使用卷积神经网络分类文本数据
这个例子展示了如何使用卷积神经网络分类文本数据。
使用旋转文本数据进行分类,使用一维卷积层缠绕在输入的时间维度。
这个例子列车网络和不同宽度的一维卷积过滤器。每个过滤器的宽度对应的字数过滤器可以看到(n元长度)。网络有多个分支的卷积层,因此可以使用不同的语法长度。
加载数据
创建一个表格文本数据的数据存储factoryReports.csv和视图最初几个报告。
数据= readtable (“factoryReports.csv”);头(数据)
ans =8×5表类别描述紧急解决成本_______________________________________________________________________ ______________________ __________ ______________________ _____{的物品是偶尔陷入扫描仪线轴。'}{“机械故障”}{‘中等’}{调整机器的}45{”大声作响,声音是来自汇编活塞。'}{“机械故障”}{‘中等’}{调整机器的}35{有削减权力时开始。'}{“电子失败”}{‘高’}{“全部替换”}{16200“炸电容器在汇编程序。'}{“电子失败”}{‘高’}{“替换组件”}352{”融合机跳闸。'}{“电子失败”}{‘低’}{“添加到观察名单”}55{的破裂管道建设代理喷洒冷却剂。'}{“泄漏”}{‘高’}{“替换组件”}371{保险丝吹混合器。'}{“电子失败”}{‘低’}{“替换组件”}441{事情继续下跌的腰带。'}{“机械故障”}{‘低’}{调整机器的}38
分区数据为训练和验证的分区。使用80%的数据进行训练和剩余的数据进行验证。
本量利= cvpartition (data.Category,坚持= 0.2);dataTrain =数据(训练(cvp):);dataValidation =数据(测试(cvp):);
预处理文本数据
提取的文本数据“描述”列的表,使用预处理preprocessText函数,列出的部分文本预处理功能的例子。
documentsTrain = preprocessText (dataTrain.Description);
提取的标签“类别”列并将其转换成分类。
TTrain =分类(dataTrain.Category);
视图类名和观测的数量。
一会=独特(TTrain)
一会=4×1分类电子机械故障泄漏软件失败
numObservations =元素个数(TTrain)
numObservations = 384
提取和使用相同的步骤验证数据进行预处理。
documentsValidation = preprocessText (dataValidation.Description);TValidation =分类(dataValidation.Category);
将文档转换成序列
将文件输入到神经网络,使用一个词编码将文档转换成数字序列指数。
创建一个字编码的文档。
内附= wordEncoding (documentsTrain);
视图的词汇量大小字编码。词汇量的大小是独特的单词的数量“编码”这个词。
numWords = enc.NumWords
numWords = 436
将文档转换成整数序列使用doc2sequence函数。
documentsTrain XTrain = doc2sequence (enc);
验证文件转换为使用这个词编码序列从训练数据创建的。
documentsValidation XValidation = doc2sequence (enc);
定义网络体系结构
定义分类任务的网络体系结构。
下面的步骤描述了网络体系结构。
指定一个输入大小,对应通道尺寸的整数序列输入。
嵌入维的输入使用一个字嵌入100。
语法长度的2、3、4和5,创建的层块包含一个卷积层,一批标准化层,ReLU层,一层辍学,马克斯池层。
对于每个块,指定大小1 - 200卷积过滤器N和全球最大池层。
输入层连接到每一块和连接块的输出使用连接层。
对输出进行分类,包括一个完全连接层与输出大小Ksoftmax层,一层分类,K类的数量。
指定网络hyperparameters。
embeddingDimension = 100;ngramLengths = (2 3 4 5);numFilters = 200;
首先,创建一个层图含有输入层和一个字嵌入层100维度。帮助连接词嵌入层卷积层,设置字嵌入层的名字“循证”。检查卷积层不缠绕在训练序列的长度为零,设置最小长度选择最短的长度在训练数据序列。
最小长度= min (doclength (documentsTrain));层= [sequenceInputLayer(1,最小长度=最小长度)wordEmbeddingLayer (embeddingDimension、numWords Name =“循证”));lgraph = layerGraph(层);
为每个语法长度、创建一个块一维卷积,批处理规范化,ReLU,辍学,一维全球最大池层。每一块连接到字嵌入层。
numBlocks =元素个数(ngramLengths);为j = 1: numBlocks N = ngramLengths (j);块= [convolution1dLayer (N、numFilters Name =“conv”+ N,填充=“相同”)batchNormalizationLayer (Name =“bn”+ N) reluLayer (Name =“relu”+ N) dropoutLayer (0.2, Name =“下降”+ N) globalMaxPooling1dLayer (Name =“马克斯”+ N));lgraph = addLayers (lgraph块);lgraph = connectLayers (lgraph,“循证”,“conv”+ N);结束
添加连接层,完全连接层,将softmax层,和分类层。
numClasses =元素个数(类名);层= = [concatenationLayer (1 numBlocks名称“猫”)fullyConnectedLayer (numClasses Name =“俱乐部”)softmaxLayer (Name =“软”)classificationLayer (Name =“分类”));lgraph = addLayers (lgraph层);
全球最大池层连接到连接层和视图阴谋的网络体系结构。
为j = 1: numBlocks N = ngramLengths (j);lgraph = connectLayers (lgraph,“马克斯”+ N,“猫/”+ j);结束图绘制(lgraph)标题(“网络架构”)

列车网络的
指定培训选项:
火车mini-batch大小为128。
验证网络使用验证数据。
返回网络验证最低的损失。
显示培训进展情节和抑制详细的输出。
选择= trainingOptions (“亚当”,…MiniBatchSize = 128,…ValidationData = {XValidation, TValidation},…OutputNetwork =“best-validation-loss”,…情节=“训练进步”,…Verbose = false);
列车网络使用trainNetwork函数。
网= trainNetwork (XTrain TTrain、lgraph选项);
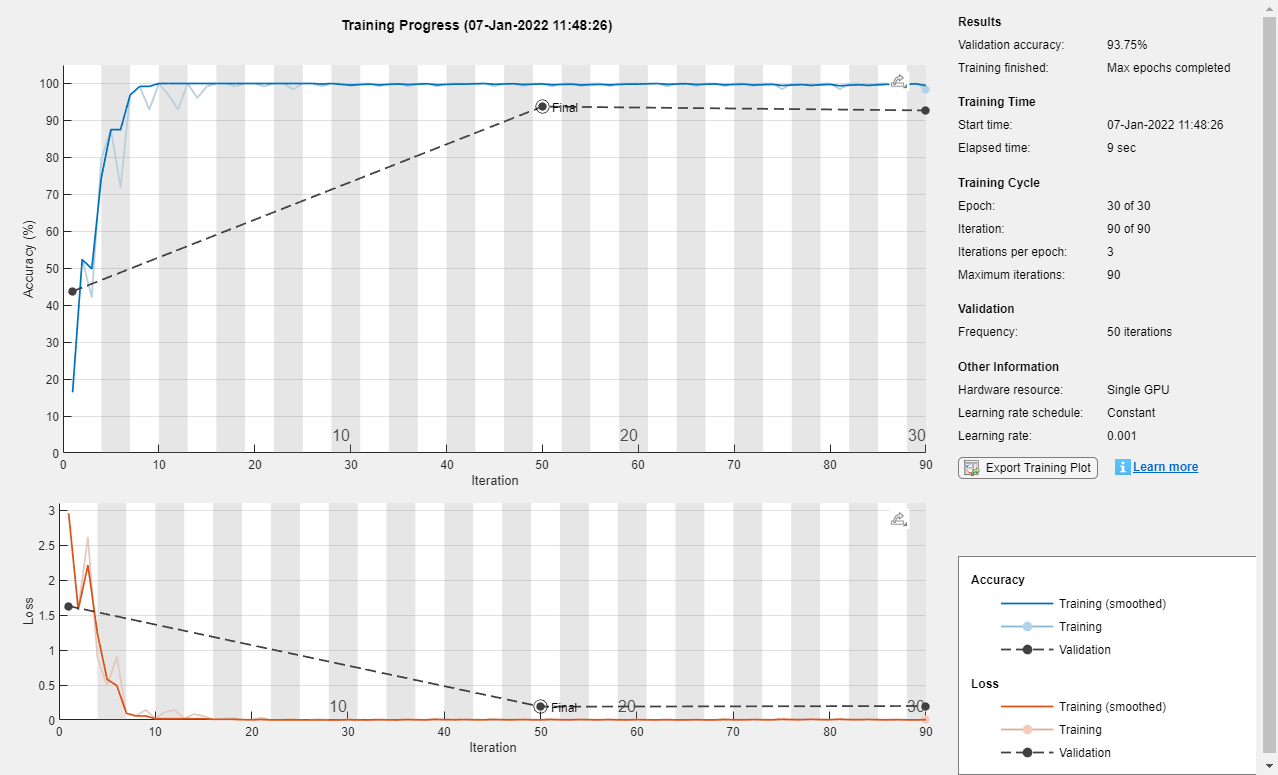
测试网络
使用训练网络的验证数据进行分类。
YValidation =分类(净,XValidation);
图表可视化预测在一个混乱。
图confusionchart (TValidation YValidation)
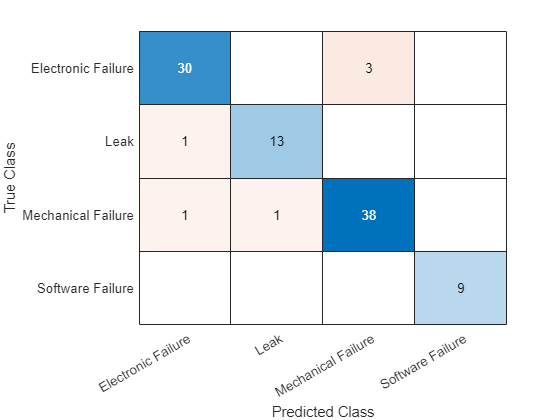
计算分类精度。标签的准确性是比例预测正确。
精度=意味着(TValidation = = YValidation)
精度= 0.9375
预测使用新数据
三个新报告的事件类型进行分类。创建一个字符串数组,其中包含新报告。
reportsNew = [“冷却池下面分选机。”“在启动分选机把保险丝烧断了。”“有一些非常响亮的哒哒声来自汇编程序。”];
预处理文本数据使用的预处理步骤作为训练和验证文档。
documentsNew = preprocessText (reportsNew);documentsNew XNew = doc2sequence (enc);
使用训练网络分类的新序列。
XNew YNew =分类(净)
YNew =3×1分类泄漏电子机械失败
文本预处理功能
的preprocessTextData函数将文本数据作为输入并执行以下步骤:
在标记文本。
将文本转换为小写的。
函数文件= preprocessText (textData)文件= tokenizedDocument (textData);文件=低(文件);结束
另请参阅
fastTextWordEmbedding(文本分析工具箱)|wordcloud(文本分析工具箱)|wordEmbedding(文本分析工具箱)|layerGraph|convolution2dLayer|batchNormalizationLayer|trainingOptions|trainNetwork|doc2sequence(文本分析工具箱)|tokenizedDocument(文本分析工具箱)|变换
相关的话题
- 使用深度学习分类文本数据(文本分析工具箱)
- 使用自定义Mini-Batch数据存储内存不足的文本数据进行分类(文本分析工具箱)
- 创建简单的文本分类模型(文本分析工具箱)
- 使用主题模型分析文本数据(文本分析工具箱)
- 使用多字短语分析文本数据(文本分析工具箱)
- 训练情绪分类器(文本分析工具箱)
- 使用深度学习序列分类
- 数据存储深度学习
- 深度学习在MATLAB