基于MFCC和LSTM网络的噪声关键字识别
这个例子展示了如何使用深度学习网络在嘈杂语音中识别关键字。具体来说,该示例使用了双向长短期记忆(BiLSTM)网络和mel频率倒频谱系数(MFCC)。
介绍
关键字识别(KWS)是语音辅助技术的一个重要组成部分,用户在向设备说出完整的命令或查询之前先说出预定义的关键字来唤醒系统。
这个例子训练了一个具有梅尔频率倒谱系数(MFCC)特征序列的KWS深度网络。该示例还演示了如何使用数据增强来提高噪声环境中的网络精度。
这个例子使用了长短期记忆(LSTM)网络,它是一种非常适合研究序列和时间序列数据的递归神经网络(RNN)。LSTM网络可以学习序列时间步长之间的长期依赖关系。LSTM层(lstmLayer(深度学习工具箱))可以在向前方向上看时间序列,而双向LSTM层(bilstmLayer(深度学习工具箱))可以查看向前和向后方向的时间序列。此示例使用双向LSTM层。
该示例使用谷歌语音命令数据集训练深度学习模型。要运行该示例,必须首先下载数据集。如果您不想下载数据集或训练网络,那么您可以通过在MATLAB®中打开此示例并运行示例的3-10行来下载和使用预训练的网络。
与净化网络的点关键字
在详细进入训练过程之前,您将下载并使用预先训练的关键字识别网络来识别关键字。
在本例中,spot的关键字是是的.
读取发出关键字的测试信号。
[audioIn, fs] = audioread(“keywordTestSignal.wav”);声音(audioIn fs)
下载并加载预先训练的网络、用于特征归一化的均值(M)和标准差(S)向量,以及示例中稍后用于验证网络的2个音频文件。
url ='http://ssd.mathworks.com/万博1manbetxsupportfiles/audio/keywordspotting.zip';downloaddnetfolder = tempdir;netfolder = fullfile(downloadnetfolder,“KeywordSpotting”);如果~存在(netFolder“dir”) disp (“下载预先训练的网络和音频文件(4个文件- 7 MB)……”)解压缩(URL,DownloadNetFolder)结束load(fullfile(netfolder,“KWSNet.mat”));
创建一个音频特征提取器对象进行特征提取。
WindowLength=512;OverlapsLength=384;afe=audioFeatureExtractor('采样率'fs,......'窗户',HANN(WindowLength,“周期”),......'overlaplencth'OverlapLength,......“mfcc”,真的,......“mfccDelta”符合事实的......'mfccdeltadelta',真的);
从测试信号中提取特征并进行归一化。
特点=提取(afe audioIn);feature = (feature - M)./S;
计算关键字识别二进制掩码。掩码值为1对应于关键字被标记的段。
掩码= (KWSNet、特点进行分类。');
掩码内的每个样本对应于语音信号(WindowLength-OverlapLength).
将遮罩扩展到信号的长度。
mask = repmat(掩码,windowlength-overlaplenth,1);面膜=双(面膜) - 1;面具=掩码(:);
绘制测试信号和掩模。
FignionIn = AudioIn(1:长度(掩码));t =(0:长度(Auvidin)-1)/ FS;绘图(t,audioin)网格在持有在情节(t,面具)传说(“演讲”,“是的”)

听一听斑点关键词。
声音(audioIn(掩码= = 1),fs)
使用麦克风中的流音频检测命令
在麦克风的流音频上测试预先训练的命令检测网络。试着说一些随机的单词,包括关键词(是的).
称呼generateMATLABFunction在音频特征提取器对象创建特征提取函数。您将在处理循环中使用这个函数。
generateMATLABFunction (afe“generateKeywordFeatures”,“IsStreaming”,真的);
定义一个可以从麦克风读取音频的音频设备阅读器。配置帧长度为跳数长度。这使您能够为麦克风中的每一个新的音频帧计算一组新的特性。
HopLength = WindowLength - OverlapLength;frameLength = hopLength;adr = audiodevicereader('采样率'fs,......“SamplesPerFrame”, FrameLength);
创建语音信号和估计掩码的可视化范围。
范围= timescope('采样率'fs,......“TimeSpanSource”,“属性”,......'时间跨度'5.......“TimeSpanOverrunAction”,“滚动”,......“缓冲长度”fs * 5 * 2,......“ShowLegend”,真的,......“频道名称”, {“演讲”,“关键词面具”},......“YLimits”(-1.2 - 1.2),......“头衔”,关键字定位的);
定义您估计掩码的速率。您将每年生成一次掩码numhopsperupdate.音频帧。
NumHopsPerUpdate = 16;
初始化音频缓冲区。
dataBuff = dsp.AsyncBuffer (WindowLength);
初始化计算特性的缓冲区。
featureBuff=dsp.AsyncBuffer(NumHopsPerUpdate);
初始化缓冲区以管理音频和掩码的绘图。
plotBuff = dsp.AsyncBuffer (NumHopsPerUpdate * WindowLength);
要无限期地运行循环,请将timeLimit设置为Inf。要停止模拟,请关闭范围。
期限= 20;抽搐而toc < timeLimit data = adr();写(dataBuff、数据);写(plotBuff、数据);帧=阅读(dataBuff WindowLength OverlapLength);特点= generateKeywordFeatures(框架、fs);写(featureBuff特性。');如果featureBuff。NumUnreadSamples == NumHopsPerUpdate featureMatrix = read(featureBuff);featureMatrix (~ isfinite (featureMatrix)) = 0;featureMatrix = (featureMatrix - M)./S;[keywordNet, v] = classifyAndUpdateState(KWSNet,featureMatrix.');V = double(V) - 1;v = repmat(v, HopLength, 1);v = (,);v =模式(v);v = repmat(v, NumHopsPerUpdate * HopLength,1); data = read(plotBuff); scope([data, v]);如果~ isVisible(范围)打破;结束结束结束隐藏(范围)

在示例的其余部分中,您将学习如何训练关键字识别网络。
培训过程总结
培训过程包括以下几个步骤:
检查验证信号上的“黄金标准”关键字检测基线。
从无噪声数据集创建训练语音。
使用从这些话语中提取的MFCC序列训练关键字识别LSTM网络。
通过将验证基线与网络输出应用于验证信号时,通过将验证基线进行比较来检查网络准确性。
检查网络的准确性是否有被噪声损坏的验证信号。
通过在语音数据中注入噪声来增强训练数据集
audiodataAugmenter..用增强数据集重新培训网络。
验证再训练后的网络在应用于噪声验证信号时具有更高的精度。
检查验证信号
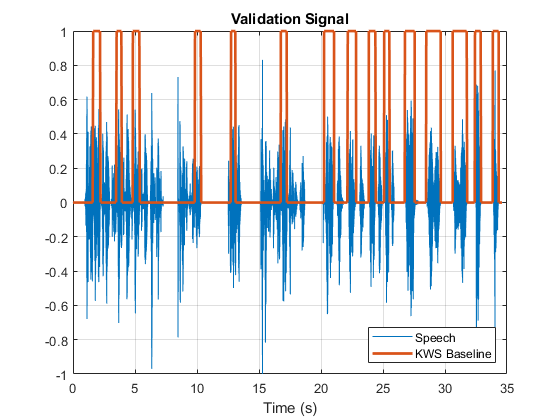
您使用一个样本语音信号来验证KWS网络。验证信号由带有关键字的34秒语音组成是的断断续续地出现。
加载验证信号。
[audioIn, fs] = audioread (fullfile (netFolder,“KeywordSpeech-16-16-mono-34secs.flac”));
听这个信号。
声音(audioIn fs)
可视化的信号。
图T =(1 / FS)*(0:长度(AudioIn)-1);绘图(t,audioin);网格在包含(“时间(s)”)标题(验证语音信号的)

检查KWS基线
加载KWS基线。这个基线是通过使用speech2text:使用音频标签创建关键字识别掩码.
加载(“KWSBaseline.mat”,“KWSBaseline”)
基线是与验证音频信号相同长度的逻辑向量。段audioIn其中关键字被设置为一个在KWSBaseline.
可视化语音信号和KWS基线。
无花果=图;绘图(t,[audioin,kwsbaseline')网格在包含(“时间(s)”) 传奇(“演讲”,KWS基线的,“位置”,“东南”) l = findall(图,“类型”,'线');L(1).LineWidth = 2;标题(“验证信号”)
听被识别为关键字的演讲片段。
声音(AudioIn(kwsbaseline),fs)
你训练的网络的目标是输出一个0和1的KWS掩码,就像这个基线。
加载语音命令数据集
下载并提取谷歌语音命令数据集[1].
url =“https://ssd.mathworks.com/万博1manbetxsupportfiles/audio/google_speech.zip”;downloadFolder = tempdir;datasetFolder = fullfile (downloadFolder,“google_speech”);如果~存在(datasetFolder“dir”) disp (“正在下载谷歌语音命令数据集(1.5 GB)……”解压缩(url, datasetFolder)结束
创建一个audioDatastore这指向了数据集。
广告= audioDatastore (datasetFolder,“LabelSource”,“foldername”,“Includesubfolders”,true);ads=shuffle(ads);
DataSet包含此示例中未使用的后台噪声文件。使用子集创建没有背景噪声文件的新数据存储。
isBackNoise=ismember(广告标签、,“背景”);广告(广告,~ isBackNoise) =子集;
该数据集有大约65,000个一秒长的话语,包含30个短单词(包括关键字YES)。获取数据存储中单词分布的分解。
countEachLabel(广告)
ans =30×2表标签数______ _____床1713鸟1731猫1733狗1746 down 2359 8 2352 5 2357 4 2372 go快乐的房子1750 left 2353马文1746 9 2364 no 2375 off 2357⋮
分裂广告存入两个数据存储:第一个数据存储包含与关键字对应的文件。第二个数据存储包含所有其他单词。
关键词=“是的”;isKeyword = ismember (ads.Labels、关键词);ads_keyword =子集(广告,isKeyword);ads_other =子集(广告,~ isKeyword);
要用整个数据集训练网络,并达到尽可能高的精度,集合reduceDataset到假.要快速运行此示例,请设置reduceDataset到真正的.
reduceDataset =假;如果reduceDataset%将数据集缩减到原来的20倍ads_关键字=splitEachLabel(ads_关键字,圆形(numel(ads_关键字.文件)/20));numUniqueLabels=numel(唯一(ads_其他.标签));ads_其他=splitEachLabel(ads_其他,圆形(numel(ads_其他.文件)/numUniqueLabels/20));结束

获取每个数据存储中单词分布的分解。洗牌的ads_other数据存储,以便连续读取返回不同的字。
CountAckeLabel(ADS_KEYWORD)
ans =1×2表标签计数_____ _____ yes 2377
countEachLabel (ads_other)
ans =29日×2表标签数______ _____床1713鸟1731猫1733狗1746 down 2359 8 2352 5 2357 4 2372 go快乐的房子1750 left 2353马文1746 9 2364 no 2375 off 2357⋮
ads_other = shuffle (ads_other);
创建训练句子和标签
训练数据存储包含一秒语音信号,其中发出一个单词。您将创建更复杂的训练语音,其中包含关键字和其他单词的混合。
下面是一个构造的句子的例子。从关键字数据存储中读取一个关键字,并将其规范化为最大值为1。
是的=阅读(ads_keyword);是=是/ max(abs(Yes));
该信号具有非语音部分(无声、背景噪声等),不包含有用的语音信息。这个例子移除沉默使用detectSpeech.
获取信号的有用部分的开始和结束索引。
speechIndices = detectSpeech(是的,fs);
在合成的训练句子中随机选择单词的数量。最多使用10个单词。
numWords = randi([0 10]);
随机选择关键字出现的位置。
关键词= randi([1 num字+ 1]);
阅读所需数量的非关键字话语,并构建训练句子和掩模。
句子= [];掩码= [];为指数= 1:numWords + 1如果index == keywordLocation句子=[句子;yes];%#好的newMask = 0(大小(是的));newMask (speechIndices (1, 1): speechIndices(1、2))= 1;掩码=[面具;newMask];%#好的其他的其他=阅读(ads_other);else = Other ./ max(abs(Other));句子=(句子,其他);%#好的掩码=[面具;0(大小(其他))];%#好的结束结束
把训练句子和面具一起画出来。
图t = (1/fs) *(0:长度(句子)-1);无花果=图;情节(t,句子,面具)网格在包含(“时间(s)”) 传奇('训练信号',“面具”,“位置”,“东南”) l = findall(图,“类型”,'线');L(1).LineWidth = 2;标题(“话语”)

听下面这句训练句子。
声音(句子,fs)
提取的特征
该示例使用39个MFCC系数(13个MFCC、13个delta和13个delta-delta系数)训练深度学习网络。
定义MFCC提取所需的参数。
windowlength = 512;overtaplength = 384;
创建audioFeatureExtractor对象来执行特征提取。
afe = audioFeatureExtractor ('采样率'fs,......'窗户',HANN(WindowLength,“周期”),......'overlaplencth'OverlapLength,......“mfcc”,真的,......“mfccDelta”,真的,......'mfccdeltadelta',真的);
提取特征。
featureMatrix =提取(afe,句子);大小(featureMatrix)
ans =1×2478年39
注意,您通过滑动一个窗口通过输入来计算MFCC,因此特征矩阵比输入语音信号短。在每一行featureMatrix对应128个语音信号样本(WindowLength-OverlapLength).
计算与掩码长度相同的掩码featureMatrix.
HopLength = WindowLength - OverlapLength;range = HopLength * (1:size(featureMatrix,1)) + HopLength;featureMask = 0(大小(范围);为index = 1:numel(range) featureMask(index) = mode(mask((index-1)*HopLength+1:(index-1)*HopLength+WindowLength));结束
从训练数据集中提取特征
整个训练数据集的句子合成和特征提取可能非常耗时。若要加快处理速度,请使用并行计算工具箱™, 对培训数据存储进行分区,并在单独的辅助进程上处理每个分区。
选择一些数据存储分区。
numpartitions = 6;
初始化特征矩阵和掩模的单元格数组。
TrainingFeatures={};TrainingMasks={};
使用以下命令执行句子合成、特征提取和遮罩创建parfor.
emptyCategories = categorical([1 0]);emptyCategories (:) = [];抽搐parforII = 1:NUMPARTITIONS SUBADS_KEYWORD =分区(ADS_KEYWORD,NUMPRITIONS,II);subads_other = partition(Ads_other,Numpartitions,II);count = 1;localfeatures = cell(length(subads_keyword.files),1);localMasks = cell(length(subads_keyword.files),1);而hasdata(subads_keyword)创造一个训练句子(句子,面具)= HelperSynthesizeSentence (subads_keyword subads_other, fs, WindowLength);%compute mfcc功能特征矩阵=提取(afe,句子);featureMatrix (~ isfinite (featureMatrix)) = 0;%create mask.hopLength = WindowLength - OverlapLength;range = (hopLength) * (1:size(featureMatrix,1)) + hopLength;featureMask = 0(大小(范围);为index = 1:numel(范围)featuremask(index)= mode(mask((index-1)* hoplength + 1 :( index-1)* hoplength + windowlength));结束localFeatures{数}= featureMatrix;localMasks{数}= [emptyCategories,直言(featureMask)];Count = Count + 1;结束TrainingFeatures = [TrainingFeatures; localFeatures];TrainingMasks = [TrainingMasks; localMasks];结束流(“训练特征提取花费了%f秒。\n”toc)
训练特征提取用时33.656404秒。
将所有特征标准化为零平均值和单位标准差是一种良好的做法。计算每个系数的平均值和标准差,并使用它们对数据进行标准化。
sampleFeature = TrainingFeatures {1};numFeatures =大小(sampleFeature, 2);featuresMatrix =猫(1,TrainingFeatures {:});如果reduceDataset加载(fullfile (netFolder'KeywordNetNoAugumentation.mat'),'ContendNetNougmentation',“我是,“年代”);其他的M =意味着(featuresMatrix);S =性病(featuresMatrix);结束为index = 1:length(TrainingFeatures) f = TrainingFeatures{index};f = (f - M) ./ S;TrainingFeatures{指数}= f。';%#好的结束
提取验证特征
从验证信号中提取MFCC特征。
特征矩阵=提取(afe, audioIn);featureMatrix (~ isfinite (featureMatrix)) = 0;
标准化验证功能。
FeaturesValidationClean = (featureMatrix - M)./S;range = HopLength * (1:size(FeaturesValidationClean,1)) + HopLength;
构造验证KWS掩码。
featureMask = 0(大小(范围);为索引= 1:numel(range) featureMask(index) = mode(KWSBaseline((index-1)*HopLength+1:(index-1)*HopLength+WindowLength));结束BaselineV =分类(featureMask);
定义LSTM网络架构
LSTM网络可以学习序列数据时间步长之间的长期依赖关系。本例使用双向LSTM层bilstmLayer(深度学习工具箱)从正反两个方向看这个序列。
指定输入大小为大小序列numfeatures..指定具有150的输出大小的两个隐藏的双向LSTM层并输出序列。此命令指示双向LSTM层将输入时间序列映射到传递到下一层的150个功能。通过包括一个完全连接的大小2层来指定两个类,然后是softmax层和分类层。
层= [......SequenceInputlayer(NumFeatures)BilstMlayer(150,“OutputMode”,“序列”) bilstmLayer (150,“OutputMode”,“序列”) fulllyconnectedlayer (2) softmaxLayer classificationLayer];
定义培训的选项
指定分类器的训练选项。集MaxEpochs到10,使网络使10通过训练数据。集MiniBatchSize到64.这样这个网络一次就能观察64个训练信号。集情节到“培训 - 进展”当迭代次数增加时,生成显示培训进度的地块。集详细的到假禁用打印与图中显示的数据相对应的表输出。集洗牌到“every-epoch”在每个纪元开始时打乱训练顺序。集LearnRateSchedule到“分段”每次经过一定数量的纪元(5)时,将学习率降低指定的系数(0.1)。设置ValidationData到验证预测因子和目标。
本例使用自适应矩估计(ADAM)求解器。ADAM在lstm这样的递归神经网络(RNNs)中比默认的SGDM (SGDM)求解器表现更好。
maxEpochs = 10;miniBatchSize = 64;选择= trainingOptions (“亚当”,......“InitialLearnRate”1的军医,......“MaxEpochs”maxEpochs,......“MiniBatchSize”miniBatchSize,......“洗牌”,“every-epoch”,......“详细”假的,......“验证职业”,地板(numel(培训功能)/小批量尺寸),......“ValidationData”, BaselineV} {FeaturesValidationClean。”......“阴谋”,“培训 - 进展”,......“LearnRateSchedule”,“分段”,......“LearnRateDropFactor”, 0.1,......“LearnRateDropPeriod”5);
训练LSTM网络
使用指定的训练选项和层架构来训练LSTM网络trainNetwork(深度学习工具箱)。由于培训集很大,培训过程可能需要几分钟。
[keywordNetNoAugmentation, netInfo] = trainNetwork (TrainingFeatures、TrainingMasks层,选择);

如果reduceDataset加载(fullfile (netFolder'KeywordNetNoAugumentation.mat'),'ContendNetNougmentation',“我是,“年代”);结束
检查无噪音验证信号的网络精度
使用培训的网络估算验证信号的KWS掩码。
v =分类(keywordNetNoAugmentation FeaturesValidationClean。');
根据实际标签和估计标签的向量计算并绘制验证混淆矩阵。
图cm=混淆图(基线v、v、,“标题”,“验证准确性”);厘米。ColumnSummary =“列规格化”;厘米。RowSummary =“行标准化”;

将网络输出从分类转换为双精度。
V = double(V) - 1;v = repmat (v HopLength 1);v = (,);
听网络识别的关键词区域。
声音(audioIn(逻辑(v)), fs)
可视化估计和预期的KWS口罩。
基线=双(BaselineV) - 1;基线= repmat(基线HopLength 1);基线=基线(:);T = (1/fs) * (0:length(v)-1);无花果=图;情节(t) [audioIn(1:长度(v)), v, 0.8 *基线])网格在包含(“时间(s)”) 传奇('训练信号',“网络掩码”,“基线面具”,“位置”,“东南”) l = findall(图,“类型”,'线'); l(1).线宽=2;l(2)。线宽=2;头衔(“无噪音言论测试结果”)

检查网络精度的噪声验证信号
现在,您将检查网络精度的噪声语音信号。噪声信号是通过加性高斯白噪声破坏验证信号得到的。
加载噪声信号。
[audioInNoisy, fs] = audioread (fullfile (netFolder,'noisykeywordspeech-16-16-mono-34secs.flac'));声音(audioInNoisy fs)
可视化的信号。
图t =(1 / fs)*(0:长度(isausinnoisy)-1);绘图(T,AudioInnoisy)网格在包含(“时间(s)”)标题(“噪声验证语音信号”)

从噪声信号中提取特征矩阵。
featureMatrixV = extract(afe, audioInNoisy);featureMatrixV (~ isfinite (featureMatrixV)) = 0;特点idalidationNoisy =(featurematrixv - m)./ s;
将特征矩阵传递给网络。
v=分类(关键字网络增强、功能验证噪声);
将网络输出与基线进行比较。请注意,精度低于您获得清洁信号的精度。
图cm=混淆图(基线v、v、,“标题”,验证精度-噪声语音);厘米。ColumnSummary =“列规格化”;厘米。RowSummary =“行标准化”;

将网络输出从分类转换为双精度。
V = double(V) - 1;v = repmat (v HopLength 1);v = (,);
听网络识别的关键词区域。
声音(audioIn(逻辑(v)), fs)
可视化估计和基线遮罩。
t = (1 / fs) *(0:长度(v) 1);无花果=图;情节(t) [audioInNoisy(1:长度(v)), v, 0.8 *基线])网格在包含(“时间(s)”) 传奇('训练信号',“网络掩码”,“基线面具”,“位置”,“东南”) l = findall(图,“类型”,'线'); l(1).线宽=2;l(2)。线宽=2;头衔(“噪声语音的结果-无数据增强”)

执行数据扩充
训练后的网络在噪声信号上表现不佳,因为训练后的数据集只包含无噪声的句子。你可以通过扩充你的数据集来包括嘈杂的句子来纠正这一点。
使用audiodataAugmenter.来扩充您的数据集。
ada = audioDataAugmenter (“TimeStretchProbability”0,......“PitchShiftProbability”0,......'VolumeControlProbability'0,......'timeshiftProbability'0,......“SNRRange”,[ - 1,1],......“AddNoiseProbability”, 0.85);
有了这些设置,audiodataAugmenter.对象用白高斯噪声损坏输入音频信号的概率为85%。信噪比从[-1 1]范围内随机选取(以dB为单位)。有15%的概率增益器不修改您的输入信号。
例如,将音频信号传递给增益器。
Reset (ads_keyword) x = read(ads_keyword);data =增加(ada, x, fs)
data =1×2表Audio AugmentationInfo ________________ ________________ {16000×1双} [1×1 struct]
检查AugmentationInfo可变的数据来验证信号是如何被修改的。
数据。AugmentationInfo
ans =结构体字段:信噪比:0.3410
重置数据存储。
重置(ADS_KEYWORD)重置(ADS_OLL)
初始化特性和掩码单元格。
TrainingFeatures = {};TrainingMasks = {};
再次进行特征提取。每个信号被噪声损坏的概率为85%,所以您的增强数据集大约有85%的噪声数据和15%的无噪声数据。
抽搐parforII = 1:NUMPARTITIONS SUBADS_KEYWORD =分区(ADS_KEYWORD,NUMPRITIONS,II);subads_other = partition(Ads_other,Numpartitions,II);count = 1;localfeatures = cell(length(subads_keyword.files),1);localMasks = cell(length(subads_keyword.files),1);而hasdata(subads_keyword) [sentence,mask] = HelperSynthesizeSentence(subads_keyword,subads_other,fs,WindowLength);%损坏噪音augmentedData =增加(ada、句子、fs);句子= augmentedData.Audio {1};%compute mfcc功能特征矩阵=提取(afe,句子);featureMatrix (~ isfinite (featureMatrix)) = 0;hopLength = WindowLength - OverlapLength;range = hopLength * (1:size(featureMatrix,1)) + hopLength;featureMask = 0(大小(范围);为index = 1:numel(范围)featuremask(index)= mode(mask((index-1)* hoplength + 1 :( index-1)* hoplength + windowlength));结束localFeatures{数}= featureMatrix;localMasks{数}= [emptyCategories,直言(featureMask)];Count = Count + 1;结束TrainingFeatures = [TrainingFeatures; localFeatures];TrainingMasks = [TrainingMasks; localMasks];结束流(“训练特征提取花费了%f秒。\n”toc)
训练特征提取耗时36.090923秒。
计算每个系数的平均值和标准差;使用它们来规范化数据。
sampleFeature = TrainingFeatures {1};numFeatures =大小(sampleFeature, 2);featuresMatrix =猫(1,TrainingFeatures {:});如果reduceDataset加载(fullfile (netFolder“KWSNet.mat”),'kwsnet',“我是,“年代”);其他的M =意味着(featuresMatrix);S =性病(featuresMatrix);结束为index = 1:length(TrainingFeatures) f = TrainingFeatures{index};f = (f - M) ./ S;TrainingFeatures{指数}= f。';%#好的结束
使用新均值和标准偏差值标准化验证功能。
特点idalidationNoisy =(featurematrixv - m)./ s;
使用增强数据集的再培训网络
重新创建培训选项。使用噪声基线特性和掩码进行验证。
选择= trainingOptions (“亚当”,......“InitialLearnRate”1的军医,......“MaxEpochs”maxEpochs,......“MiniBatchSize”miniBatchSize,......“洗牌”,“every-epoch”,......“详细”假的,......“验证职业”,地板(numel(培训功能)/小批量尺寸),......“ValidationData”,{featuresvalidationnoised',BaselineV},......“阴谋”,“培训 - 进展”,......“LearnRateSchedule”,“分段”,......“LearnRateDropFactor”, 0.1,......“LearnRateDropPeriod”5);
培训网络。
[KWSNet, netInfo] = trainNetwork (TrainingFeatures、TrainingMasks层,选择);

如果reduceDataset加载(fullfile (netFolder“KWSNet.mat”));结束
验证验证信号的网络准确性。
v =分类(KWSNet FeaturesValidationNoisy。');
比较估计和预期的KWS掩码。
图cm=混淆图(基线v、v、,“标题”,“数据增强的验证准确性”);厘米。ColumnSummary =“列规格化”;厘米。RowSummary =“行标准化”;

监听已识别的关键字区域。
V = double(V) - 1;v = repmat (v HopLength 1);v = (,);声音(audioIn(逻辑(v)), fs)
可视化估计和预期的面具。
无花果=图;情节(t) [audioInNoisy(1:长度(v)), v, 0.8 *基线])网格在包含(“时间(s)”) 传奇('训练信号',“网络掩码”,“基线面具”,“位置”,“东南”) l = findall(图,“类型”,'线'); l(1).线宽=2;l(2)。线宽=2;头衔(“噪声语音的结果-数据增强”)

工具书类
[1] Warden P.“语音命令:用于单词语音识别的公共数据集”,2017.可从中获取https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz..版权2017年谷歌。语音命令数据集是在知识共享署名4.0许可下使用的。
附录-辅助功能
函数(句子,面具)= HelperSynthesizeSentence (ads_keyword ads_other, fs,最小长度)%读取一个关键字关键词=阅读(ads_keyword);/ max(abs(关键字));%确定感兴趣的区域speechIndices = detectSpeech(关键字、fs);如果isempty(语音indices)||diff(语音indices(1,:))<= minlength语音indices = [1,长度(关键字)];结束关键词=关键字(speechIndices (1,1): speechIndices(1、2);%随机选择一个其他单词的数字(0到10之间)numWords = randi([0 10]);%选择插入关键字的位置loc = randi([1 numWords+1]);句子= [];掩码= [];为指数= 1:numWords + 1如果index == loc句子= [句子;关键词];newmask = size(大小(关键字));面具= [蒙面; newmask];其他的其他=阅读(ads_other);else = Other ./ max(abs(Other));句子=(句子,其他);掩码=[面具;0(大小(其他))];结束结束结束
你也可以从以下列表中选择一个网站: