训练堆叠自动编码器的图像分类
这个例子展示了如何训练堆叠的自动编码器对数字图像进行分类。
具有多个隐藏层的神经网络可以用于解决图像等复杂数据的分类问题。每一层都可以在不同的抽象级别学习特性。然而,在实践中训练具有多个隐藏层的神经网络是很困难的。
一种有效训练多层神经网络的方法是一次只训练一层。您可以通过为每个所需的隐藏层训练一种称为自动编码器的特殊类型的网络来实现这一点。
这个例子展示了如何训练一个有两个隐藏层的神经网络来对图像中的数字进行分类。首先,使用自动编码器以无监督的方式单独训练隐藏层。然后训练一个最终的softmax层,并将这些层连接在一起形成一个堆叠网络,在监督的方式下最后训练一次。
数据集
本例始终使用合成数据进行培训和测试。合成图像是通过对使用不同字体创建的数字图像应用随机仿射变换生成的。
每个数字图像是28×28像素,有5000个训练示例。您可以加载训练数据,并查看一些图像。
%将训练数据载入记忆[xTrainImages, tTrain] = digitTrainCellArrayData;%显示一些训练图像clf为I = 1:20 subplot(4,5, I);imshow (xTrainImages{我});结束

图像的标签存储在一个10×5000的矩阵中,其中每列中的单个元素为1,表示数字所属的类别,列中的所有其他元素为0。应注意,如果第十个元素为1,则数字图像为零。
训练第一个自动编码器
首先在训练数据上训练一个稀疏自动编码器,而不使用标签。
自动编码器是一种神经网络,它试图在输出端复制输入。因此,输入的大小将与输出的大小相同。当隐层神经元的数目小于输入的大小时,自动编码器学习输入的压缩表示。
神经网络在训练前随机初始化权值。因此,每次训练的结果都不一样。为了避免这种行为,显式地设置随机数生成器种子。
rng(“默认”)
为自动编码器设置隐藏层的大小。对于要训练的自动编码器,最好使其小于输入大小。
hiddenSize1 = 100;
您将培训的自动编码器类型是稀疏自动编码器。此自动编码器使用正则化器学习第一层中的稀疏表示。您可以通过设置各种参数来控制这些正则化器的影响:
L2加权正则化控制L2正则化器对网络权重的影响(而不是偏差)。这通常应该非常小。SparsityRegularization控制稀疏正则化器的影响,该正则化器尝试对隐藏层输出的稀疏性实施约束。请注意,这与将稀疏正则化器应用于权重不同。SparsityProportion是稀疏正则化器的一个参数。它控制隐藏层输出的稀疏性。为SparsityProportion通常会导致隐藏层中的每个神经元“专门化”,只为少量训练示例提供高输出SparsityProportion设置为0.1,这相当于说,隐藏层中的每个神经元的平均输出应该是训练示例的0.1。该值必须在0到1之间。理想值随问题的性质而变化。
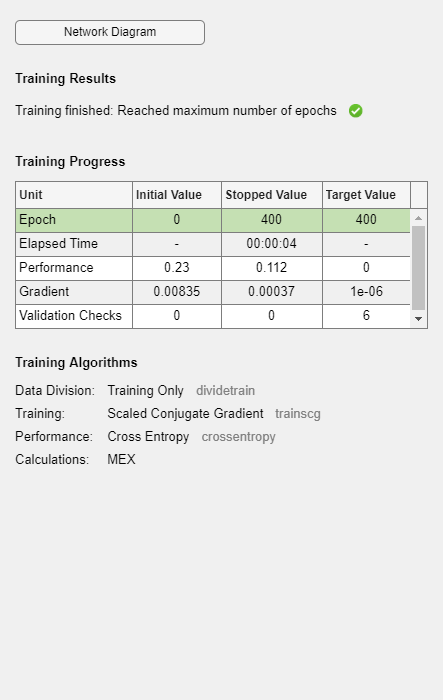
现在训练自动编码器,指定上面描述的正则化器的值。
autoenc1 = trainAutoencoder (xTrainImages hiddenSize1,…“MaxEpochs”, 400,…“L2WeightRegularization”, 0.004,…“SparsityRegularization”,4,…“SparsityProportion”, 0.15,…“ScaleData”、假);
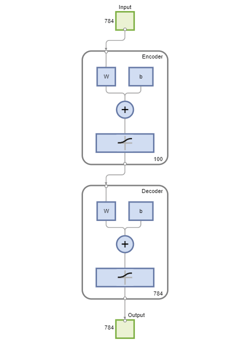
您可以查看自动编码器的图表。自动编码器由一个编码器和一个解码器组成。编码器将一个输入映射到一个隐藏的表示,解码器尝试反转这个映射来重建原始的输入。
视图(autoenc1)

可视化第一个自动编码器的权重
自动编码器的编码器部分学到的映射可以用于从数据中提取特征。编码器中的每个神经元都有一个与之相关的权值向量,它将被调整以响应特定的视觉特征。您可以查看这些特性的表示。
图()绘图仪权重(autoenc1);
您可以看到,自动编码器学习的特征代表了数字图像的卷曲和笔画模式。
自动编码器隐藏层的100维输出是输入的压缩版本,它总结了其对上述可视化特征的响应。根据从训练数据中提取的一组向量训练下一个自动编码器。首先,必须使用经过训练的自动编码器中的编码器来生成特征。
feat1 =编码(autoenc1 xTrainImages);
训练第二个自动编码器
在训练第一个自动编码器之后,以类似的方式训练第二个自动编码器。主要的区别在于,您使用从第一个自动编码器生成的特性作为第二个自动编码器中的训练数据。此外,您还将隐藏表示的大小减少到50,以便第二个自动编码器中的编码器学习更小的输入数据表示。
hiddenSize2 = 50;autoenc2 = trainAutoencoder (feat1 hiddenSize2,…“MaxEpochs”, 100,…“L2WeightRegularization”, 0.002,…“SparsityRegularization”,4,…“SparsityProportion”, 0.1,…“ScaleData”、假);
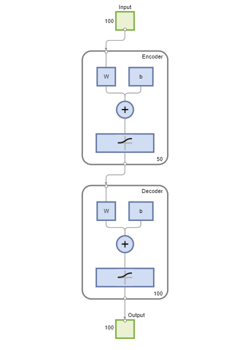
控件可以再次查看自动编码器的图表视图函数。
视图(autoenc2)

您可以通过从第二个自动编码器中通过编码器传递前一组特性来提取第二组特性。
feat2 =编码(autoenc2 feat1);
训练数据中的原始向量有784维。在通过第一个编码器之后,它被缩减到100个维度。在使用第二个编码器后,这又减少到50个维度。现在,您可以训练最后一层将这些50维向量分类为不同的数字类。
训练最后的softmax层
训练一个softmax层对50维特征向量进行分类。与自动编码器不同,您可以使用训练数据的标签以受监督的方式训练softmax层。
softnet=trainSoftmaxLayer(feat2,t列车,“MaxEpochs”, 400);
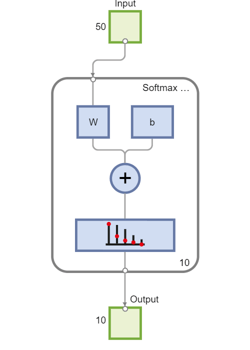
可以查看softmax层的组网图视图函数。
视图(softnet)

形成一个堆叠的神经网络
你已经孤立地训练了堆叠神经网络的三个独立组件。此时,查看一下您训练过的三个神经网络可能会很有用。他们是autoenc1,autoenc2,及softnet.
视图(autoenc1)视图(autoenc2)视图(softnet)
如前所述,来自自动编码器的编码器已用于提取特征。您可以将来自自动编码器的编码器与softmax层堆叠在一起,形成用于分类的堆叠网络。
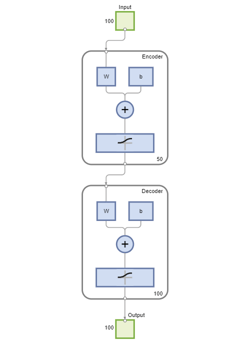
stackednet =堆栈(autoenc1 autoenc2 softnet);
可以查看堆叠网络的组网图视图函数。该网络由自编码器和软最大层的编码器组成。
视图(stackednet)

形成完整的网络后,可以在测试集中计算结果。要使用堆叠网络中的图像,必须将测试图像重塑为一个矩阵。你可以通过叠加图像的列来形成一个向量,然后由这些向量形成一个矩阵。
%得到每个图像的像素数imageWidth = 28;imageHeight = 28;inputSize = imageWidth * imageHeight;%加载测试映像(xTestImages, tt) = digitTestCellArrayData;%将测试图像转换成向量,并将它们放入一个矩阵中xTest = 0 (inputSize元素个数(xTestImages));为i = 1:numel(xTestImages) xTest(:,i) = xTestImages{i}(:);结束
您可以使用混淆矩阵来可视化结果。矩阵右下角正方形中的数字给出了整体的精度。
y = stackednet (xTest);plotconfusion (tt, y);
对堆叠神经网络进行微调
通过对整个多层网络进行反向传播,可以改进堆叠神经网络的结果。这个过程通常称为微调。
通过在有监督的方式对训练数据进行再训练,可以对网络进行微调。在此之前,您必须将训练图像重塑为一个矩阵,就像对测试图像所做的那样。
%将训练图像转换成向量,并将它们放入矩阵中xTrain = 0 (inputSize元素个数(xTrainImages));为i = 1:numel(xTrainImages) xTrain(:,i) = xTrainImages{i}(:);结束%执行微调stackednet =火车(stackednet xTrain tTrain);
然后使用混淆矩阵再次查看结果。
y = stackednet (xTest);plotconfusion (tt, y);

总结
这个例子展示了如何训练一个堆叠的神经网络来使用自动编码器对图像中的数字进行分类。以上列出的步骤可以应用于其他类似的问题,如对字母图像进行分类,甚至对特定类别的物体的小图像进行分类。
你也可以从以下列表中选择一个网站:
