detectSpeech
语法
描述
detectSpeech (___)没有输出参数显示检测到的情节演讲地区输入信号。
例子
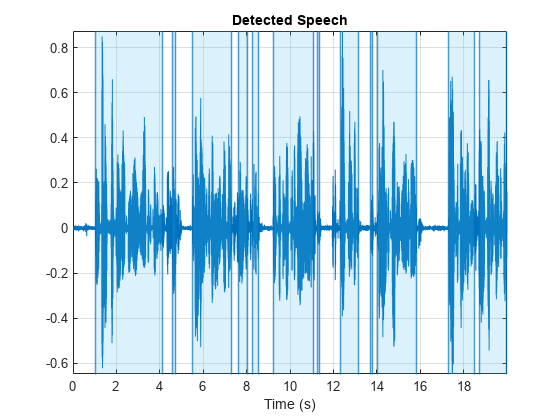
情节检测区域的言论
读入一个音频信号。剪辑20秒的音频信号。
[audioIn, fs] = audioread (“彩虹- 16 - 8 mono - 114 secs.wav”);audioIn = audioIn (1:20 * fs);
调用detectSpeech。没有指定输出参数显示检测到的情节演讲区域。
detectSpeech (audioIn fs);
的detectSpeech函数使用一个基于能量阈值算法和光谱传播的分析框架。您可以修改窗口,OverlapLength,MergeDistance为您的特定需求调整算法。
windowDuration =0.074;%秒numWindowSamples =圆(windowDuration * fs);赢得=汉明(numWindowSamples,“周期”);percentOverlap =
35;重叠=圆(numWindowSamples * percentOverlap / 100);mergeDuration =
0.44;mergeDist =圆(mergeDuration * fs);detectSpeech (audioIn fs,“窗口”,赢了,“OverlapLength”重叠,“MergeDistance”mergeDist)



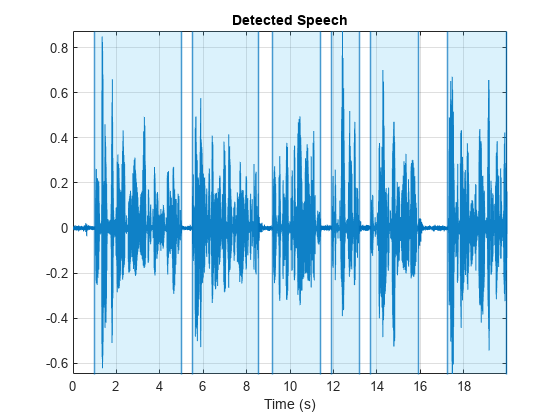
重用决定阈值
读入一个包含演讲的音频文件。将音频信号分为上半年和下半年。
[audioIn, fs] = audioread (“Counting-16-44p1-mono-15secs.wav”);库= audioIn(1:地板(元素个数(audioIn) / 2));后半叶= audioIn(元素个数(库):结束);
调用detectSpeech上半年的音频信号。指定两个输出参数返回相对应的指数区域检测到演讲和所用的阈值决定。
[speechIndices,阈值]= detectSpeech(库,fs);
调用detectSpeech在下半年没有输出参数绘制的区域检测到演讲。从先前的调用指定的阈值确定detectSpeech。
detectSpeech(后半叶,fs,“阈值”阈值)
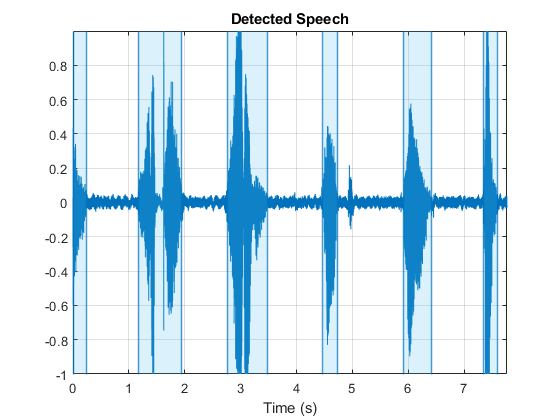
处理大型数据集
复用语音检测阈值提供了重要的计算效率处理大型数据集时,或当你部署一个深度学习机器学习管道实时推理。下载并提取数据集[1]。
url =“https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz”;downloadFolder = tempdir;datasetFolder = fullfile (downloadFolder,“google_speech”);如果~存在(datasetFolder“dir”)disp (“下载数据集(1.9 GB)…”解压(url, datasetFolder)结束
创建一个音频数据存储录音。使用文件夹名称标签。
广告= audioDatastore (datasetFolder,“IncludeSubfolders”,真的,“LabelSource”,“foldernames”);
减少95%的数据集对于本示例。
广告= splitEachLabel(广告,0.05,“排除”,“_background_noise”);
创建两个数据存储:一个用于培训和一个用于测试。
[adsTrain, adsTest] = splitEachLabel(广告,0.8);
计算平均阈值训练数据集。
阈值= 0(元素个数(adsTrain.Files), 2);为2 = 1:元素个数(adsTrain.Files) [audioIn adsInfo] =阅读(adsTrain);[~,阈值(ii)): = detectSpeech (audioIn adsInfo.SampleRate);结束thresholdAverage =意味着(阈值,1);
使用预先计算的阈值来检测语音从测试数据集区域文件。情节三个文件的检测区域。
[audioIn, adsInfo] =阅读(adsTest);detectSpeech (audioIn adsInfo.SampleRate,“阈值”,thresholdAverage);

[audioIn, adsInfo] =阅读(adsTest);detectSpeech (audioIn adsInfo.SampleRate,“阈值”,thresholdAverage);

[audioIn, adsInfo] =阅读(adsTest);detectSpeech (audioIn adsInfo.SampleRate,“阈值”,thresholdAverage);

引用
[1]监狱长,皮特。“语音命令:一个公共数据集对单个词语音识别”。Distributed by TensorFlow. Creative Commons Attribution 4.0 License.
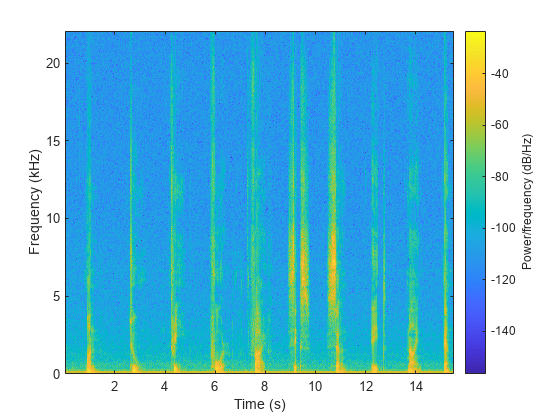
把沉默的地区从语音信号
读入一个音频文件,听它。画出光谱图。
[audioIn, fs] = audioread (“Counting-16-44p1-mono-15secs.wav”);声音(audioIn fs)谱图(audioIn损害(1024年“周期”fs), 512年,1024年,“桠溪”)
对于机器学习应用程序,你经常想从音频信号中提取特征。调用spectralEntropy功能的音频信号,然后画出柱状图显示谱熵的分布。
熵= spectralEntropy (audioIn, fs);numBins = 40;直方图(熵,numBins“归一化”,“概率”)标题(音频信号的谱熵)
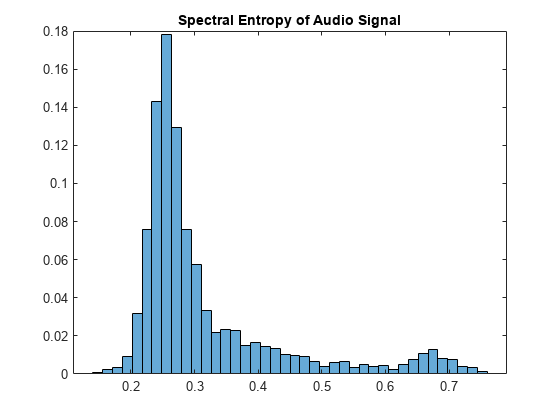
根据您的应用程序中,您可能希望从演讲的区域提取谱熵。所得的统计特征的演讲者和更少的特征通道。调用detectSpeech在音频信号,然后创建一个新的信号只包含检测到演讲的地区。
speechIndices = detectSpeech (audioIn, fs);speechSignal = [];为2 = 1:尺寸(speechIndices 1) speechSignal = [speechSignal; audioIn (speechIndices (2, 1): speechIndices (2, 2)));结束
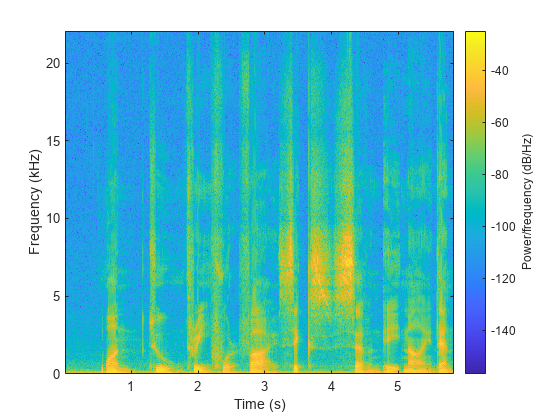
听语音信号,绘制光谱图。
声音(speechSignal fs)谱图(speechSignal损害(1024年“周期”fs), 512年,1024年,“桠溪”)
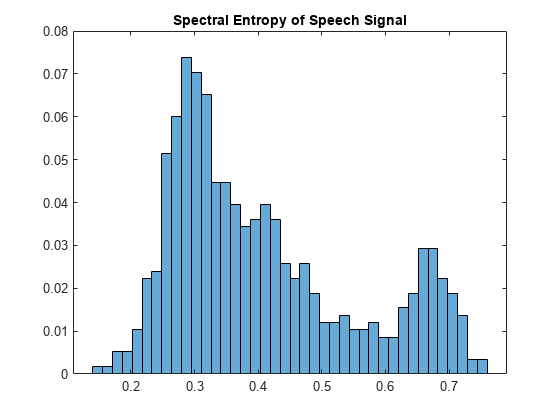
调用spectralEntropy函数对语音信号,然后画出柱状图显示谱熵的分布。
熵= spectralEntropy (speechSignal, fs);直方图(熵,numBins“归一化”,“概率”)标题(语音信号的谱熵)
输入参数
输出参数
算法
的detectSpeech算法是基于[1],尽管修改,以便统计阈值是短期能源和光谱扩散,而不是短期的能量和频谱质心。图和步骤提供一个算法的高级概述。有关详细信息,请参见[1]。
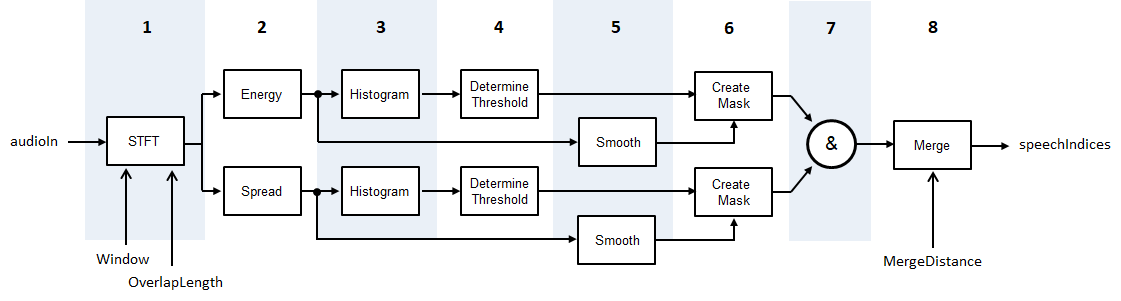
音频信号转换为使用指定的时频表示
窗口和OverlapLength。短期能源和光谱分布计算出每一帧。光谱计算根据传播
spectralSpread。直方图的创建短期能源和光谱扩散分布。
对于每一个柱状图,一个阈值是根据确定的 ,在那里米1和米2分别是第一和第二局部极大值。W被设置为
5。光谱扩散和短期能源被连续通过五行移动平滑跨越时间中位数过滤器。
面具是由比较短期能源和光谱分布和各自的阈值。声明一个框架包含演讲,必须超出阈值特性。
面具的总和。为一个框架声明为演讲,短期能源和光谱传播必须高于各自的阈值。
区域声明为演讲是如果它们之间的距离小于合并
MergeDistance。
引用
[1]Giannakopoulos,塞奥佐罗斯•。“沉默的方法去除语音信号分割,在MATLAB中实现”,(2009年雅典,雅典大学)。
扩展功能
版本历史
介绍了R2020a