使用并行计算和GPU的火车代理
如果您有并行计算工具箱™软件,则可以在多核处理器或GPU上运行并行模拟。如果你另外有马铃薯草®并行服务器™软件,您可以在计算机集群或云资源上运行并行模拟。
独立于您用于模拟或培训代理的设备,一旦代理培训,您可以生成代码以在CPU或GPU上部署最佳策略。这是更详细的解释的部署培训的强化学习政策。
使用多个进程
使用并行计算的培训代理时,并行池客户端(启动培训的MATLAB进程)将其代理和环境的副本发送给每个并行工作者。每个工人在环境中模拟代理,并将其模拟数据发送回客户端。客户端代理从工人发送的数据中学习,并将更新的策略参数发送回工人。
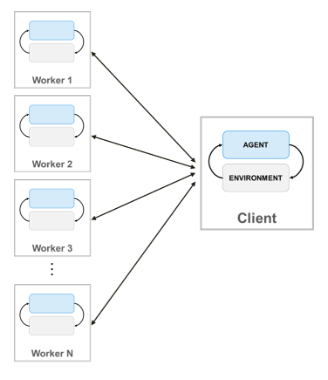
创建一个平行的池N.工人,使用以下语法。
池= parpool (N);
如果您没有使用并行池使用parpool.(并行计算工具箱), 这火车函数使用默认的并行池首选项自动创建一个。有关指定这些首选项的更多信息,请参见指定您的并行偏好(并行计算工具箱)。请注意,使用并行线程工人池,例如池= parpool(“线程”),不受支持。万博1manbetx
要使用多个进程培训代理,您必须传递给火车功能A.rltringOptions.其中的对象使用指α.被设定为真正的。
有关配置培训的更多信息,请使用并行计算,查看使用指α.和并行化选项选项rltringOptions.。
请注意,不支持并行模拟和培训包含多个代理的环境。万博1manbetx
有关使用Matlab中使用并行计算的代理的示例,请参阅火车AC代理使用并行计算平衡车杆系统。有关使用Simulink中使用并行计算的代理进行培训的示例万博1manbetx®, 看使用并行计算的车道保持辅助列车DQN代理和培训双边机器人使用加强学习代理行走。
代理专用的并行培训考虑因素
对于非策略代理,如DDPG和DQN代理,不要将所有核心都用于并行训练。例如,如果您的CPU有6个核,那么使用4个worker进行培训。这样做可以为并行池客户端提供更多的资源,以便根据从工作人员返回的经验计算梯度。当在worker上计算梯度时,对于策略上的代理(如AC和PG代理),没有必要限制worker的数量。
基于梯度的并行化(AC和PG代理)
并行训练AC和PG代理,DataToSendFromWorkers财产的并行训练必须设置对象(包含在培训选项对象中)“梯度”。
这配置了培训,以便工人完成环境模拟和渐变计算。具体而言,Workers模拟了对环境的代理,从体验中计算渐变,并将渐变发送给客户端。客户端平均渐变,更新网络参数,并将更新的参数发送回工作人员,可以继续使用新参数模拟代理。
通过基于梯度的并行化,您可以原则上实现速度改进,这几乎是工人数量的线性。但是,此选项需要同步培训(即模式财产的rltringOptions.你传递给的对象火车函数必须设置为“同步”)。这意味着工人必须暂停执行,直到所有工人完成,并且由于最慢的工人允许,培训只能快速进步。
当AC代理并行训练时,如果numsteptolookahead.AC代理选项对象的属性和stpeptuntildataissent.财产的并行化选项对象设置为不同的值。
基于体验的并行化(DQN,DDPG,PPO,TD3和SAC代理)
培训DQN,DDPG,PPO,TD3和SAC代理并行,DataToSendFromWorkers财产的并行化选项必须设置对象(包含在培训选项对象中)“经验”。此选项不需要同步培训(即模式财产的rltringOptions.你传递给的对象火车功能可以设置为“异步”)。
这配置了培训,以便环境仿真由工人完成,学习由客户端完成。具体而言,工人模拟了对环境的代理,并向客户端发送经验数据(观察,动作,奖励,下一个观察和终端信号)。然后,客户端从体验中计算梯度,更新网络参数并将更新的参数发送回工地,然后继续使用新参数模拟代理。
基于体验的并行化只有在模拟环境的计算成本与优化网络参数的成本相比,才能降低训练时间。否则,当环境模拟足够快时,工人闲置等待客户学习并发送更新的参数。
换句话说,基于体验的并行化可以仅在比率时提高样本效率(拟是代理可以在给定时间内处理的样本数量)R.环境步长复杂度与学习复杂度之间存在较大差异。如果环境模拟和学习的计算成本相似,那么基于经验的并行化不太可能提高样本效率。但是,在这种情况下,对于非策略代理,您可以减少迷你批处理的大小R.较大,从而提高样品效率。
在培训DQN,DDPG,TD3或SAC代理并行时,在体验缓冲区中强制执行续,设置numstepstolookahead.属性或相应的代理选项对象1。尝试并行培训时,不同的值会导致错误。
使用GPU.
使用深度神经网络功能近似器的演员或批评者表示,您可以通过在本地GPU上执行表示操作(例如渐变计算和预测)而不是CPU来加速培训。为此,在创建评论家或演员表示时,请使用rlrepresentationOptions.对象,其中usemerevice.选项设置为“GPU”代替“中央处理器”。
opt = rlrepresentationOptions('moundmevice'那“GPU”);
这“GPU”选项需要并行计算工具箱软件和CUDA®启用nvidia.®GPU。有关支持的GPU的更多信息,请参阅万博1manbetxGPU通万博1manbetx过发布支持(并行计算工具箱)。
您可以使用GPudevice.(并行计算工具箱)查询或选择要与MATLAB一起使用的本地GPU设备。
当行动者或批评者表示中的深度神经网络在输入图像上使用多个卷积层或具有大批量时,使用gpu可能是有益的。
有关如何使用GPU培训代理人的示例,请参阅培训DDPG代理以摇摆和平衡钟摆的图像观察。
使用多个进程和GPU
您还可以使用多个进程和本地GPU培训代理(以前选择使用GPudevice.(并行计算工具箱)) 同时。具体来说,您可以使用一个批评者或演员rlrepresentationOptions.对象,其中usemerevice.选项设置为“GPU”。然后,您可以使用批评者和演员创建代理,然后使用多个进程培训代理。这是通过创建一个rltringOptions.其中的对象使用指α.被设定为真正的然后把它传递给火车功能。
对于基于梯度的并行化,(必须以同步模式运行),环境模拟由工人完成,该工人使用它们本地GPU计算梯度并执行预测步骤。然后将梯度发送回并行池客户端进程,该过程计算平均值,更新网络参数并将它们发送回工人,以便继续使用新参数来模拟代理,并与环境一起模拟代理。
对于基于经验的并行化(可以在异步模式中运行),工人模拟了对环境的代理,并将体验数据发送回并行池客户端。然后,客户端使用其本地GPU从体验中计算渐变,然后更新网络参数,并将更新的参数发送回工地,然后继续使用新参数模拟代理的工人,以与环境一起模拟代理。
请注意,当使用并行处理和GPU培训PPO代理时,工人使用本地GPU来计算优势,然后将处理经验轨迹(包括优势,目标和动作概率)返回给客户端。
也可以看看
火车|rltringOptions.|rlrepresentationOptions.
相关的话题
您还可以从以下列表中选择一个网站: