使用并行计算工具箱加速误码率模拟
这个例子使用并行计算工具箱来加速一个简单的QPSK比特误码率(BER)模拟。该系统由一个QPSK调制器、一个QPSK解调器、一个AWGN信道和一个误码率计数器组成。在本例中,使用了四个并行处理器。
设置仿真参数。
EbNoVec = 8;% Eb/ dB中没有值totalErrors = 200;每个Eb/No值所需的位错误数%totalBits = 1 e7;每个Eb/No值传输的总比特数%
分配内存给用来存储函数生成的数据的数组,helper_qpsk_sim_with_awgn。
[numErrors, numBits] = deal(0 (length(EbNoVec),1);
运行模拟并确定执行时间。只有一个处理器将被用来确定基准性能。因此,观察使用正常的for循环。
抽搐为errorStats = helper_qpsk_sim_with_awgn(…totalErrors totalBits);numErrors (idx) = errorStats (idx 2);numBits (idx) = errorStats (idx 3);结束simBaselineTime = toc;
计算系统。
ber1 = numErrors ./ numBits;
在并行计算工具箱可用的情况下,重新运行模拟。创建一个工作人员池。
池=质量;
使用“本地”配置文件启动并行池(parpool)…连接到并行池(worker数量:6)。
从。中确定可用工人的数量NumWorkers的属性池。模拟运行范围为 重视每个员工,而不是分配一个人指出每一个工人,因为前者的方法提供了最大的绩效改善。
重视每个员工,而不是分配一个人指出每一个工人,因为前者的方法提供了最大的绩效改善。
numWorkers = pool.NumWorkers;
确定的长度EbNoVec在嵌套中使用parfor循环。为正确的变量分类,a中嵌套的For循环的范围parfor必须由常量或变量定义。
lenEbNoVec =长度(EbNoVec);
分配内存给用来存储函数生成的数据的数组,helper_qpsk_sim_with_awgn。
[numErrors, numBits] = deal(0 (length(EbNoVec),numWorkers));
运行模拟并确定执行时间。
抽搐parforn = 1: numWorkers为helper_qpsk_sim_with_awgn(EbNoVec, idx,…totalErrors / numWorkers totalBits / numWorkers);numErrors (idx n) = errorStats (idx 2);numBits (idx n) = errorStats (idx 3);结束结束simParallelTime = toc;
计算系统。在这种情况下,必须将来自多个处理器的结果组合起来以生成聚合误码率。
/ sum(numBits,2); / sum(numBits,2);
比较BER值来验证相同的结果与工人的数量无关。
ber1 semilogy (EbNoVec ',“- *”, ber2 EbNoVec””——^”)传说(“单处理器”,多处理器的,“位置”,“最佳”)包含(“Eb /不(dB)”) ylabel (“方方面面”网格)
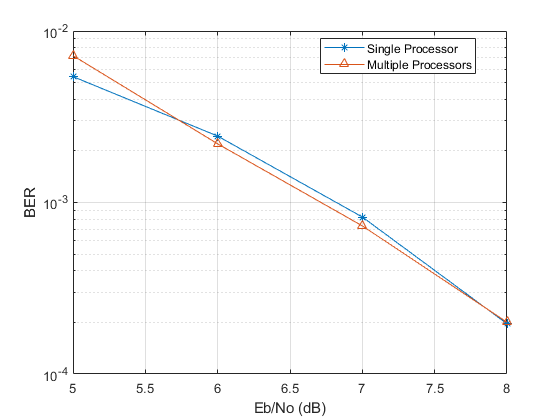
你可以看到,BER曲线本质上是相同的,任何方差都是由于不同的随机数种子。
比较每个方法的执行时间。
流(['\nSimulation time = %4.1f sec for one worker\n',…'多个worker的模拟时间= %4.1f秒\n'),…simBaselineTime simParallelTime)
一个worker的模拟时间= 67.2秒多个worker的模拟时间= 17.9秒
在使用4个处理器内核的情况下,速度改进因子大约为4。
您也可以从以下列表中选择一个网站:
