主要内容
评估曲线拟合
此示例显示如何使用曲线拟合。
负荷数据与拟合多项式曲线
负载人口普查curvefit = fit(cdate,pop,“poly3”,“正常化”,“上”)
系数(95%置信限):p1 = 0.921 (-0.9743, 2.816) p2 = 25.18 (23.57, 26.79) p3 = 73.86 (70.33, 77.39) p4 = 61.74 (59.69, 63.8)
输出显示拟合模型方程、拟合系数和拟合系数的置信界限。
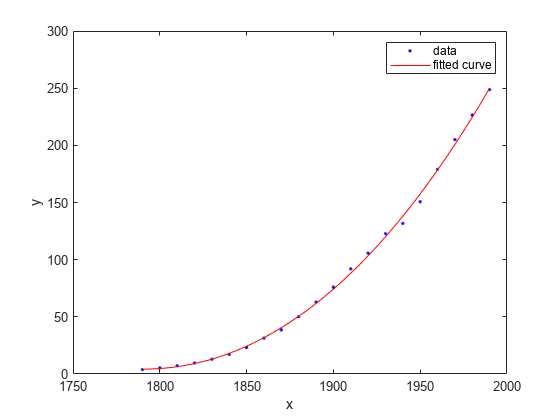
绘制拟合、数据、残差和预测界限
情节(curvefit cdate流行)
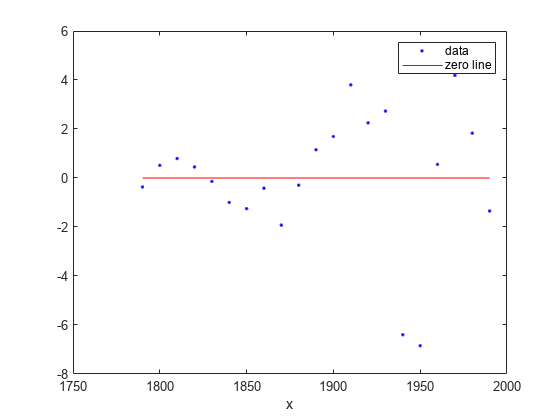
绘制残差拟合图。
情节(curvefit cdate、流行、“残差”)
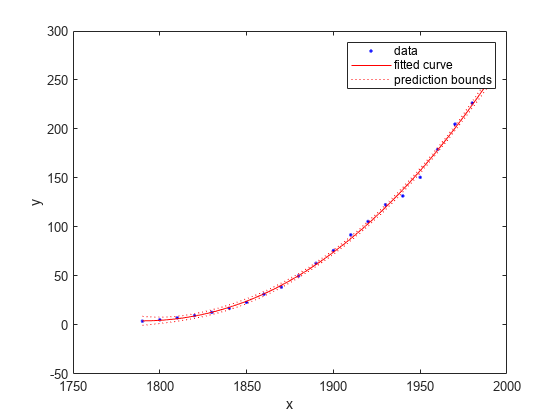
绘制拟合的预测界限。
情节(curvefit cdate、流行、“predfunc”)
在指定点计算拟合值
通过指定的值来计算在特定点上的适合度x,使用此表格:y = fittedmodel (x).
curvefit (1991)
ans = 252.6690.
评估多点的拟合值
评估价值矢量的模型以推断到2050年。
XI =(2000:10:2050)。';Curvefit(xi)
ans =6×1276.9632 305.4420 335.5066 367.1802 400.4859 435.4468
获得这些值的预测界限。
ci = predint(curvefit,xi)
ci =6×2267.8589 286.0674 294.3070 316.5770 321.5924 349.4208 349.7275 384.6329 378.7255 422.2462 408.5919 462.3017
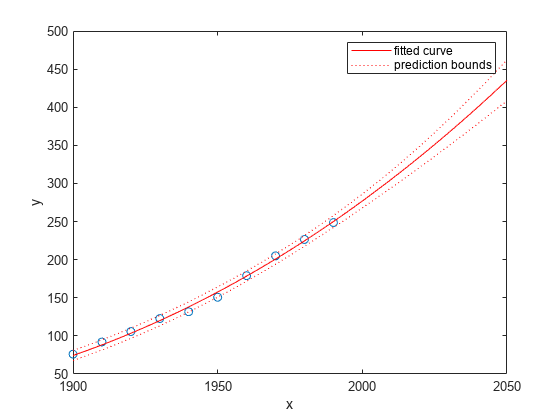
在外推拟合范围内绘制拟合和预测区间。默认情况下,拟合是在数据范围内绘制的。要查看从匹配中推断出的值,在绘制匹配之前将坐标轴的x上限设置为2050。要绘制预测区间,使用predobs或者predfun作为情节类型。
情节(Cdate,Pop,'o')XLIM([1900,2050])持有在绘图(曲线装,“predobs”) 抓住离开
得到模型方程
输入适合名称以显示拟合系数的模型方程,装配系数和置信度。
curvefit
系数(95%置信限):p1 = 0.921 (-0.9743, 2.816) p2 = 25.18 (23.57, 26.79) p3 = 73.86 (70.33, 77.39) p4 = 61.74 (59.69, 63.8)
要得到模型方程,请使用公式.
公式(curvefit)
= 'p1*x^ 2 + p2*x^2 + p3*x + p4'
获取系数名称和值
通过名称指定一个系数。
p1 = curvefit.p1.
p1 = 0.9210
p2 = curvefit.p2.
P2 = 25.1834.
得到所有系数的名称。看看拟合方程(例如,f (x) = p1 * x ^ 3 +……)来查看每个系数的模型项。
coeffnames (curvefit)
ans =4 x1细胞{'p1'} {'p2'} {'p3'} {'p4'}
获取所有系数值。
Coffvalues(Curvefit)
ans =1×40.9210 25.1834 73.8598 61.7444
在系数上获得信心范围
在系数上使用置信度界限来帮助您评估和比较适合。系数上的置信度界限决定了它们的准确性。相距甚远的界限表明不确定性。如果界限交叉零用于线性系数,这意味着您无法确定这些系数与零不同。如果某些模型术语具有零系数,则它们并不适合。
confint (curvefit)
ans =2×4.-0.9743 23.5736 70.3308 59.6907 2.8163 26.7931 77.3888 63.7981
检查拟合优度统计
要获得命令行的良好统计数据,您可以:
打开曲线拟合app并选择适合>保存到工作区将适合和良好的适合作为工作区出口。
指定
gof使用适合函数。
重新创造配合指明gof和输出参数获取拟合统计和拟合算法信息。
[CurveFit,GOF,输出] = FIT(CDate,POP,“poly3”,“正常化”,“上”)
系数(95%置信限):p1 = 0.921 (-0.9743, 2.816) p2 = 25.18 (23.57, 26.79) p3 = 73.86 (70.33, 77.39) p4 = 61.74 (59.69, 63.8)
gof =结构与字段:Sse: 149.7687 rsquare: 0.9988 dfe: 17 adjrsquare: 0.9986 rmse: 2.9682
输出=结构与字段:nummobs: 21 numparam: 4 residuals: [21x1 double] Jacobian: [21x4 double] exitflag: 1 algorithm: 'QR分解和求解' iterations: 1
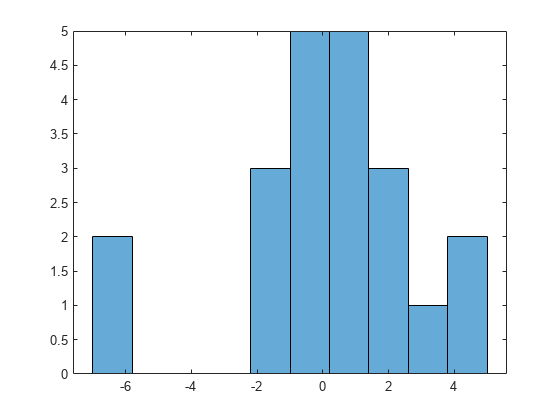
绘制残留的直方图,以寻找大致正常的分布。
直方图(output.residuals, 10)
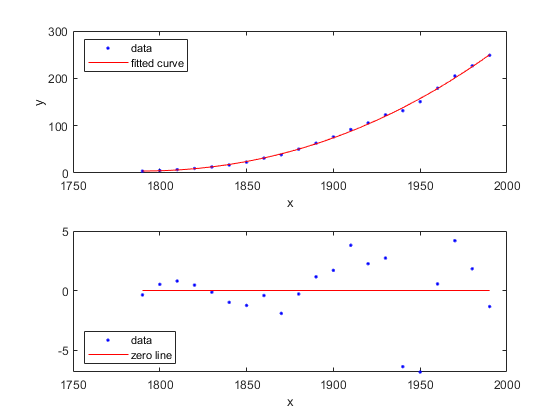
绘制拟合,数据和残差
情节(curvefit cdate、流行、“健康”,“残差”传说)位置西南次要情节(2,1,1)传奇位置西北
找到方法
列出每一个适合你的方法。
方法(Curvefit)
方法CFIT类:Argnames unfint公式Numcoeffs SetOptions类别Depenname Indepnames绘图类型CFIT差异集成预测COEffnames Feval Islinequens Coffvalues Fitoptions Numargs Probalues
使用帮助命令找出如何使用合适的方法。
帮助cfit /区分
区分差异化拟合结果对象。Deriv1 = Scensyiate(fitobj,x)将模型fitobj与x指定的点区分开来,并返回deriv1的结果。fitobj是由拟合或CFIT功能生成的适合对象。x是矢量。Deriv1是与x的尺寸相同的向量。数学上讲,deriv1 = d(fitobj)/ d(x)。[deriv1,deriv2] =分化(fitobj,x)分别计算型号fitobj的第一和第二导数,deriv1和deriv2。另见CFIT /集成,适合CFIT。
您还可以从以下列表中选择一个网站:
