。
[3]帕斯卡努,R., T.米科洛夫,Y.本吉奥。"关于训练循环神经网络的难度"第30届机器学习国际会议论文集.Vol. 28(3), 2013, pp. 1310-1318。
[4]金玛,迪德里克和吉米巴。《亚当:随机优化方法》arXiv预打印arXiv:1412.6980(2014)。
历史版本
介绍en R2016a您也可以从以下列表中选择一个网站: