数据导入深度网络设计师
您可以导入和可视化培训和验证数据深层网络设计师。使用这个应用程序,您可以:
关于数据集的更多信息你可以使用开始深入学习,明白了深度学习的数据集。更多信息构造和深度学习应用程序使用的数据存储对象,明白了数据存储深度学习。
导入数据
深陷网络设计师,可以导入图像分类数据从一个图像数据存储或文件夹包含子文件夹的图像从每个类。你也可以导入和培训适用于任何数据存储对象trainNetwork函数。选择导入方法基于数据存储您正在使用的类型。
进口ImageDatastore对象 |
导入其他数据库对象(不推荐ImageDatastore) |
|---|---|
选择导入数据>导入图像分类数据。
|
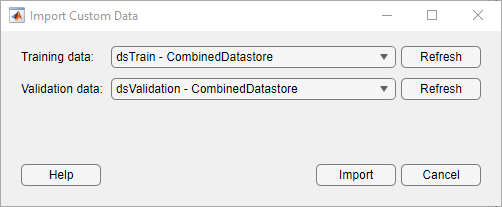
选择导入数据>导入自定义数据。
|
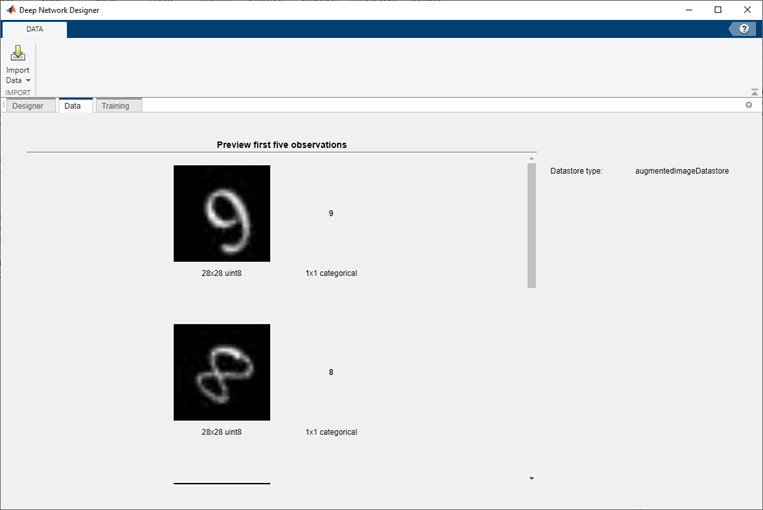
导入后,网络设计师提供了一个预览的进口数据,这样您就可以检查数据如预期,之前的训练。图像分类数据,网络设计师也将显示一个类标签和一个随机选择的直方图的图像导入的数据。你也可以选择随机图像属于一个特定的类。
导入数据的任务
| 任务 | 数据类型 | 数据导入方法 | 可视化例子 |
|---|---|---|---|
| 图像分类 | 为每个类文件夹与子文件夹包含图像。类标签来自子文件夹名称。 例如,看到的转移学习与深层网络设计师。 |
选择导入数据>导入图像分类数据。 你可以选择增加选项和指定验证数据使用导入图像数据对话框。 导入后,网络设计师显示柱状图类的标签。您还可以看到从每个类随机观测。 |
|
例如,创建一个图像包含数字数据的数据存储。 dataFolder = fullfile (toolboxdir (“nnet”),“nndemos”,…“nndatasets”,“DigitDataset”);imd = imageDatastore (dataFolder,…“IncludeSubfolders”,真的,…“LabelSource”,“foldernames”); |
|||
例如,创建一个包含数字数据的增强图像数据存储。 dataFolder = fullfile (toolboxdir (“nnet”),“nndemos”,…“nndatasets”,“DigitDataset”);imd = imageDatastore (dataFolder,…“IncludeSubfolders”,真的,…“LabelSource”,“foldernames”);imageAugmenter = imageDataAugmenter (…“RandRotation”[1,2]);augimds = augmentedImageDatastore (28 [28], imd,…“DataAugmentation”,imageAugmenter);augimds = shuffle (augimds); |
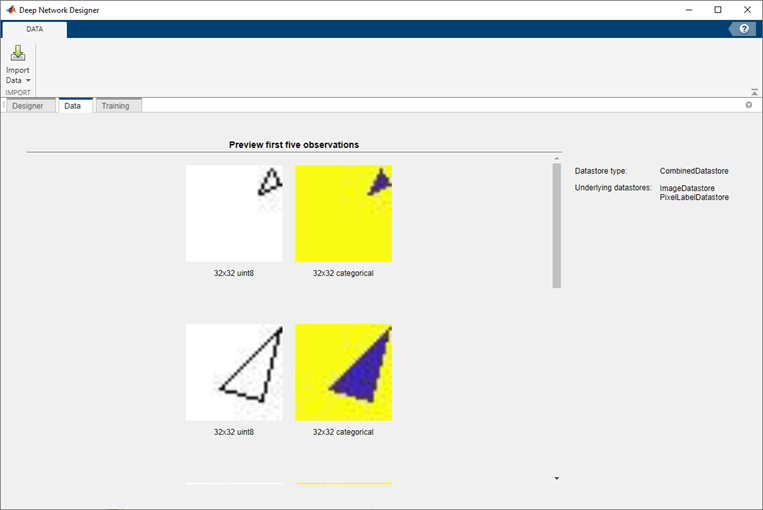
选择导入数据>导入自定义数据。 您可以指定的验证数据导入数据存储对话框。 导入后,网络设计师展示了一个预览的前五个观测数据存储。 |
|
|
| 语义分割 | 例如,一个结合起来 dataFolder = fullfile (toolboxdir (“愿景”),…“visiondata”,“triangleImages”);imageDir = fullfile (dataFolder,“trainingImages”);labelDir = fullfile (dataFolder,“trainingLabels”);imd = imageDatastore (imageDir);一会= [“三角形”,“背景”];labelIDs = (255 0);一会,pxds = pixelLabelDatastore (labelDir labelIDs);cd =结合(imd, pxds); 你也可以把一个 pxds pximds = pixelLabelImageDatastore (imd); |
选择导入数据>导入自定义数据。 您可以指定的验证数据导入数据存储对话框。 导入后,网络设计师展示了一个预览的前五个观测数据存储。 |
|
| Image-to-image回归 | 例如,结合噪声输入图像和原始输出图像来创建数据适合image-to-image回归。 dataFolder = fullfile (toolboxdir (“nnet”),“nndemos”,…“nndatasets”,“DigitDataset”);imd = imageDatastore (dataFolder,…“IncludeSubfolders”,真的,…。“LabelSource”,“foldernames”);imd =变换(imd, @ (x)重新调节(x));imdsNoise =变换(imd, @ (x) {imnoise (x,“高斯”,0.2)});cd =结合(imdsNoise, imd);cd = shuffle (cds); |
选择导入数据>导入自定义数据。 您可以指定的验证数据导入数据存储对话框。 导入后,网络设计师展示了一个预览的前五个观测数据存储。 |
|
| 回归 | 创建数据适合训练回归网络结合数组数据存储对象。 [XTrain ~, YTrain] = digitTrain4DArrayData;广告= arrayDatastore (XTrain,“IterationDimension”4…“OutputType”,“细胞”);adsAngles = arrayDatastore (YTrain,“OutputType”,“细胞”);cd =结合(广告,adsAngles); 培训回归网络的更多信息,请参阅火车卷积神经网络回归。 |
选择导入数据>导入自定义数据。 您可以指定的验证数据导入数据存储对话框。 导入后,网络设计师展示了一个预览的前五个观测数据存储。 |
|
| 序列和时间序列 | 输入序列数据存储的数据预测的深度学习网络的mini-batches序列必须具有相同的长度。您可以使用 例如,垫的序列都是一样的长度最长的序列。 [XTrain, YTrain] = japaneseVowelsTrainData;XTrain = padsequences (XTrain 2);adsXTrain = arrayDatastore (XTrain,“IterationDimension”3);adsYTrain = arrayDatastore (YTrain);cdsTrain =结合(adsXTrain adsYTrain);
减少的填充量,您可以使用一个转换数据存储和一个helper函数。例如,垫mini-batch中的序列,这样所有的序列有相同的长度作为mini-batch最长的序列。您还必须使用相同的mini-batch大小培训选项。 [XTrain, TTrain] = japaneseVowelsTrainData;miniBatchSize = 27个;adsXTrain = arrayDatastore (XTrain,“OutputType”,“相同”,“ReadSize”,miniBatchSize);adsTTrain = arrayDatastore (TTrain,“ReadSize”,miniBatchSize);tdsXTrain =变换(adsXTrain @padToLongest);cdsTrain =结合(tdsXTrain adsTTrain); 函数data = padToLongest(数据)序列= padsequences(数据、2 =方向“左”);为n = 1:元素个数(数据)的数据序列{n} = (:,:, n);结束结束 还可以减少排序您的数据填充的最长和最短减少填充指定填充的影响方向。关于填充序列数据的更多信息,请参阅序列填充、截断和分裂。 网络信息培训在时间序列数据,看看列车网络的时间序列预测使用深层网络设计师。 你也可以导入序列数据使用自定义数据存储对象。为一个例子,演示如何创建一个自定义序列数据存储,明白了列车网络的使用自定义Mini-Batch序列数据的数据存储。 |
选择导入数据>导入自定义数据。 您可以指定的验证数据导入数据存储对话框。 导入后,网络设计师展示了一个预览的前五个观测数据存储。 |
|
| 其他扩展工作流(如数字输入功能,出现内存不足的数据,图像处理,和音频和语音处理) | 数据存储 对于其他扩展的工作流,使用一个合适的数据存储对象。例如,自定义数据存储, 例如,创建一个 dataFolder = fullfile (toolboxdir (“图片”),“imdata”);imd = imageDatastore (dataFolder,“FileExtensions”,{“jpg”});dnd = denoisingImageDatastore (imd,…“PatchesPerImage”,512,…“PatchSize”,50岁,…“GaussianNoiseLevel”[0.01 - 0.1]); 为一个例子,演示如何训练深入学习网络音频数据,看看转移与Pretrained音频网络学习深陷网络设计师。 对于表数组数据,您必须将您的数据转换成一个合适的数据存储训练使用深层网络设计师。例如,先将表格转换成数组包含预测和响应。然后,把数组转换成 |
选择导入数据>导入自定义数据。 您可以指定的验证数据导入数据存储对话框。 导入后,网络设计师展示了一个预览的前五个观测数据存储。 |
|





图像增强
图像分类问题,深层网络设计师提供简单增加选项适用于训练数据。打开导入图像分类数据对话框选择导入数据>导入图像分类数据。您可以选择选项应用随机组合的反射,旋转,尺度改变和翻译操作训练数据。

可以有效地增加训练数据通过应用随机增加到你的数据。增加还使您能够训练网络是扭曲图像数据不变。例如,您可以添加随机旋转输入图像,这样一个网络是存在旋转不变的输入图像。数据增加还可以帮助防止网络过度拟合和记忆的训练图像的细节。当你使用数据,使用一个随机增强版本的每个图像在每个时代的训练,在一个时代是一个完整的通过训练算法的整个训练数据集。因此,每个时代都使用稍微不同的数据集,但训练图像的实际数量在每个时代不会改变。有关更多信息,请参见创建和探索数据存储的图像分类。
执行更普遍和复杂的图像预处理操作比提供的深度网络设计师,使用TransformedDatastore和CombinedDatastore对象。进口CombinedDatastore和TransformedDatastore对象,选择导入数据>导入自定义数据。
图像增强的更多信息,请参阅预处理图像深度学习。
验证数据
深陷网络设计师,可以导入验证数据使用在训练。验证数据是数据网络不使用更新重量和偏见在训练。随着网络并不直接使用这些数据,它是用于评估网络在训练的真实准确性。您可以监视验证指标,如损失和准确性、评估如果网络过度拟合或underfitting和调整训练方案。例如,如果验证损失远远高于训练损失,那么网络可能会过度拟合。

更多信息的准确性提高深度学习网络,看到的深度学习技巧和窍门。
深陷网络设计师,你可以导入验证数据:
从数据存储在工作区中。
从一个文件夹包含子文件夹的图片为每个类(仅图像分类数据)。
通过分割的一部分训练数据作为验证数据(图像分类数据)。数据分为验证和训练集一次,之前的训练。调用此方法坚持验证。
从训练数据分割验证数据
当分裂坚持从训练数据,验证数据深度网络设计师分裂每个类的训练数据的百分比。例如,假设您有一个数据集和两个类,猫和狗,选择使用30%的训练数据进行验证。深层网络设计师使用最后30%的图片标签与标签“猫”最后30%“狗”作为验证集。
而不是使用最后30%的训练数据作为验证数据,您可以选择随机分配观测通过选择训练集和验证集随机化复选框在导入图像数据对话框。随机化的图像可以提高网络训练数据的准确性存储在一个非随机的顺序。例如,数字数据集包含10000合成灰度图像的手写数字。这个数据集有一个潜在的图像具有相同的顺序书写风格出现在每个类相邻。的一个示例显示如下。

随机化确保当你分割数据,图像被打乱,这样训练集和验证集包含随机图像每个类。使用培训和验证数据,由一个类似的图像可以帮助防止过度拟合的分布。不是随机的数据确保培训和验证数据每次分裂都是一样的,并且可以帮助改善结果的再现性。有关更多信息,请参见splitEachLabel。
另请参阅
深层网络设计师|TransformedDatastore|CombinedDatastore|imageDatastore|augmentedImageDatastore|splitEachLabel