Clasificación de secuencias mediante深度学习
Este ejemplo muestra cómo corto-largo广场机密资料(LSTM)。
对脑内的红神经元的深深,对安全数据的分类,对脑内的红。那红色的,介绍安全数据的,那红色的,预测的,那红色的,安全数据的,时间的,个人的。
Este ejemplo usa el conjunto de datos de vocales japanese como se describe en [1] y[2]。以日本为代表,以日本为代表,以日本为代表,以日本为连续。这是一段时间内发生的事情,这段时间内发生的事情。Cada secuencia cuenta con 12 características y不同的经度。连续数据联系法270条连系法270条连系法370条连系法。
Cargar datos secuenciales
货物,数据,权利,日本的声音。XTrain270个经度dimensión 12个不同经度。YEs UN向量categórico de las etiquetas“1”,“2”,…,“9”,“我是新来的。”Las entradas deXTrainSon matrices con 12 filas (una fila por característica) y UN número变量de column (una column por unidad de tiempo)。
[XTrain,YTrain] =日本evowelstraindata;XTrain (1:5)
ans =5×1单元格数组{12x20双}{12x26双}{12x22双}{12x20双}{12x21双}
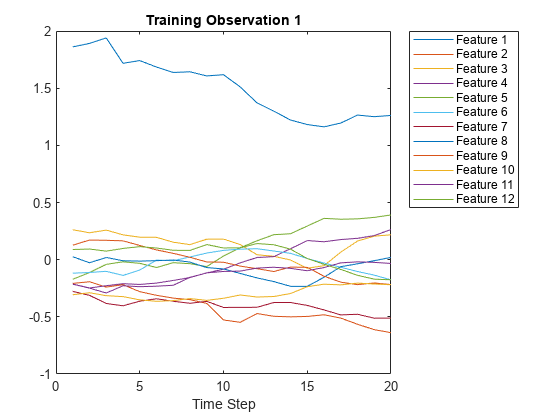
天上时间的初值视觉gráfica。Cada línea se correspondence de con una característica。
图(XTrain{1}')“时间步”)标题(“训练观察1”) numFeatures = size(XTrain{1},1);传奇(“特性”+字符串(1:numFeatures),位置=“northeastoutside”)
准备相关资料
这是一种预先确定的形式,软件划分这是一种预先确定的形式,这是一种预先确定的形式,这是一种预先确定的形式。这是我的过错,这是我的过错,这是我的过错,我的过错。
在交接过程中añada交接过程中,在交接过程中安全的纵深tamaño交接过程中,在交接过程中安全的纵深。关于安全之路的信息después关于数据的顺序。
奥登加的las经度,las安全,para cada observación。
numObservations = numel(XTrain);为i=1:numObservations sequence = XTrain{i};sequenceLengths(i) = size(sequence,2);结束
奥丁尼,洛斯,数据,经度,安全。
[sequenceLengths,idx] = sort(sequenceLengths);XTrain = XTrain(idx);YTrain = YTrain(idx);
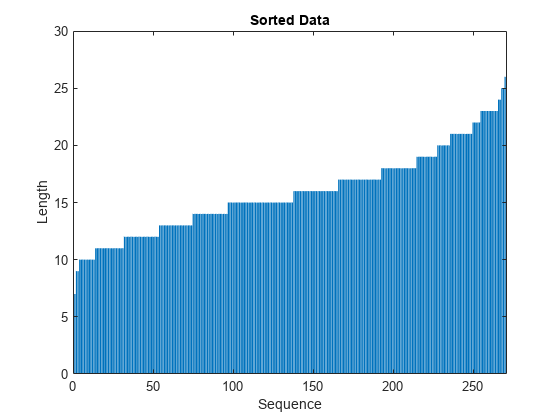
在una的有序的安全经度图gráfica barras。
图bar(sequenceLengths) ylim([0 30]) xlabel(“序列”) ylabel (“长度”)标题(“排序数据”)
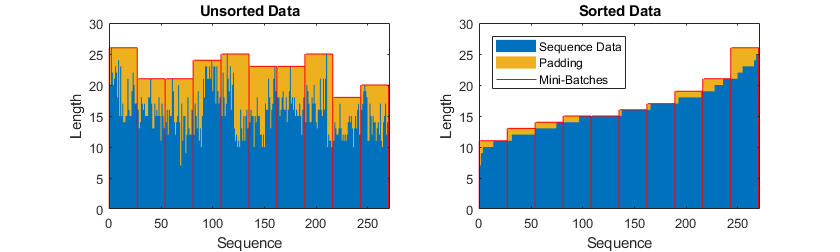
Elija un tamaño de minilote de 27 para dividir los datos de entramian de manera统一地减少la cantida de relleno de minilote。La siguiente figura ilustra el relleno añadido a las secuencias。
miniBatchSize = 27;

LSTM的红色建筑定义
Defina la arquitectura de la red de LSTM特别是el tamaño de la entrada para tenenencias de tamaño 12 (la dimensión de los datos de entrada)。特别是,LSTM双向con 100 unidades ocultas和obtenga como salida el último安全元素。Por último,具体的新类包括,总卡位,总卡位tamaño 9,软卡位,软卡位clasificación。
在一个完整的时间内获取安全predicción, podrá usar una capa de LSTM双向连接。这是LSTM双向安全完全时间统一的方法。我没有办法在生命中获得完整的安全predicción,我有办法,我有办法está在生命中失去的时刻,我有办法在生命中获得成功。
inputSize = 12;numHiddenUnits = 100;numClasses = 9;层= [...sequenceInputLayer inputSize bilstmLayer (numHiddenUnits OutputMode =“最后一次”fullyConnectedLayer(numClasses) softmaxLayer classificationLayer
2”BiLSTM BiLSTM与100个隐藏单元3”全连接9全连接层4”Softmax Softmax 5”分类输出crossentropyex
阿霍拉,特别的,爱与爱。特别求解器“亚当”,本影梯度1 y el número máximo de épocas en 50。Para rellenar los datos y que tengan la misma longitude que las secuencia más largas,特别是la longitude de la secuencia en“最长”.永久数据和安全的经度,特别是和安全的经度。
我的小弟弟pequeños我们的安全,我们的生命más我们的中央。Establezca la opciónExecutionEnvironment在“cpu”.Para realizar un entrenamiento en una GPU, si está disponible,建立la opciónExecutionEnvironment在“汽车”(este es el valor por defto)。
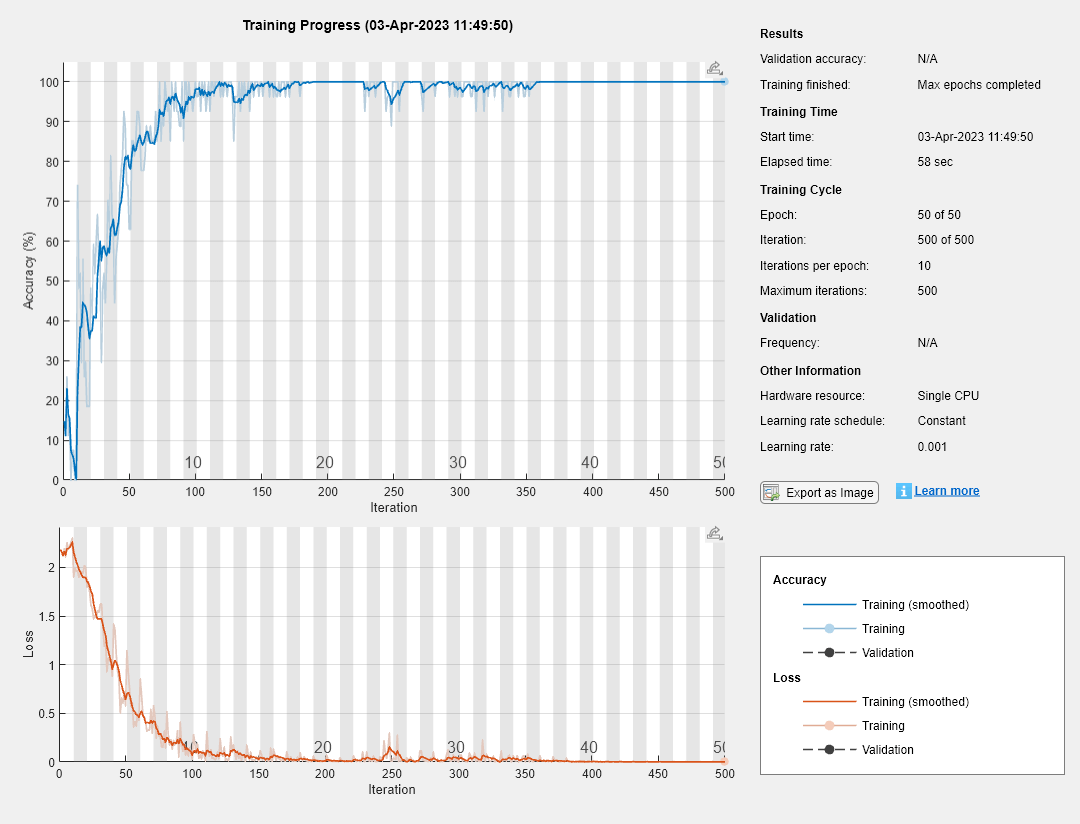
选项= trainingOptions(“亚当”,...ExecutionEnvironment =“cpu”,...GradientThreshold = 1,...MaxEpochs = 50,...MiniBatchSize = MiniBatchSize,...SequenceLength =“最长”,...洗牌=“从不”,...Verbose = 0,...情节=“训练进步”);
Entrenar la red de LSTM
在我的生命中,我的生命中,我的生命中,我的生命trainNetwork.
net = trainNetwork(XTrain,YTrain,图层,选项);
Probar la red de LSTM
货物和财产的安全分类。
货物,数据,权利,语言,日本。XTest联合国连续森林370 secuencias de dimensión 12个经度。欧美Es UN向量categórico de las etiquetas“1”,“2”,…,“9”,“我是新来的。”
[XTest,YTest] =日本evowelstestdata;XTest (1:3)
ans =3×1单元格数组{12x19 double} {12x17 double} {12x19 double}
La red de LSTM网Se ha entrenado utilzando miniilotes de secuencias de longitude相似。Asegúrese关于法律资料和组织形式的问题。奥丁尼,洛斯,德,普鲁,巴,纵,德,安全。
numObservationsTest = numel(XTest);为i=1:numObservationsTest sequence = XTest{i};sequenceLengthsTest(i) = size(sequence,2);结束[sequenceLengthsTest,idx] = sort(sequenceLengthsTest);XTest = XTest(idx);YTest = YTest(idx);
法律资料分类。Para reducir la悬臂de relleno介绍,por el proceso de clasificación,特别是el mismo tamaño de miniilote利用Para el entrenamiento。这是错误的,错误的,错误的,错误的,错误的,错误的,错误的,错误的“最长”.
YPred = category (net,XTest,...MiniBatchSize = MiniBatchSize,...SequenceLength =“最长”);
计算la precisión de clasificación de las predicciones。
acc = sum(YPred == YTest)./ nummel (YTest)
Acc = 0.9730
Referencias
[1]工藤M.,富山J.,辛波M.。“使用穿过区域的多维曲线分类”模式识别信.第20卷,11-13号,第1103-1111页。
[2]UCI机器学习库:日语元音数据集.https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
Consulte也
trainNetwork|trainingOptions|lstmLayer|bilstmLayer|sequenceInputLayer
特马relacionados
您也可以从以下列表中选择一个网站: