基于强化学习的配水系统调度
本例展示了如何使用强化学习(RL)学习供水系统的最优泵调度策略。
配水系统
下图显示了一个配水系统。

在这里:
是从蓄水池中供给水箱的水量。
为满足使用需求流出水箱的水量。
强化学习agent的目标是调度水泵运行数量,使系统能量消耗最小化,同时满足使用需求( ).储罐系统的动力学由下列方程控制。
在这里, 和 .24小时内的需求是时间的函数
在哪里 是预期的需求和 表示需求不确定性,需求不确定性从均匀随机分布中抽样。
供给量由运行泵的数量决定, 根据下面的映射。
为了简化问题,功率消耗被定义为运行的泵的数量, .
以下功能是对这种环境的奖励。为避免水箱溢出或排空,如果水位接近最高或最低水位,则会增加额外成本, 或 ,分别。
生成需求概要
要根据所考虑的天数来生成和生成水需求剖面,请使用generateWaterDemand本例末尾定义的函数。
num_days = 4;%天数[WaterDemand, T_max] = generateWaterDemand (num_days);
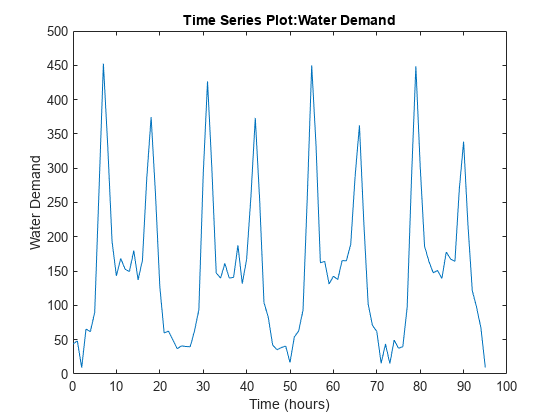
查看需求配置文件。
情节(WaterDemand)
开放和配置模型
打开配电系统的Simulink模型。万博1manbetx
mdl =“水罐调度”;open_system (mdl)

除了强化学习代理,在控制律MATLAB功能块中定义了一个简单的基线控制器。该控制器根据水位激活一定数量的泵。
指定初始水位高度。
h0 = 3;%m
指定模型参数。
SampleTime = 0.2;H_max = 7;%最大油箱高度(m)A_罐=40;%水箱面积(m^2)
创建RL代理的环境接口
要为Simulink模型创建一个环境接口,首先定义动作和观察规范,万博1manbetxactInfo和obsInfoagent action是选定的泵数。agent观测是水位,作为连续时间信号测量。
actInfo=rlFiniteSetSpec([0,1,2,3]);obsInfo=rlNumericSpec([1,1]);
创建环境接口。
env = rl万博1manbetxSimulinkEnv (mdl mdl +“/ RL代理”、obsInfo actInfo);
指定一个自定义的重置函数(在本例的最后定义),它将随机化初始水位和需水量。这样做可以让代理在不同的初始水位和每一集的水需求函数上接受训练。
env。ResetFcn = @(在)localResetFcn(的);
创建DQN代理
DQN代理使用批判q值函数表示来逼近给定的观察和行动的长期回报。要创建批评家,首先要创建一个深度神经网络。有关创建深度神经网络值函数表示的更多信息,请参见创建策略和价值功能表示.
%修复随机发生器种子的再现性。rng(0);
为评论家创建一个深度神经网络。对于本例,使用非递归神经网络。要使用递归神经网络,集合UselTM来真正的.
useLSTM = false;如果useLSTM layers = [sequenceInputLayer(obsInfo.Dimension(1)),“名称”,“状态”,“归一化”,“没有”) fullyConnectedLayer (32,“名称”,“fc_1”) reluLayer (“名称”,“relu_body1”) lstmLayer (32,“名称”,“lstm”) fullyConnectedLayer (32,“名称”,“fc_3”) reluLayer (“名称”,“relu_body3”) fullyConnectedLayer(元素个数(actInfo.Elements),“名称”,“输出”));其他的图层=[featureInputLayer(obsInfo.Dimension(1),“名称”,“状态”,“归一化”,“没有”) fullyConnectedLayer (32,“名称”,“fc_1”) reluLayer (“名称”,“relu_body1”) fullyConnectedLayer (32,“名称”,“fc_2”) reluLayer (“名称”,“relu_body2”) fullyConnectedLayer (32,“名称”,“fc_3”) reluLayer (“名称”,“relu_body3”) fullyConnectedLayer(元素个数(actInfo.Elements),“名称”,“输出”));结束
指定用于创建批评家表达的选项。
criticOpts = rlRepresentationOptions (“LearnRate”, 0.001,“GradientThreshold”1);
使用定义的深度神经网络和选项创建批评家表示。
评论家= rlQValueRepresentation (layerGraph(层),obsInfo, actInfo,...“观察”, {“状态”}, criticOpts);
创建DQN代理
要创建代理,请首先指定代理选项。如果您使用的是LSTM网络,请将序列长度设置为20..
选择= rlDQNAgentOptions (“采样时间”, SampleTime);如果useLSTM opt.SequenceLength = 20;其他的opt.SequenceLength = 1;结束opt.DiscountFactor=0.995;opt.ExperienceBufferLength=1e6;opt.epsilongreedexploration.EpsilonDecay=1e-5;opt.epsilongreedexploration.EpsilonMin=.02;
使用定义的选项和评论家表示创建代理。
代理= rlDQNAgent(评论家,选择);
火车代理
要培训代理,首先指定培训选项。
跑步训练1000集,每集持续
ceil(T_max/Ts)时间的步骤。在“插曲管理器”对话框中显示培训进度(设置
情节(可选)
指定用于培训的选项rlTrainingOptions对象。
trainOpts = rlTrainingOptions (...“最大集”, 1000,...“MaxStepsPerEpisode”装天花板(T_max / SampleTime),...“冗长”假的,...“阴谋”,“训练进步”,...“StopTrainingCriteria”,“EpisodeCount”,...“StopTrainingValue”, 1000,...“ScoreAveragingWindowLength”,100);
虽然在本例中不需要这样做,但您可以在培训过程中保存代理。例如,以下选项将保存每个奖励值大于或等于的代理-42.
如果需要的话,使用SaveAgentCriteria保存代理。SaveAgentCriteria =“EpisodeReward”;trainOpts。SaveAgentValue = -42;
使用火车函数。训练这个代理是一个计算密集型的过程,需要几个小时才能完成。为了节省运行此示例的时间,请通过设置加载预先训练过的代理doTraining来假.自己训练代理人,设置doTraining来真正的.
doTraining = false;如果doTraining培训代理商。trainingStats=列车(代理人、环境、列车员);其他的%加载示例的预训练代理。负载(“万博1manbetxSimulinkWaterDistributionDQN.mat”,“代理”)结束
下图显示了培训进度。

模拟DQN代理
要验证经过训练的agent的性能,请在水箱环境中对其进行模拟。有关agent模拟的更多信息,请参阅模拟选项和sim卡.
为了模拟代理性能,通过拨动手动开关块连接RL代理块。
set_param (mdl +“/手动开关”,“西南”,' 0 ');
设置每个模拟的最大步骤数和模拟的数量。对于本例,运行30个模拟。环境复位函数设置了不同的初始高度,每次模拟的需水量也不同。
NumSimulations = 30;simOptions = rlSimulationOptions (“MaxSteps”T_max / SampleTime...“NumSimulations”, NumSimulations);
为了将agent与基线控制器在相同条件下进行比较,对环境重置函数中使用的初始随机种子进行重置。
环境重置FCN(“重置种子”);
针对环境模拟代理。
experienceDQN = sim (env,代理,simOptions);
模拟基线控制器
要将DQN代理与基线控制器进行比较,必须使用相同的模拟选项和初始的重置函数随机种子来模拟基线控制器。
启用基线控制器。
set_param (mdl +“/手动开关”,“西南”,' 1 ');
为了将agent与基线控制器在相同条件下进行比较,对环境复位函数中使用的随机种子进行复位。
环境重置FCN(“重置种子”);
根据环境模拟基线控制器。
experienceBaseline = sim (env,代理,simOptions);
比较DQN Agent与基线控制器
初始化代理和基线控制器的累计奖励结果向量。
resultVectorDQN = 0 (num道模拟,1);resultVectorBaseline = 0 (NumSimulations, 1);
计算代理和基线控制器的累积奖励。
为ct=1:NumSimulationsResultVectorDQn(ct)=和(经验Qn(ct).奖励);结果部门基线(ct)=总和(经验基线(ct)。奖励);结束
绘制累积奖励。
情节([resultVectorDQN resultVectorBaseline),“哦”甘氨胆酸)组(,“xtick”1: NumSimulations)包含(“模拟数字”) ylabel (“累积奖励”)传说(“DQN”,“基线”,“位置”,“NorthEastOutside”)
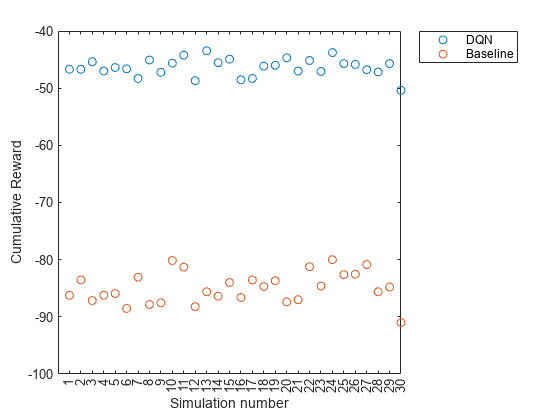
代理人获得的累积报酬始终在-40左右。这个值远远大于基线控制器获得的平均奖励。因此,DQN代理在节能方面始终优于基线控制器。
本地函数
水需求函数
函数[WaterDemand,T_max] = generateWaterDemand(num_days) t = 0:(num_days*24)-1;%的人力资源T_max = t(结束);Demand_mean = [28, 28, 28, 45, 55, 110, 280, 450, 310, 170, 160, 145, 130,...150, 165, 155, 170, 265, 360, 240, 120, 83, 45, 28]';% m ^ 3 /人力资源需求= repmat (Demand_mean 1 num_days);需求=需求(:);给需求增加噪音一个= -25;% m ^ 3 /人力资源b = 25;% m ^ 3 /人力资源/ /要求噪声= a + (b-a).*rand(numel(Demand),1);WaterDemand = timeseries(Demand + Demand_noise,t);WaterDemand。Name =“需水量”;结束
重置功能
函数= localResetFcn(中)%使用持久随机种子值来评估代理和基线%控制器在相同条件下。持续的随机种子如果isempty(randomSeed) randomSeed = 0;结束如果比较字符串(在“重置种子”) randomSeed = 0;返回结束randomSeed = randomSeed + 1;rng (randomSeed)%随机用水需求。num_days = 4;H_max = 7;[WaterDemand ~] = generateWaterDemand (num_days);assignin (“基地”,“需水量”WaterDemand)%随机初始高度。h0 = 3 * randn;而h0<=0 | | h0>=H|u max h0=3*randn;结束黑色=“水箱调度/水箱系统/初始水位”;在= setBlockParameter(黑色,“价值”num2str (h0));结束
你也可以从以下列表中选择一个网站:
