滤波和平滑数据
关于数据平滑和过滤
你可以使用光滑的函数来平滑响应数据。您可以使用可选的方法均线,Savitzky - 格雷的过滤器,并有和没有重量和坚固性(局部回归LOWESS,黄土,rlowess和rloess)。
移动平均滤波
移动平均滤波器通过用跨度内定义的相邻数据点的平均值替换每个数据点来平滑数据。这个过程等价于低通滤波,其响应由差分方程给出的平滑
在哪里y<年代ub>年代(我)是平滑值我数据点,N两边相邻数据点的个数是多少y<年代ub>年代(我), 2N+1是跨度。
曲线拟合工具箱™使用的移动平均平滑方法遵循以下规则:
张成的空间必须是奇数。
被平滑的数据点必须位于跨度的中心。
跨度调整为不能容纳在任一侧上的邻居的指定数量的数据点。
端点没有被平滑,因为无法定义张成空间。
注意,您可以使用过滤器函数来实现如上所示的差分方程。但是,由于处理端点的方式,工具箱移动平均结果将与返回的结果不同过滤器.指差分方程和过滤想要查询更多的信息。
例如,假设您使用跨度为5的移动平均滤波器平滑数据。使用上面描述的规则,元素的前四个元素y年代是由
y<年代ub>年代(1)= Y(1)Y<年代ub>年代(2) = y(1)+y(2)+y(3) /3 y<年代ub>年代(3)=(Y(1)+ Y(2)+ Y(3)+ Y(4)+ Y(5))/ 5 Y<年代ub>年代(4)=(Y(2)+ Y(3)+ Y(4)+ Y(5)+ Y(6))/ 5
注意y年代(1),y年代(2),...,y年代(结尾)指数据的顺序排序之后,并且不一定是原来的顺序。
对于所生成的数据组的第一四个数据点的平滑值和跨度如下所示。

情节(一)指示第一个数据点未被平滑,因为无法构造span。情节(b)指示第二个数据点使用3的跨度进行平滑。情节(c)和(d)表示5的跨度用于计算平滑值。
Savitzky-Golay过滤
Savitzky-Golay滤波可以被认为是一种广义移动平均。通过使用给定次数的多项式进行非加权线性最小二乘拟合,可以推导出过滤系数。因此,Savitzky-Golay滤波器也被称为数字平滑多项式滤波器或最小二乘平滑滤波器。请注意,高次多项式可以实现高水平的平滑,而不需要数据特征的衰减。
Savitzky-Golay滤波方法常用于频率数据或光谱(峰)数据。对于频率数据,该方法有效地保留了信号的高频成分。对于光谱数据,该方法有效地保留了峰的高阶矩,如线宽。相比之下,移动平均滤波器倾向于滤除信号的高频内容的很大一部分,它只能保留一个峰值的较低的矩,如质心。然而,萨维茨基-戈莱滤波在拒绝噪声方面不如移动平均滤波器成功。
通过曲线拟合工具箱软件使用的Savitzky-Golay平滑方法遵循以下规则:
张成的空间必须是奇数。
多项式的次数必须小于张成的空间。
不需要的数据点,以有均匀的间隔。
通常情况下,Savitzky-格雷滤波需要预测数据的均匀间隔。然而,曲线拟合工具箱算法支持非均匀间距。万博1manbetx因此,不需要执行额外的过滤步骤以产生具有均匀间隔的数据。
下图显示了生成的高斯数据和使用Savitzky-Golay方法进行平滑的几次尝试。数据噪声很大,峰值宽度从宽到窄不等。跨度等于数据点数量的5%。

情节(一)显示噪声数据。为了更容易比较平滑的结果,图(b)和(c)显示没有附加噪声的数据。
情节(b)给出了用二次多项式平滑的结果。注意,对于窄峰,该方法的性能很差。情节(c)给出了用四次多项式平滑的结果。一般来说,高次多项式可以更准确地捕捉窄峰的高度和宽度,但在平滑宽峰方面做得很差。
当地回归平滑
洛斯和黄土
名称“LOWESS”和“黄土”是从衍生术语“局部加权散点图平滑”,如两种方法都使用局部加权线性回归以平滑数据。
平滑过程被认为是局部的,因为像移动平均法一样,每个平滑值都是由在跨度内定义的相邻数据点决定的。该过程是加权的,因为为跨度内包含的数据点定义了回归权函数。除了回归权函数外,您还可以使用稳健权函数,这使得流程能够抵抗离群值。最后,用回归模型对方法进行区分:lowess采用线性多项式,而黄土采用二次多项式。
曲线拟合工具箱软件使用的局部回归平滑方法遵循以下规则:
张成的空间可以是偶数也可以是奇数。
您可以将跨度指定为数据集中数据点总数的百分比。例如,0.1的跨度使用10%的数据点。
局部回归法
的局部回归平滑化处理的步骤如下为每个数据点:
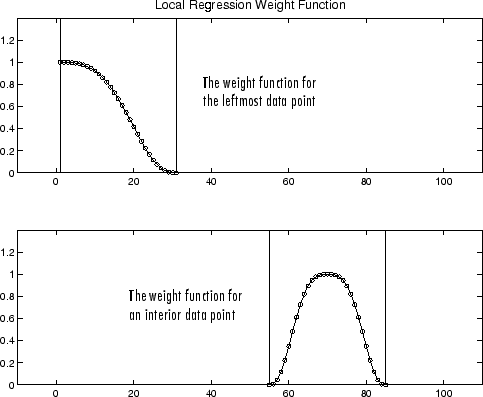
如果平滑计算涉及相同数量的平滑的数据点的任一侧上的相邻数据点的,权重函数是对称的。然而,如果相邻点的数目是非对称的围绕平滑的数据点,则该权重函数是不对称的。请注意,与移动平均平滑处理,跨度永远不会改变。例如,当你顺利用最小预测值的数据点,权重函数的形状是由一个半截断,跨度中最左边的数据点具有最大的权重,以及所有相邻点到的权平滑值。
为结束点和内部点的权重函数被显示如下的31个数据点的跨度。
使用具有五个跨度LOWESS方法中,所产生的数据组的第一四个数据点的平滑值和相关联的回归如下所示。
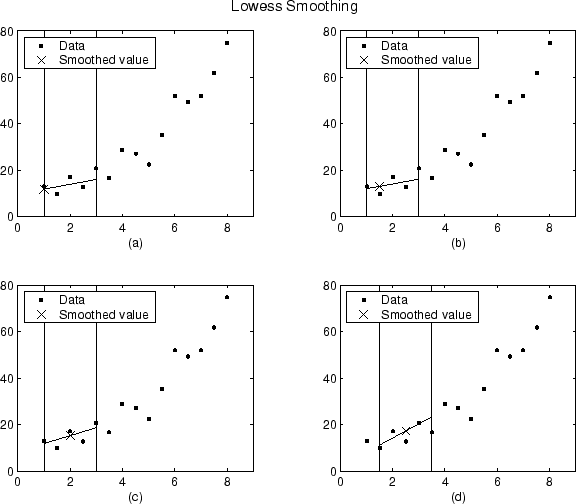
注意,当平滑过程从一个数据点到另一个数据点时,跨度不会改变。然而,根据最近邻的数量,回归权函数可能对要平滑的数据点不对称。特别是,情节(一)和(b)在绘图时使用非对称权重函数(c)和(d)使用对称权重函数。
对于黄土法,图看起来是一样的,除了平滑的值将由二次多项式产生。
强大的本地回归
如果您的数据包含异常值,则平滑值会产生失真,而不是反映了大部分的相邻数据点的行为。为了克服这个问题,你可以使用未通过异常的一小部分影响了强大的过程平滑数据。为异常值的描述,请参考残留分析.
曲线拟合工具箱软件提供了一个可靠的版本为LOWESS和黄土平滑法两种。这些坚固的方法包括鲁棒权重的附加计算,这是异常值具有抗性。坚固平滑程序步骤如下:
计算前一节描述的平滑过程中的残差。
计算<年代pan class="emphasis">健壮的权重在跨距的每个数据点。权重由bisquare函数给出,
在哪里r<年代ub>我是残的吗我个数据点由回归平滑程序生产,并且疯狂的为残差绝对值的中位数,
中位数绝对偏差是残差分布的一个度量。如果r<年代ub>我比6小吗疯狂的,则稳健权值接近于1。如果r<年代ub>我大于6疯狂的,稳健权值为0,将相关数据点排除在平滑计算之外。
使用稳健权值再次平滑数据。利用局部回归权值和鲁棒权值计算最终的平滑值。
重复前面的两个步骤,总共五个迭代。
对于包含单个离群值的生成数据集,将低阶过程的平滑结果与鲁棒低阶过程的结果进行比较。这两个过程的跨度是11个数据点。

情节(一)结果表明,离群值对几个最近邻的平滑值有影响。情节(b)表明离群值的残差大于6个中位数绝对偏差。因此,该数据点的稳健性权值为零。情节(c)示出了平滑值相邻离群值反映了大部分的数据。
例如:平滑数据
加载数据count.dat:
负载count.dat
24-by-3数组数包含每天每小时三个路口的交通统计。
首先,使用一个5小时跨度的移动平均滤波器(通过线性指数)一次平滑所有数据:
c =光滑(count (:));C1 =重塑(c, 24岁,3);
绘制原始数据和平滑数据:
副区(3,1,1)图(计数, ':');保持在地块(C1, ' - ');标题( '平滑C1(所有数据)')
其次,使用相同的过滤器来分别平滑数据的每一列:
C2 = 0(24日3);for I = 1:3, C2(:,I) = smooth(count(:,I));结束
同样,绘制原始数据和平滑后的数据:
次要情节(3,1,2)情节(统计,“:”);抓住情节(C2,“-”);标题(“平滑C2(每一栏)”)
绘制两个平滑数据集之间的差异:
副区(3,1,3)情节(C2 - C1, '邻')标题( '差分C2 - C1')
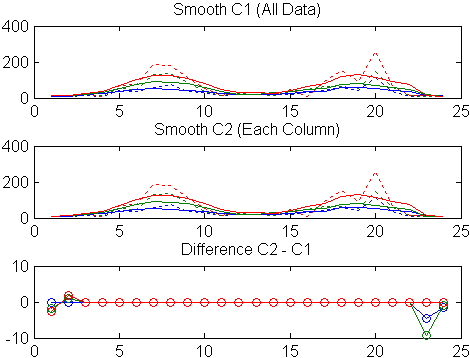
注意,来自3列附加的末端效应平滑。
例如:用黄土和稳健黄土平滑数据
用异常值创建有噪声的数据:
X = 15 *兰特(150,1);Y =的sin(x)+ 0.5 *(兰特(大小(X)) - 0.5);Y(小区(长度(X)*兰特(2,1)))= 3;
平滑数据使用黄土和rloess方法跨度为10%:
yy1 =光滑(x, y, 0.1,“黄土”);yy2 =光滑(x, y, 0.1,“rloess”);
绘制原始数据和平滑数据。
[xx,印第安纳州]= (x)进行排序;次要情节(2,1,1)情节(xx, y(印第安纳州),b。,xx, yy1(印第安纳州),r -)组(gca、“YLim”,[-1.5 - 3.5])传说(“原始数据”,使用“黄土”平滑数据,…“位置”、“西北”)次要情节(2,1,2)情节(xx, y(印第安纳州),b。,xx, yy2(印第安纳州),r -)组(gca、“YLim”,[-1.5 - 3.5])传说(“原始数据”,“使用”rloess平滑数据”,…“位置”、“西北”)

注意,离群值对稳健方法的影响较小。
另请参阅
相关的话题
选择网站
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:<年代trong class="recommended-country">.
选择<年代pan class="recommended-country">网站你也可以从以下列表中选择一个网站:
