训练生成对抗网络(GAN)进行声音合成
此示例显示如何培训和使用生成的对冲网络(GaN)来生成声音。
介绍
在生成对抗网络中,生成器和鉴别器相互竞争以提高生成质量。
gan在音频和语音处理领域产生了重要的兴趣。应用包括文本到语音合成、语音转换和语音增强。
该示例列举了一个GAN,用于无监督的音频波形的合成。该示例中的GaN生成了Drumbeat声音。可以遵循相同的方法来生成其他类型的声音,包括语音。
用预先培训的GaN合成音频
在你从头开始训练氮化镓之前,你将使用一个预先训练过的氮化镓发生器来合成鼓点。
下载预先训练过的发电机。
matFileName =“drumGeneratorWeights.mat”;如果〜存在(matfilename,“文件”) websave (matFileName'//www.tianjin-qmedu.com/万博1manbetxsupportfiles/audio/ganaudiosynest/drumgeneratorwights.mat');结尾
这个函数合成仪器调用一个预先训练过的网络来合成以16千赫采样的鼓点。这合成仪器函数包含在此示例的末尾。
综合叫醒并听取它。
鼓= synthesizeDrumBeat;fs = 16 e3;声音(鼓,fs)
绘制合成鼓点。
t =(0:长度(鼓)-1)/ fs;绘图(T,鼓)网格在包含(“时间(s)”)标题('合成鼓击败'的)
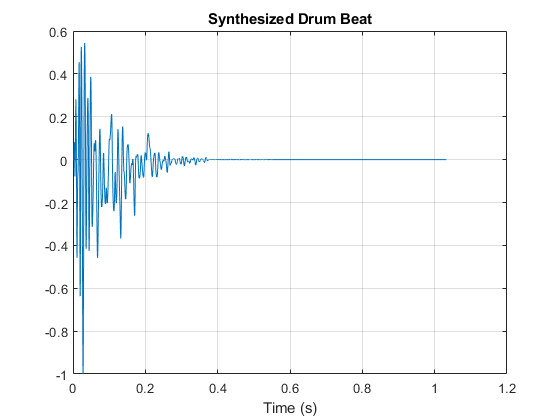
您可以使用鼓点合成器和其他音频效果来创建更复杂的应用程序。例如,您可以在合成的鼓点上应用混响。
创建一个反射器对象并打开其参数调谐器UI。此UI使您可以调整反射器参数作为模拟运行。
混响=反射器(“SampleRate”fs);parameterTuner(混响);
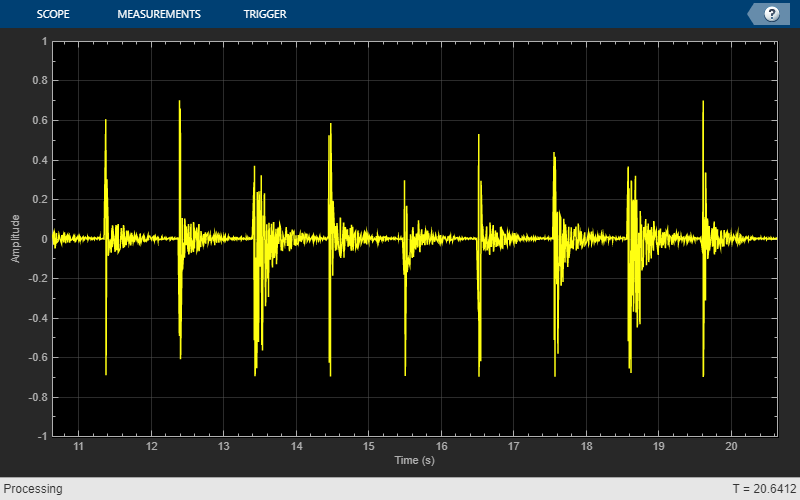
创建一个时间范围对象来可视化鼓点。
ts = timescope(“SampleRate”,fs,...'timespansource'那“属性”那...“TimeSpanOverrunAction”那“滚动”那...“时间间隔”10...“BufferLength”, 10 * 256 * 64,...“ShowGrid”,真的,...'ylimits'[1]);
在一个循环中,合成鼓点并应用混响。使用参数调谐器UI调整混响。如果希望长时间运行模拟,请增加loopCount参数。
loopCount = 20;为了ii = 1:loopCount drum = synthesizeDrumBeat;鼓=混响(鼓);ts(鼓(:1));soundsc(鼓,fs)暂停(0.5)结尾
火车的氮化镓
现在您已经看到了预先训练的鼓点生成器的作用,您可以详细研究训练过程。
GaN是一种深入学习网络,可以生成具有与训练数据类似的特性的数据。
甘包括两个网络一起训练的网络,一个发电机和一个鉴频器:
生成器——给定一个向量或随机值作为输入,该网络生成与训练数据相同结构的数据。欺骗鉴别器是生成器的工作。
鉴别者 - 给定批次包含训练数据和生成数据的观察的数据,这个网络试图将观察分类为真实或生成的观察。
为了最大化发电机的性能,在给定数据时最大化鉴别器的丢失。也就是说,发电机的目的是生成鉴别器将其作为真实分类的数据。为了最大限度地提高鉴别器的性能,在给定批次的真实和生成的数据时,最小化判别符的丢失。理想情况下,这些策略导致发电机产生令人信服的现实数据和具有学习的强大特征表示的鉴别者,该数据具有培训数据的特征。
在本例中,您训练生成器创建鼓点的假时频短时傅立叶变换(STFT)表示。你训练鉴别器来识别真正的STFTs。您可以通过计算真实鼓点节拍的短录音的STFT来创建真正的STFT。
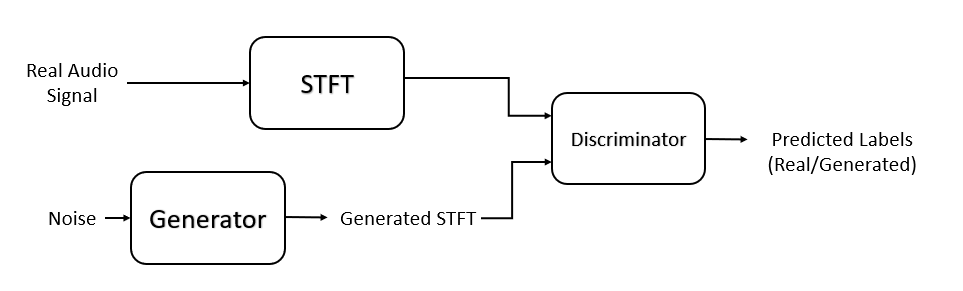
负荷训练数据
使用鼓声效果数据集[1]训练GAN。下载并提取数据集。
url =“http://deepyeti.ucsd.edu/cdonahue/wavegan/data/drums.tar.gz”;downloadfolder = tempdir;filename = fullfile(downloadFolder,“drums_dataset.tgz”);drumsFolder = fullfile (downloadFolder,“鼓”);如果~存在(drumsFolder“dir”)disp(“下载鼓声效果数据集(218mb)…”)WebSave(Filename,URL);Untar(文件名,DownloadFolder)结尾
创建一个audiodatastore.对象,该对象指向鼓数据集。
广告= audioDatastore (drumsFolder,“IncludeSubfolders”,真正的);
定义生成器网络
定义一个网络,从1 × 1 × 100的随机值数组生成STFTs。创建一个网络,将1乘1乘100的数组升级为128乘128乘1的数组,使用的是一个完全连接层,然后是一个重塑层和一系列带有ReLU层的转置卷积层。
这个图显示了信号通过发生器时的尺寸。发电机架构定义在[1]的表4中。
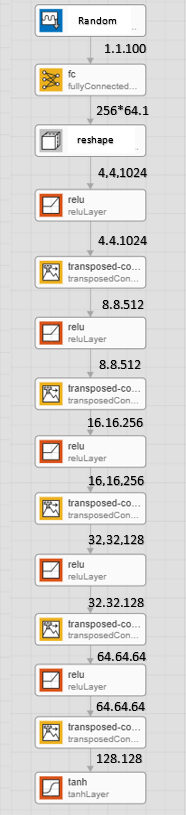
发电机网络定义在ModelGenerator.,包括在此示例结束时。
定义鉴别器网络
定义一个网络,对真实的和生成的128 × 128 STFTs进行分类。
创建一个需要128×128图像的网络,并使用一系列卷积层输出标量预测分数,泄漏的Relu层后跟完全连接的图层。
这张图显示了信号通过鉴别器时的尺寸。鉴别器架构在[1]的表5中定义。

鉴别器网络已定义modeldiscriminator.,包括在此示例结束时。
生成真正的Drumbeat培训数据
从数据存储中的鼓点信号生成STFT数据。
定义STFT参数。
FFTLength = 256;Win = Hann(FFTLength,'定期');overtaplength = 128;
为了加快处理速度,将特征提取分散到多个使用par.
首先,确定数据集的分区数。如果您没有并行计算工具箱™,请使用单个分区。
如果〜isempty(ver('平行线'))池= GCP;numpar = numpartitions(广告,池);别的numpar = 1;结尾
对于每个分区,从数据存储中读取并计算STFT。
parII = 1:numpar subds = partition(广告,numpar,ii);应变=零(FFTLength / 2 + 1,128,1,Numel(Subds.Files));为了idx = 1:numel(subds.files)x =读取(subds);如果长度(x) > fftLength * 64如果太短,%延长了信号x = x (1: fftLength * 64);结尾%从双精度转换为单精度x =单(x);比例信号X = X ./ max(abs(X));%零垫以确保STFT返回128窗口。x = [x;零(overtaplenth,1,“喜欢”, x));S0 = stft (x,“窗口”,赢了,“OverlapLength”,overtaplenth,'中心'、假);%从双面转换为单面。s = s0(1:129,:);s = abs(s);应变(::::,IDX)= S;结尾STrainC{2} =应变;结尾
将输出转换为四维阵列,沿着第四维度的STFT。
应变=猫(4,STrainC {:});
将数据转换为日志比例以更好地与人类感知对齐。
= log(STrain + 1e-6);
将训练数据标准化为零平均值和单位标准偏差。
计算每个频率箱的STF均值和标准偏差。
SMean = mean(STrain,[2 3 4]);std = std(菌株,1,[2 3 4]);
将每个频率仓归一化。
菌株=(菌株 - Smean)./ SSTD;
计算的STFT具有无限的值。在[1]中的方法之后,通过将光谱剪切至3个标准偏差并重新扫描到[-11]来进行界定的数据。
应变=应变/ 3;Y =重塑(应变、元素个数(应变),1);Y (Y < 1) = 1;Y (Y > 1) = 1;应变=重塑(Y,大小(应变));
丢弃最后一个频率箱,以强制STFT垃圾箱的数量为两个(与卷积层很好)。
张力= (1:end-1,:,::);
排列尺寸,准备馈送到鉴别器。
菌株=润滑(菌株,[2 1 3 4]);
指定培训选项
迷你批量大小为64欧元的火车。
maxEpochs = 1000;miniBatchSize = 64;
计算使用数据所需的迭代次数。
NumiterationsPerePoch =楼层(尺寸(菌株,4)/小匹匹匹匹匹匹配);
指定Adam优化的选项。设置生成器和鉴别器的学习速率为0.0002.对于两个网络,使用梯度衰减系数为0.5和平方梯度衰减系数为0.999。
learnRateGenerator = 0.0002;learnRateDiscriminator = 0.0002;gradientDecayFactor = 0.5;squaredGradientDecayFactor = 0.999;
在GPU上列车,如果有一个可用。使用GPU需要并行计算工具箱™。
ExecutionEnvironment =.“汽车”;
初始化生成器和标识符权重。这initializeGeneratorWeights和初始化的讽刺重量函数返回使用gloot均匀初始化获得的随机权值。本示例的最后包含了这些函数。
generatorParameters = initializeGeneratorWeights;discriminatorParameters = initializeDiscriminatorWeights;
火车模型
使用自定义训练循环训练模型。在每次迭代时循环训练数据并更新网络参数。
对于每个时代,将培训数据和循环换过迷你批次的数据。
对于每个迷你批处理:
生成一个
dlarray.对象,该对象包含生成器网络的随机值数组。对于GPU训练,将数据转换为
gpuArray(并行计算工具箱)对象。使用模型梯度使用
dlfeval(深度学习工具箱)辅助函数,modelDiscriminatorGradients和modelGeneratorGradients.使用介绍网络参数
adamupdate(深度学习工具箱)功能。
初始化Adam的参数。
trailingAvgGenerator = [];trailingAvgSqGenerator = [];trailingAvgDiscriminator = [];trailingAvgSqDiscriminator = [];
你可以设置SaveCheckPoints.来真正的将更新的权重和状态保存到垫文件每十个时期。然后,如果它被中断,您可以使用此MAT文件恢复培训。出于此示例的目的,设置SaveCheckPoints.来错误的.
savecheckpoints = false;
指定发电机输入的长度。
numLatentInputs = 100;
训练甘。这可能需要多个小时才能运行。
迭代= 0;为了时代= 1:maxEpochs%洗牌数据。idx = randperm(大小(压力,4));张力= (:,:,:,idx);%循环小批。为了index = 1:numIterationsPerEpoch iteration = iteration + 1;%读取小批数据。DLX =应变(:,:,:(索引-1)*小型匹配+ 1:索引*小匹匹配);dlx = dlarray(dlx,“SSCB”);为发电机网络产生潜在的输入。Z = 2 * (rand(1,1,numLatentInputs,miniBatchSize,“单一”) - 0.5);dlz = dlarray(z);%如果在GPU上训练,则将数据转换为gpuArray。如果(executionEnvironment = =“汽车”&& canusegpu)||executionenvironment ==.“图形”DLZ = GPUARRAY(DLZ);dlx = gpuarray(dlx);结尾%使用dlfeval和dlfeval评估鉴别器梯度% |modelDiscriminatorGradients| helper函数。梯度Discriminator =...dlfeval (@modelDiscriminatorGradients discriminatorParameters、generatorParameters dlX, dlZ);%更新标识器网络参数。[鉴别者参数,trailingavgdiscriminator,trailingavgsqdiscriminator] =...adamupdate (discriminatorParameters gradientsDiscriminator,...trailingavgdiscriminator,trailingavgsqdiscriminator,迭代,...学习iscriminator,梯度adecayfactor,squaredgradientdecayfactor);为发电机网络产生潜在的输入。Z = 2 * (rand(1,1,numLatentInputs,miniBatchSize,“单一”) - 0.5);dlz = dlarray(z);%如果在GPU上训练,则将数据转换为gpuArray。如果(executionEnvironment = =“汽车”&& canusegpu)||executionenvironment ==.“图形”DLZ = GPUARRAY(DLZ);结尾使用dlfeval和% |modelGeneratorGradients| helper函数。渐变Generator =...dlfeval(@ modelgeneratorgradients,coldiminatorparameters,generatorparameters,dlz);%更新生成网络参数。[GeneratorParameters,TrailingAvggenerator,TrailingAvgsqgenerator] =...adamupdate (generatorParameters gradientsGenerator,...trailingAvgGenerator trailingAvgSqGenerator,迭代,...LearnAtrategenerator,GradientDecayfactor,SquaredgradientDecayfactor);结尾%每10次迭代,保存一个训练快照到MAT文件。如果saveCheckpoints && mod(epoch,10)==0 fprintf('Epoch %d out %d complete\n'时代,maxEpochs);%在训练中断时保存检查点。节省(“audiogancheckpoint.mat”那...'GeneratorParameters'那“discriminatorParameters”那...“trailingAvgDiscriminator”那'trailingavgsqdiscriminator'那...“trailingAvgGenerator”那'trailingavgsqgenerator'那“迭代”);结尾结尾
合成的声音
现在您已培训网络,您可以更详细地调查合成过程。

经过训练的鼓点发生器从随机值的输入数组中合成短时傅里叶变换(STFT)矩阵。逆STFT (ISTFT)操作将时频STFT转换为合成的时域音频信号。
加载预制发电机的重量。通过在上一节中突出显示的训练获得1000个时期的训练来获得这些重量。
负载(matFileName'GeneratorParameters'那“SMean”那“SStd”);
生成器使用1 × 1 × 100的随机值向量作为输入。生成一个样本输入向量。
numLatentInputs = 100;dlZ = dlarray(2 * (rand(1,1,numLatentInputs,1, 1))“单一”) - 0.5);
将随机向量传递给生成器以创建STFT图像。generatorParameters是一个包含预先训练过的发电机重量的结构。
DLXGenerated = ModelGenerator(DLZ,GeneratorParameters);
把STFTdlarray.到一个单精度矩阵。
S = dlXGenerated.extractdata;
转置STFT使其尺寸与istft功能。
=年代。”;
STFT是128×128矩阵,其中第一维度表示128频率箱从0到8kHz线性间隔开。发电机被训练以产生从256的FFT长度的单面STFT,省略最后一个箱。通过将一排零插入StFT来重新引入该垃圾箱。
S = [S;零(1,128)];
还原生成用于训练的STFTs时使用的归一化和缩放步骤。
s = s * 3;S =(S. * SSTD)+ SMEN;
将STFT从对数域转换为线性域。
s = exp(s);
将STFT从单面转换为双面。
S =[年代;S (end-1: 1:2,)];
带零的垫,以删除窗口边缘效果。
S = [0 (256,100) S 0 (256,100)];
STFT矩阵不包含任何相位信息。使用快速版本的Griffin-Lim算法与20次迭代估计信号相位和产生音频样本。
MyAudio = Stftmag2sig(S,256,...“FrequencyRange”那'twosiding'那...“窗口”损害(256,'定期'),...“OverlapLength”, 128,...'发光', 20岁,...“方法”那“fgla”);myAudio = myAudio. / max (abs (myAudio), [],'全部');myAudio = myAudio(128 * 100:结束- 128 * 100);
倾听合成的Drubeat。
声音(myAudio fs)
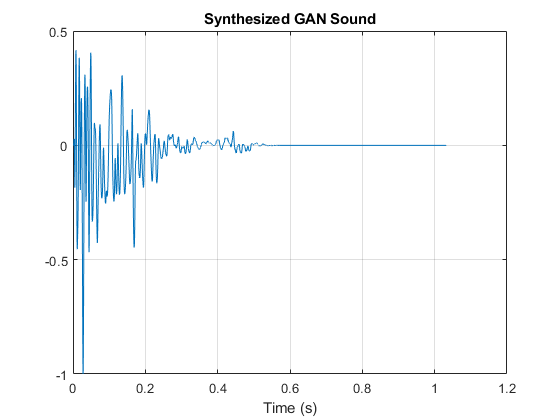
绘制合成鼓点。
t =(0:长度(myAudio) 1) / fs;情节(t, myAudio)网格在包含(“时间(s)”)标题('综合甘蓝'的)
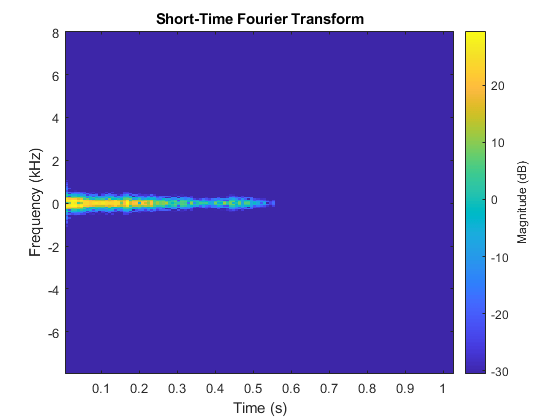
绘制合成鼓点的短时傅立叶变换图。
图Stft(MyAudio,FS,“窗口”损害(256,'定期'),“OverlapLength”,128);
模型发生器功能
这ModelGenerator.函数Upscales 1×1×100阵列(DLX)至128-by-128-1阵列(DLY)。参数是保持发电机层的重量的结构。发电机架构定义在[1]的表4中。
函数dly = modelGenerator(DLX,参数)DLY =全连接(DLX,Parameters.fc.weights,parameters.fc.bias,“Dataformat”那“SSCB”);dly =重塑(dly,[1024 4 4尺寸(dly,2)]);dly =润滑(dly,[3 2 1 4]);海底= relu(海底);dly = dltranspconv(dly,parameters.conv1.weights,parameters.conv1.bias,'走吧'2,“种植”那“相同”那“DataFormat”那“SSCB”);海底= relu(海底);海底= dltranspconv(海底,parameters.Conv2.Weights parameters.Conv2.Bias,'走吧'2,“种植”那“相同”那“DataFormat”那“SSCB”);海底= relu(海底);dly = dltranspconv(dly,parameters.conv3.weights,parameters.conv3.bias,'走吧'2,“种植”那“相同”那“DataFormat”那“SSCB”);海底= relu(海底);海底= dltranspconv(海底,parameters.Conv4.Weights parameters.Conv4.Bias,'走吧'2,“种植”那“相同”那“DataFormat”那“SSCB”);海底= relu(海底);dly = dltranspconv(dly,parameters.conv5.weights,parameters.conv5.bias,'走吧'2,“种植”那“相同”那“DataFormat”那“SSCB”);dly = tanh(dly);结尾
模型鉴别器函数
这modeldiscriminator.功能需要128×128图像并输出标量预测分数。鉴别器架构在[1]的表5中定义。
函数dlY = modelDiscriminator(dlX, parameter1 . weights, parameter1 . bias,'走吧'2,“填充”那“相同”);海底= leakyrelu(海底,0.2);海底= dlconv(海底,parameters.Conv2.Weights parameters.Conv2.Bias,'走吧'2,“填充”那“相同”);海底= leakyrelu(海底,0.2);海底= dlconv(海底,parameters.Conv3.Weights parameters.Conv3.Bias,'走吧'2,“填充”那“相同”);海底= leakyrelu(海底,0.2);海底= dlconv(海底,parameters.Conv4.Weights parameters.Conv4.Bias,'走吧'2,“填充”那“相同”);海底= leakyrelu(海底,0.2);海底= dlconv(海底,parameters.Conv5.Weights parameters.Conv5.Bias,'走吧'2,“填充”那“相同”);海底= leakyrelu(海底,0.2);dly = stripdims(dly);dly =润滑(dly,[3 2 1 4]);dly =重塑(dly,4 * 4 * 64 * 16,numel(dly)/(4 * 4 * 64 * 16));权重= parameters.fc.weights;bias = parameters.fc.bias;dly =全协调(dly,重量,偏见,“Dataformat”那“CB”);结尾
模型鉴别器梯度函数
这modelDiscriminatorGradients函数接受生成器和鉴别器参数作为输入generatorParameters和discriminatorParameters,输入数据的一小批DLX.,以及一个随机值数组DLZ.,并返回鉴别器损耗相对于网络中可学习参数的梯度。
函数梯度DiScriminator = ModeldiscriminatorGradients(鉴别者参数,GeneratorParameters,DLX,DLZ)%计算使用鉴别器网络的实际数据的预测。dlYPred = modelDiscriminator (dlX discriminatorParameters);%用鉴别器网络计算生成数据的预测。DLXGenerated = ModelGenerator(DLZ,GeneratorParameters);dlypredgenerated = modeldiscriminator(Dlarray(Dlxgenerated,“SSCB”), discriminatorParameters);%计算氮化镓损耗lossDiscriminator = ganDiscriminatorLoss (dlYPred dlYPredGenerated);%对于每个网络,计算相对于损失的梯度。梯度Discriminator = Dlgradient(损失DiScriminator,ColdiminatorParameters);结尾
模型生成器梯度函数
这modelGeneratorGradients函数接受鉴别器和生成器可学习参数和随机值数组作为输入DLZ.,并返回发电机损耗相对于网络中可学习参数的梯度。
函数渐变Generator = ModelGeneratorGradients(鉴别者参数,GeneratorParameters,DLZ)%用鉴别器网络计算生成数据的预测。DLXGenerated = ModelGenerator(DLZ,GeneratorParameters);dlypredgenerated = modeldiscriminator(Dlarray(Dlxgenerated,“SSCB”), discriminatorParameters);%计算氮化镓损耗损失Generator = Gangenerlasloss(Dlypredgenerated);%对于每个网络,计算相对于损失的梯度。gradientsGenerator = dlgradient(losgenerator, generatorParameters);结尾
鉴频器损失函数
鉴别器的目的是不被生成器愚弄。为了最大限度地提高鉴别器在真实图像和生成图像之间成功鉴别的概率,最小化鉴别器损失函数。生成器的损失函数遵循[1]中突出显示的DCGAN方法。
函数lossDiscriminator = ganDiscriminatorLoss(dlYPred,dlYPredGenerated) fake = dlarray(zeros(1,size(dlYPred,2))));真正的= dlarray(的(1、大小(dlYPred 2)));D_loss =意味着(sigmoid_cross_entropy_with_logits (dlYPredGenerated、假));D_loss = D_loss + mean(sigmoid_cross_entropy_with_logits(dlYPred,real));lossDiscriminator = D_loss / 2;结尾
发电机损失函数
生成器的目标是生成鉴别器分类为“真实”的数据。为了最大限度地提高来自发生器的图像被鉴别器分类为真实图像的概率,最小化发生器损失函数。生成器的损失函数遵循[1]中强调的深度卷积生成对抗网络(DCGAN)方法。
函数lossGenerator = ganGeneratorLoss(dlYPredGenerated) real = dlarray(ones(1,size(dlYPredGenerated,2)));lossGenerator =意味着(sigmoid_cross_entropy_with_logits (dlYPredGenerated,实际));结尾
鉴频器权值初始化
初始化的讽刺重量使用gloria算法初始化鉴别器权值。
函数discriminatorParameters = initializeDiscriminatorWeights filterSize = [5 5];昏暗的= 64;% Conv2D权重= iGlorotInitialize([filterSize(1) filterSize(2) 1 dim]); / /初始化偏见= 0(1,- 1,昏暗,“单一”);discriminatorParameters.Conv1。重量= dlarray(重量);discriminatorParameters.Conv1。偏见= dlarray(偏差);% Conv2Dweights = iGlorotInitialize([filterSize(1) filterSize(2) dim 2*dim]); / /指定权重偏见=零(1,1,2 *昏暗,“单一”);discriminatorParameters.Conv2。重量= dlarray(重量);discriminatorParameters.Conv2。偏见= dlarray(偏差);% Conv2Dweights = iGlorotInitialize([filterSize(1) filterSize(2) 2*dim 4*dim]); / /指定权重偏见= 0(1、1、4 *昏暗,“单一”);discriminatorParameters.Conv3。重量= dlarray(重量);discriminatorParameters.Conv3。偏见= dlarray(偏差);% Conv2Dweights = iGlorotInitialize([filterSize(1) filterSize(2) 4*dim 8*dim]); / /设置权重偏见= 0(1 1 8 *昏暗,“单一”);discriminatorParameters.Conv4。重量= dlarray(重量);discriminatorParameters.Conv4。偏见= dlarray(偏差);% Conv2Dweights = iGlorotInitialize([filterSize(1) filterSize(2) 8*dim 16*dim]); / /设置权重偏见=零(1,1,16 *昏暗,“单一”);isciminatorparameters.conv5.weights = dlarray(重量);isciminatorParameters.conv5.bias = dlarray(偏见);%完全连接重量= iglorotinitialize([1,4 * 4 * dim * 16]);bias = zeros(1,1,“单一”);discriminatorParameters.FC.Weights = dlarray(重量);discriminatorParameters.FC.Bias = dlarray(偏差);结尾
发电机权重的初始值设定项
initializeGeneratorWeights使用gloria算法初始化生成器权重。
函数GeneratorParameters = InitializeGenerator重量Dim = 64;%的1重量= iGlorotInitialize((暗* 256100));偏见= 0(暗* 256 1“单一”);generatorParameters.FC.Weights = dlarray(重量);generatorParameters.FC.Bias = dlarray(偏差);filterSize = [5 5];%反式Conv2Dweights = iGlorotInitialize([filterSize(1) filterSize(2) 8*dim 16*dim]); / /设置权重偏见= 0(1,- 1,昏暗的* 8,“单一”);generatorParameters.Conv1。重量= dlarray(重量);generatorParameters.Conv1。偏见= dlarray(偏差);%反式Conv2Dweights = iGlorotInitialize([filterSize(1) filterSize(2) 4*dim 8*dim]); / /设置权重BIAS =零(1,1,DIM * 4,“单一”);generatorParameters.Conv2。重量= dlarray(重量);generatorParameters.Conv2。偏见= dlarray(偏差);%反式Conv2Dweights = iGlorotInitialize([filterSize(1) filterSize(2) 2*dim 4*dim]); / /指定权重偏见= 0(1,1,昏暗的* 2,“单一”);GeneratorParameters.conv3.weights = Dlarray(重量);generatorparameters.conv3.bias = dlarray(偏见);%反式Conv2Dweights = iGlorotInitialize([filterSize(1) filterSize(2) dim 2*dim]); / /指定权重偏见= 0(1,- 1,昏暗,“单一”);generatorParameters.Conv4。重量= dlarray(重量);generatorParameters.Conv4。偏见= dlarray(偏差);%反式Conv2D权重= iGlorotInitialize([filterSize(1) filterSize(2) 1 dim]); / /初始化偏见= 0 (1,1,1,“单一”);generatorParameters.Conv5。重量= dlarray(重量);generatorParameters.Conv5。偏见= dlarray(偏差);结尾
综合drubebat.
合成仪器使用预先训练过的网络来合成鼓点。
函数y = synthesizeDrumBeat执着的PgeneratorParameters pmean Pstd.如果isempty (pGeneratorParameters)%如果MAT文件不存在,请下载filename =“drumGeneratorWeights.mat”;负载(文件名,“SMean”那“SStd”那'GeneratorParameters');pMean = SMean;pSTD = SStd;pGeneratorParameters = generatorParameters;结尾生成随机向量dlZ = dlarray (2 * (rand (1100 1“单一”) - 0.5);%生成谱图dlXGenerated = modelGenerator (dlZ pGeneratorParameters);%转换从美元到单一S = dlXGenerated.extractdata;=年代。”;%零垫以删除边缘效果S = [S;零(1,128)];培训百分比反向步骤s = s * 3;S =(S. * PSTD)+ PMEAN;s = exp(s);做双面的S = [S;S (end-1: 1:2,)];%垫结束并开始S = [0 (256,100) S 0 (256,100)];%使用快速Griffin-Lim算法重建信号。myAudio = stftmag2sig(收集(S), 256年,...“FrequencyRange”那'twosiding'那...“窗口”损害(256,'定期'),...“OverlapLength”, 128,...'发光', 20岁,...“方法”那“fgla”);myAudio = myAudio. / max (abs (myAudio), [],'全部');y = myAudio(128 * 100:结束- 128 * 100);结尾
效用函数
函数max(x, 0) - x .* z + log(1 + exp(-abs(x)));结尾函数w = Iglorotinitialize(SZ)如果nummel (sz) == 2 numInputs = sz(2);numOutputs =深圳(1);别的numInputs = prod(深圳(1:3));numOutputs = prod(sz([1 2 4])); / /输出结尾乘法器=√(2 / (numInputs + numOutputs));W =乘数*根号(3)* (2 * rand(sz),“单一”) - 1);结尾
参考
[1] Donahue,C.,J.Mcauley和M. Puckette。2019年。“对抗音频综合。”ICLR。
你也可以从以下列表中选择一个网站: