创建策略和值函数
强化学习策略是从当前环境观察到要采取的行动的概率分布的映射。价值函数是从当前环境观察到当前政策的期望值(累积的长期回报)的映射。
强化学习代理使用参数化策略和价值函数,分别由称为参与者和批评者的函数逼近器实现。在训练过程中,智能体更新其行动者和评论家的参数,以最大化预期的累积长期奖励。
在创建非默认代理之前,必须使用近似模型(如深度神经网络、线性基函数或查找表)创建参与者和评论家。可以使用的函数近似器和模型的类型取决于要创建的代理的类型。
您还可以从代理、参与者或评论家创建策略对象。您可以使用自定义循环训练这些对象,并将它们部署到应用程序中。
有关代理的更多信息,请参见强化学习代理.
演员和评论家
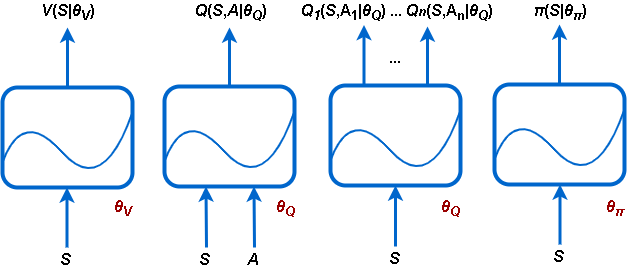
强化学习工具箱™软件支持以下类型的演员和评论家:万博1manbetx
V(年代|θV——根据某一观察结果估计预期累积长期回报的批评家年代.你可以使用
rlValueFunction.问(年代,一个|θ问——对某一特定行动的预期累积长期回报进行评估的批评家一个一个给定的观察结果年代.你可以使用
rlQValueFunction.问我(年代,一个我|θ问——多输出评论家,估计所有可能的离散行动的预期累积长期回报一个我根据观察结果年代.你可以使用
rlVectorQValueFunction.π(年代|θπ) -具有连续动作空间的行动者,根据给定的观察确定地选择动作年代.您可以使用
rlContinuousDeterministicActor.π(年代|θπ) -根据给定的观察随机选择一个动作(动作从概率分布中抽样)的参与者年代.您可以使用任意一种方法创建这些角色
rlDiscreteCategoricalActor(对于离散动作空间)或rlContinuousGaussianActor(用于连续动作空间)。
每个近似器使用一组参数(θV,θ问,θπ),在学习过程中计算。
对于具有有限数量的离散观察和离散操作的系统,您可以在查找表中存储值函数。对于具有许多离散观察和操作的系统,以及连续的观察和操作空间,存储观察和操作是不切实际的。对于这样的系统,您可以使用深度神经网络或自定义(参数线性)基函数来表示您的参与者和评论家。
下表总结了使用Reinforcement Learning Toolbox软件提供的六个逼近器对象的方式,具体取决于您的环境的操作和观察空间,以及您想要使用的逼近模型和代理。
如何在代理中使用函数逼近器(actor或批评家)
| 近似者(演员或评论家) | 万博1manbetx支持模型 | 观察太空 | 行动空间 | 万博1manbetx支持代理 |
|---|---|---|---|---|
价值功能评论家V(年代),您可以使用它来创建 |
表格 | 离散 | 不适用 | Pg ac ppo |
| 深度神经网络或自定义基函数 | 离散的还是连续的 | 不适用 | Pg ac ppo | |
| 深度神经网络 | 离散的还是连续的 | 不适用 | TRPO | |
q值函数评论家,问(年代,),您可以使用它来创建 |
表格 | 离散 | 离散 | Q dqn sarsa |
| 深度神经网络或自定义基函数 | 离散的还是连续的 | 离散 | Q dqn sarsa | |
| 连续 | Ddpg, td3,囊 | |||
具有离散动作空间的多输出q值函数批判器问(年代,),您可以使用它来创建 |
深度神经网络或自定义基函数 | 离散的还是连续的 | 离散 | Q dqn sarsa |
具有连续操作空间的确定性策略参与者π(年代),您可以使用它来创建 |
深度神经网络或自定义基函数 | 离散的还是连续的 | 连续 | DDPG, TD3 |
具有离散行动空间的随机策略参与者π(年代),您可以使用它来创建 |
深度神经网络或自定义基函数 | 离散的还是连续的 | 离散 | Pg ac ppo |
| 深度神经网络 | 离散的还是连续的 | 离散 | TRPO | |
具有连续行动空间的随机策略参与者π(年代),您可以使用它来创建 |
深度神经网络 | 离散的还是连续的 | 连续 | Pg ac ppo sac trpo |
属性配置参与者和评论家优化选项rlOptimizerOptions对象中的一个代理选项对象。
具体来说,您可以创建一个代理选项对象并设置其CriticOptimizerOptions而且ActorOptimizerOptions适当的属性rlOptimizerOptions对象。然后将代理选项对象传递给创建代理的函数。
或者,你可以创建代理,然后使用点符号来访问代理参与者和评论家的优化选项,例如:agent.AgentOptions.ActorOptimizerOptions.LearnRate = 0.1;.
有关代理的更多信息,请参见强化学习代理.
策略对象
您可以从代理提取策略对象,也可以从参与者或评论家创建策略对象。然后你可以使用getAction给定一个输入观测值,从策略中生成确定性或随机动作。与actor和批评家等函数近似器对象不同,策略对象不具有可用于轻松计算参数梯度的函数。因此,策略对象更适合应用程序部署,而不是培训。可选择的策略对象如下表所示。
策略对象
策略对象和getAction行为 |
分布与勘探 | 行动空间 | 用于创建的近似对象 | 萃取所需药剂 |
|---|---|---|---|---|
生成最大化离散动作空间q值函数的动作 |
确定性(无探索) | 离散 | rlQValueFunction或rlVectorQValueFunction |
Q dqn sarsa |
生成具有概率的最大化离散动作空间q值函数的动作 |
默认值:随机(随机行动有助于探索) | 离散 | rlQValueFunction或rlVectorQValueFunction |
Q dqn sarsa |
生成连续的确定性动作 |
确定性(无探索) | 连续 | rlContinuousDeterministicActor |
DDPG, TD3 |
根据内部噪声模型生成带有附加噪声的连续确定性动作 |
默认值:随机(噪音有助于探索) | 连续 | rlContinuousDeterministicActor |
DDPG, TD3 |
根据概率分布产生随机动作 |
默认值:随机(随机行动有助于探索) |
离散 | rlDiscreteCategoricalActor |
Pg ac ppo trpo |
| 连续 | rlContinuousGaussianActor |
Pg ac ppo trpo sac |
每个随机策略对象都有一个选项来启用确定性行为,从而禁用探索。除了rlEpsilonGreedyPolicy而且rlAdditiveNoisePolicy,你可以使用generatePolicyBlock而且generatePolicyFunction来生成Simulink万博1manbetx®块或函数,对给定的观察输入计算策略,返回一个操作。然后可以使用生成的函数或块生成用于应用程序部署的代码。有关更多信息,请参见部署训练有素的强化学习策略.
表模型
基于查找表模型的值函数逼近器(评论家)适用于具有有限数量的离散观察和行动。您可以创建两种类型的查找表:
值表,存储相应观察的奖励
q -table,用于存储对应的观察-动作对的奖励
方法创建值表或q -表,以创建基于表的评论家rlTable函数。然后使用table对象作为其中一个的输入参数rlValueFunction或rlQValueFunction创建近似器对象。
神经网络模型
您可以使用深度神经网络模型创建参与者和评论家函数逼近器。这样做使用深度学习工具箱™软件功能。
网络输入和输出维度
行动者和评论家的网络输入层和输出层的维度必须分别与相应的环境观察和行动通道的维度相匹配。从环境中获取动作和观察规范env,使用getActionInfo而且getObservationInfo函数,分别。
actInfo = getActionInfo(env);obsInfo = getObservationInfo(env);
访问维每个通道的属性。例如,获取第一个环境和动作通道的大小:
actSize = actInfo(1).Dimensions;obsSize = obsInfo(1).Dimensions;
在一般情况下actSize而且obsSize是行向量,其元素是相应维的长度。例如,如果第一个观测通道是256 * 256的RGB图像,actSize是向量[256 256 3].若要计算通道的总维度数,请使用刺激.例如,假设环境只有一个观测通道:
obsDimensions = prod(obsInfo.Dimensions);
为rlVectorQValueFunction批评家和rlDiscreteCategoricalActoractor,您需要获得操作集的可能元素的数量。可以通过访问元素操作通道的属性。例如,假设环境只有一个操作通道:
actNumElements = numel(actInfo.Elements);
用于价值函数评估的网络(如AC、PG、PPO或TRPO代理中使用的网络)必须只将观察结果作为输入,并且必须有单个标量输出。对于这些网络,输入层的尺寸必须与环境观测通道的尺寸相匹配。有关更多信息,请参见rlValueFunction.
用于单输出Q值函数批评的网络(例如Q、DQN、SARSA、DDPG、TD3和SAC代理中使用的网络)必须将观察和操作同时作为输入,并且必须具有单个标量输出。对于这些网络,输入层的维度必须与用于观察和操作的环境通道的维度相匹配。有关更多信息,请参见rlQValueFunction.
用于多输出Q值函数批评的网络(例如Q、DQN和SARSA代理中使用的网络)只将观察结果作为输入,并且必须有一个输出层,其输出大小等于可能的离散动作的数量。对于这些网络,输入层的尺寸必须与环境观测通道的尺寸相匹配。有关更多信息,请参见rlVectorQValueFunction.
对于行动者网络,输入层的维度必须与环境观测通道的维度相匹配,输出层的维度必须如下所示。
在具有离散动作空间的参与者中使用的网络(例如PG、AC和PPO代理中的网络)必须具有单个输出层,其输出大小等于可能的离散动作的数量。有关更多信息,请参见
rlDiscreteCategoricalActor.在具有连续动作空间的确定性参与者中使用的网络(例如DDPG和TD3代理中的网络)必须具有单个输出层,其输出大小与环境动作规范中定义的动作空间的维度相匹配。有关更多信息,请参见
rlContinuousDeterministicActor.在具有连续动作空间的随机行为体中使用的网络(如PG、AC、PPO和SAC代理中的网络)必须有两个输出层,每个输出层具有与环境规范中定义的动作空间维度相同的元素。一个输出层必须生成平均值(必须缩放到动作的输出范围),另一个输出层必须生成动作的标准差(必须是非负的)。有关更多信息,请参见
rlContinuousGaussianActor.
深度神经网络
深度神经网络由一系列相互连接的层组成。您可以将深度神经网络指定为以下之一:
的数组
层对象
请注意
在不同的网络对象中,dlnetwork首选,因为它具有内置的验证检查并支持自动区分。万博1manbetx如果传递另一个网络对象作为输入参数,它将在内部转换为dlnetwork对象。但是,最佳实践是将其他网络对象转换为dlnetwork显式地之前使用它来为强化学习代理创建评论家或参与者。你可以用dlnet = dlnetwork(净),在那里网是深度学习工具箱中的任何神经网络对象。由此产生的dlnet是dlnetwork你用来评价你的评论家或演员的对象。这种做法允许对转换不直接且可能需要额外规范的情况进行更深入的了解和控制。
通常,你建立神经网络的方法是将许多层以数组的形式堆叠在一起层对象,可能会将这些数组添加到layerGraph对象,然后将最终结果转换为dlnetwork对象。
对于需要多个输入或输出层的代理,可以创建一个数组层每个输入路径(观察或操作)和每个输出路径(估计奖励或操作)的对象。然后将这些数组添加到alayerGraph对象,并将它们连接在一起connectLayers函数。
您还可以使用深度网络设计器示例请参见使用深度网络设计器创建代理,并使用图像观察进行训练.
下表列出了强化学习应用中常用的一些深度学习层。有关可用层的完整列表,请参见深度学习层列表.
| 层 | 描述 |
|---|---|
featureInputLayer |
输入特征数据并进行归一化 |
imageInputLayer |
输入矢量和二维图像,并应用归一化。 |
sigmoidLayer |
对输入应用sigmoid函数,使输出以区间(0,1)为界。 |
tanhLayer |
对输入应用双曲正切激活层。 |
reluLayer |
将小于0的任何输入值设置为0。 |
fullyConnectedLayer |
将输入向量乘以权重矩阵,并添加偏置向量。 |
softmaxLayer |
对输入应用softmax函数层,将其归一化为概率分布。 |
convolution2dLayer |
对输入应用滑动卷积滤波器。 |
additionLayer |
将多个图层的输出加在一起。 |
concatenationLayer |
沿着指定的维度连接输入。 |
sequenceInputLayer |
向网络提供输入序列数据。 |
lstmLayer |
对输入应用长短期存储器层。万博1manbetx支持DQN和PPO代理商。 |
的bilstmLayer而且batchNormalizationLayer层不支持强化学习。万博1manbetx
强化学习工具箱软件提供了以下层,其中不包含可调参数(即在训练过程中改变的参数)。
| 层 | 描述 |
|---|---|
scalingLayer |
对输入数组应用线性缩放和偏置。该层用于缩放和移动非线性层的输出,例如tanhLayer而且sigmoidLayer. |
quadraticLayer |
创建一个由输入数组的元素构造的二次多项式向量。当您需要输出是其输入的某个二次函数时,这一层非常有用,例如对于LQR控制器。 |
softplusLayer |
实现softplus激活Y= log(1 + e)X),确保输出总是正的。该函数是整流线性单元(ReLU)的平滑版本。 |
您还可以创建自己的自定义层。有关更多信息,请参见定义自定义深度学习层.
当你创建一个深度神经网络时,为每个输入路径的第一层和输出路径的最后一层指定名称是一个很好的实践。
下面的代码创建并连接以下输入和输出路径:
观测输入路径,
observationPath,第一层命名为“观察”.动作输入路径,
actionPath,第一层命名为“行动”.估计值函数输出路径,
commonPath的输出observationPath而且actionPath作为输入。路径的最后一层被命名“输出”.
observationPath = [featureInputLayer(4,“归一化”,“没有”,“名字”,“myobs”) fullyConnectedLayer(24日“名字”,“CriticObsFC1”) reluLayer (“名字”,“CriticRelu1”) fullyConnectedLayer(24日“名字”,“CriticObsFC2”));actionPath = [featureInputLayer(1,“归一化”,“没有”,“名字”,“myact”) fullyConnectedLayer(24日“名字”,“CriticActFC1”));commonPath = [addtionlayer (2,“名字”,“添加”) reluLayer (“名字”,“CriticCommonRelu”) fullyConnectedLayer (1,“名字”,“输出”));criticNetwork = layerGraph(observationPath);criticNetwork = addLayers(criticNetwork,actionPath);criticNetwork = addLayers(criticNetwork,commonPath);临界网络= connectLayers(临界网络,“CriticObsFC2”,“添加/三机一体”);临界网络= connectLayers(临界网络,“CriticActFC1”,“添加/ in2”);临界网络= dlnetwork(临界网络);
对于所有观察和操作输入路径,必须指定featureInputLayer作为路径的第一层,具有与输入神经元的维数相等的相应环境通道。
,可以查看深度神经网络的结构情节函数。
情节(layerGraph (criticNetwork))

由于输出了一个网络中的rlDiscreteCategoricalActor参与者必须表示执行每个可能动作的概率,软件自动添加一个softmaxLayer作为最终输出层,如果您没有显式地指定它。在计算操作时,参与者然后随机采样分布以返回操作。
确定深度神经网络的层数、类型和大小可能很困难,并且依赖于应用程序。然而,在决定函数逼近器的特征时,最关键的部分是它是否能够为您的应用程序近似最优策略或贴现值函数,也就是说,它是否具有能够正确学习您的观察、行动和奖励信号的特征的层。
在构建你的网络时,考虑以下建议。
对于连续的动作空间,用a约束动作
tanhLayer接着是ScalingLayer如果需要,将操作缩放到所需的值。深度密集的网络
reluLayer层可以很好地近似许多不同的函数。因此,它们通常是很好的首选。从您认为可以近似最优策略或价值函数的尽可能小的网络开始。
当你近似强非线性或有代数约束的系统时,增加更多的层通常比增加每层的输出数量更好。一般来说,逼近器表示更复杂(复合)函数的能力仅随层的大小多项式增长,但随层数呈指数增长。换句话说,更多的层允许逼近更复杂和非线性的组成函数,尽管这通常需要更多的数据和更长的训练时间。给定神经元的总数和类似的近似任务,层数更少的网络可能需要指数级更多的单元才能成功地近似同一类函数,并且可能无法正确地学习和推广。
对于策略上的代理(那些只从遵循当前策略时收集的经验中学习的代理),例如AC和PG代理,如果您的网络很大(例如,一个有两个隐藏层的网络,每个隐藏层有32个节点,有几百个参数),并行训练效果更好。策略上并行更新假设每个工作人员更新网络的不同部分,例如当他们探索观察空间的不同区域时。如果网络很小,worker更新可能会相互关联,从而使训练不稳定。
从神经网络创建和配置演员和评论家
从你的深度神经网络创建一个评论家,使用rlValueFunction,rlQValueFunction或者(只要可能)一个rlVectorQValueFunction对象。为了从深度神经网络中为连续动作空间创建确定性参与者,请使用rlContinuousDeterministicActor对象。要从你的深度神经网络创建一个随机参与者,可以使用rlDiscreteCategoricalActor或者一个rlContinuousGaussianActor对象。若要配置参与者或评论家使用的学习率和优化,请在代理选项对象中使用优化器对象。
例如,为评论家网络创建一个q值函数对象criticNetwork.然后创建一个批评家优化器对象criticOpts指定的学习率0.02的梯度阈值1.
rlQValueFunction(criticNetwork,obsInfo,actInfo,...“观察”, {“观察”},“行动”, {“行动”});criticOpts = rlOptimizerOptions(“LearnRate”, 0.02,...“GradientThreshold”1);
然后创建一个代理选项对象,并设置CriticOptimizerOptions属性的代理选项对象criticOpts.最后创建代理时,将代理选项对象作为最后一个输入参数传递给代理构造函数。
当您创建深度神经网络并配置演员或评论家时,请考虑使用以下方法作为起点。
从尽可能小的网络和高学习率(
0.01).训练这个初始网络,看看代理是否会迅速收敛到一个糟糕的策略,还是以随机的方式行动。如果出现上述任何一种问题,请通过在每一层上添加更多层或更多输出来重新调整网络规模。你的目标是找到一个网络结构,它足够大,学习速度不会太快,并且在初始训练期后显示出学习的迹象(奖励图的改进轨迹)。一旦确定了良好的网络架构,较低的初始学习率可以让您查看代理是否在正确的轨道上,并帮助您检查网络架构是否满足该问题。较低的学习率使参数调优更容易,特别是对于困难的问题。
此外,在配置深度神经网络代理时,请考虑以下技巧。
对DDPG和DQN代理要有耐心,因为它们可能在早期发作的一段时间内什么也学不到,而且它们通常在训练过程的早期表现出累积奖励的下降。最终,在最初的几千次学习后,它们可以表现出学习的迹象。
对于DDPG和DQN制剂,促进制剂的开发至关重要。
对于同时拥有演员和评论家网络的智能体,将演员和评论家的初始学习率设置为相同的值。但是,对于某些问题,将评论家的学习率设置为高于行动者的学习率可以提高学习效果。
循环神经网络
在创建用于除Q和SARSA之外的任何代理的演员或评论家时,您可以使用循环神经网络(RNN)。这些网络是深度神经网络sequenceInputLayer输入层和至少一个具有隐藏状态信息的层,例如lstmLayer.当环境具有不能包含在观测向量中的状态时,它们尤其有用。
对于同时具有演员和评论家的代理,必须对它们都使用RNN,或者对它们中的任何一个都不使用RNN。您不能仅为评论家或参与者使用RNN。
当使用PG代理时,RNN的学习轨迹长度为整个插曲。对于AC座席,请使用NumStepsToLookAhead其选项对象的属性被视为训练轨迹长度。对于PPO制剂,弹道长度为MiniBatchSize属性的options对象。
对于DQN、DDPG、SAC和TD3代理,必须指定轨迹训练的长度为大于1的整数SequenceLength属性。
请注意,连续动作空间PG、AC、PPO和TRPO代理以及使用循环神万博1manbetx经网络(RNN)的SAC代理不支持代码生成,也不支持具有多个输入路径并在任何路径中包含RNN的任何代理。
有关策略和值函数的更多信息和示例,请参见rlValueFunction,rlQValueFunction,rlVectorQValueFunction,rlContinuousDeterministicActor,rlDiscreteCategoricalActor,rlContinuousGaussianActor.
自定义基函数模型
自定义(参数线性)基函数近似模型有形式f = W'B,在那里W权重数组和B必须创建的自定义基函数的列向量输出。线性基函数的可学习参数是的元素W.
对于价值功能评论家(如AC、PG或PPO制剂中使用的批评家),f是标量值,那么W必须是与?长度相同的列向量B,B肯定是观察的结果。有关更多信息和示例,请参见rlValueFunction.
对于单输出Q值函数评论家(如Q、DQN、SARSA、DDPG、TD3和SAC试剂中使用的批评家),f是标量值,那么W必须是与?长度相同的列向量B,B一定是观察和行动的共同作用。有关更多信息和示例,请参见rlQValueFunction.
对于具有离散动作空间的多输出Q值函数批评(如Q、DQN和SARSA代理中使用的那些),f是一个具有与可能的操作数量相同数量的元素的向量。因此W必须是一个矩阵,其列数与可能的操作数相同,行数与长度相同B.B肯定只是观察的结果。有关更多信息和示例,请参见rlVectorQValueFunction.
对于具有连续动作空间的确定性行为体(如DDPG和TD3代理中的行为体),的维度
f必须与代理操作规范的尺寸匹配,该规范是标量或列向量。有关更多信息和示例,请参见rlContinuousDeterministicActor.对于具有离散作用空间的随机行为体(如PG、AC和PPO中的行为体),
f必须为列向量,其长度等于可能的离散动作的数量。actor的输出为softmax (f),表示选择每个可能动作的概率。有关更多信息和示例,请参见rlDiscreteCategoricalActor.对于具有连续动作空间的随机参与者,不能依赖于自定义基函数(他们只能使用神经网络逼近器,因为需要强制标准偏差为正)。有关更多信息和示例,请参见
rlContinuousGaussianActor.
对于任何演员来说,W列的数量必须和元素的数量一样多f,行数与其中的元素数相同B.B肯定只是观察的结果。
有关训练使用线性基函数的自定义代理的示例,请参见培训自定义LQR代理.
创建代理
一旦你创建了你的演员和评论家,你可以创建一个使用它们的强化学习代理。例如,使用给定的参与者和评论家(基线)网络创建PG代理。
agentOpts = rlPGAgentOptions(“UseBaseline”,真正的);agent = rlpagent (actor,baseline,agentOpts);
有关不同类型的强化学习代理的更多信息,请参见强化学习代理.
您可以从现有的代理中使用getActor而且getCritic,分别。
还可以使用设置现有代理的参与者和评论家setActor而且setCritic,分别。行动者和评论家的输入和输出层必须与原始代理的观察和操作规范相匹配。
相关的话题
您也可以从以下列表中选择一个网站: