使用条件GAN生成合成信号
这个例子展示了如何使用一个条件生成合成泵信号生成对抗的网络。
生成对抗网络(甘斯)可以用来生产合成数据,类似于真实数据网络的输入。甘斯非常有用当模拟计算昂贵或实验是昂贵的。有条件的甘斯(CGANs)可以使用在训练过程中数据标签来生成数据属于特定类别。
这个例子将模拟信号通过泵模型™模型作为“真正的”数据的角色CGAN训练数据集。万博1manbetxCGAN使用一维循环卷积网络和训练使用一个定制的培训和深入学习数组。此外,这个示例使用主成分分析(PCA)在视觉上比较生成的特点和真实信号。
CGAN信号合成
CGANs由火车作为对手的两个网络:
发电机网络——给出一个标签和随机数组作为输入,这个网络生成的数据作为训练数据结构相同的观测对应相同的标签。发电机的目的是生成带安全标签的数据时,鉴别器分类的“真实”。
鉴频器网络——鉴于批次的标签包含从训练数据和观测数据生成器生成的数据,这个网络尝试分类观察“真实”或“产生”。的objective of the discriminator is to not be "fooled" by the generator when given batches of both real and generated labeled data.
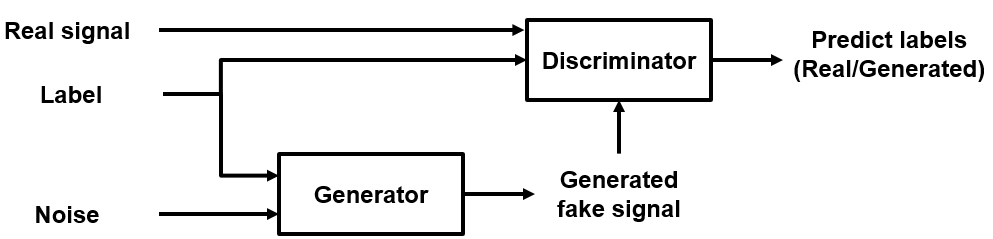
理想情况下,这些策略导致发电机产生令人信服的真实数据对应于输入标签和鉴频器,学会了强大功能训练数据的特征为每个标签。
加载数据
生成的模拟数据泵的仿真软件模型万博1manbetx使用模拟数据多层次故障检测(预测维护工具箱)的例子。仿真软件万博1manbetx模型配置为模型三种类型的缺点:油缸泄漏,封锁了入口,并增加轴承的摩擦。数据集包含1575个泵输出流量信号,其中760是健康的信号和815年有一个错,组合的两个缺点,或组合的三个缺点。每个信号有1201信号样本采样率为1000 Hz。
下载并解压缩数据在你的临时目录,由MATLAB®指定的位置tempdir命令。如果你有指定的文件夹中的数据不同tempdir在以下代码,改变目录的名字。
%下载数据dataURL =“https://ssd.mathworks.com/万博1manbetxsupportfiles/SPT/data/PumpSignalGAN.zip”;saveFolder = fullfile (tempdir,“PumpSignalGAN”);zipFile = fullfile (tempdir,“PumpSignalGAN.zip”);如果~存在(saveFolder“dir”)websave (zipFile dataURL);结束%解压数据解压缩(zipFile saveFolder)
zip文件包含了训练数据集和一个pretrained CGAN:
simulatedDataset——模拟信号和相应的分类标签GANModel-发电机和鉴别器训练模拟数据
负荷训练数据集和规范的信号零均值和单位方差。
负载(fullfile (saveFolder“simulatedDataset.mat”))%加载数据集meanFlow =意味着(流,2);flowNormalized = flow-meanFlow;stdFlow =性病(flowNormalized (:));flowNormalized = flowNormalized / stdFlow;
健康的信号被贴上标记为2 1和错误的信号。
定义发电机网络
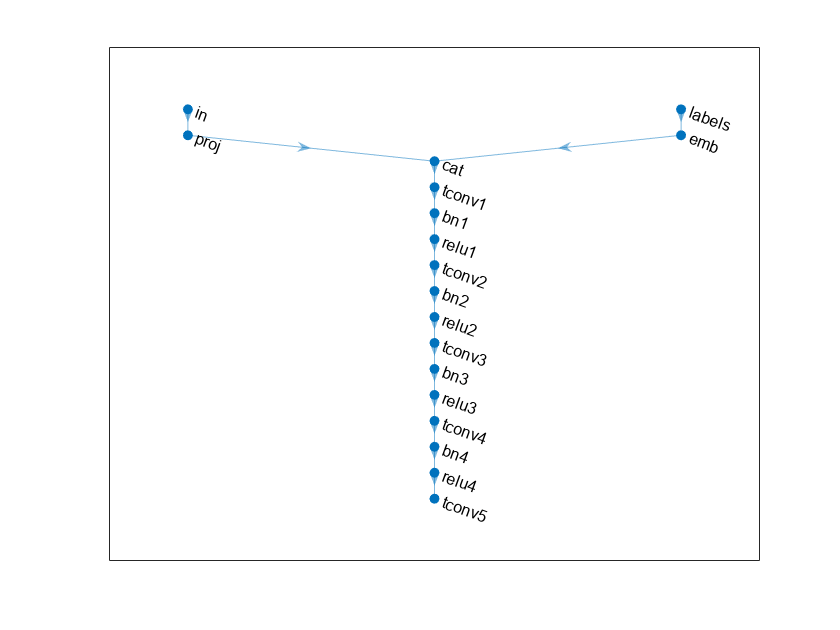
定义以下两个输入网络,生成流信号得到- 1 1 - - - 100阵列的随机值和相应的标签。
网络:
项目和重塑1 -到- 1 -到- 100阵列的噪音4 -通过- 1 - 1024数组通过一个自定义层。
将分类标签嵌入向量和重塑4-by-1-by-1数组。
沿着通道连接的结果两个输入维度。输出是一个4 - - 1 - 1025的数组。
Upsamples结果数组- 1201 -通过- 1 - 1使用一系列一维数组转置卷积层批规范化和ReLU层。
项目和重塑噪声输入,使用自定义层projectAndReshapeLayer附加到这个例子作为支持文件。万博1manbetx的projectAndReshapeLayer高档输入对象使用一个完全连接层和重塑输出到指定的大小。
输入标签进入网络,使用一个imageInputLayer对象,并指定一个1×1的大小。嵌入和重塑标签输入,使用自定义层embedAndReshapeLayer附加到这个例子作为支持文件。万博1manbetx的embedAndReshapeLayer对象将分类标签转换为一个通道指定大小的数组使用嵌入和一个完全连接操作。对于分类的输入,使用100年的嵌入维数。
%发电机网络numFilters = 64;numLatentInputs = 100;projectionSize = (1 1024);numClasses = 2;embeddingDimension = 100;layersGenerator = [imageInputLayer (1 numLatentInputs [1],“归一化”,“没有”,“名字”,“在”)projectAndReshapeLayer (projectionSize numLatentInputs,“项目”);concatenationLayer (3 2“名字”,“猫”);transposedConv2dLayer (1 [5], 8 * numFilters,“名字”,“tconv1”)batchNormalizationLayer (“名字”,“bn1”,‘ε’5 e-5) reluLayer (“名字”,“relu1”)transposedConv2dLayer (4 * numFilters [10 1],“步”4“种植”(1 0),“名字”,“tconv2”)batchNormalizationLayer (“名字”,“bn2”,‘ε’5 e-5) reluLayer (“名字”,“relu2”)transposedConv2dLayer (2 * numFilters (12 - 1),“步”4“种植”(1 0),“名字”,“tconv3”)batchNormalizationLayer (“名字”,“bn3”,‘ε’5 e-5) reluLayer (“名字”,“relu3”1)transposedConv2dLayer ([5], numFilters,“步”4“种植”(1 0),“名字”,“tconv4”)batchNormalizationLayer (“名字”,“bn4”,‘ε’5 e-5) reluLayer (“名字”,“relu4”1)transposedConv2dLayer ([7], 1“步”2,“种植”(1 0),“名字”,“tconv5”));lgraphGenerator = layerGraph (layersGenerator);层= [imageInputLayer ([1],“名字”,“标签”,“归一化”,“没有”)embedAndReshapeLayer (projectionSize (1:2), embeddingDimension numClasses,“循证”));lgraphGenerator = addLayers (lgraphGenerator层);lgraphGenerator = connectLayers (lgraphGenerator,“循证”,“猫/ in2”);
情节的网络结构生成器。
情节(lgraphGenerator)
训练网络使用一个自定义训练循环和启用自动分化、转换层图dlnetwork对象。
dlnetGenerator = dlnetwork (lgraphGenerator);
定义鉴别器网络
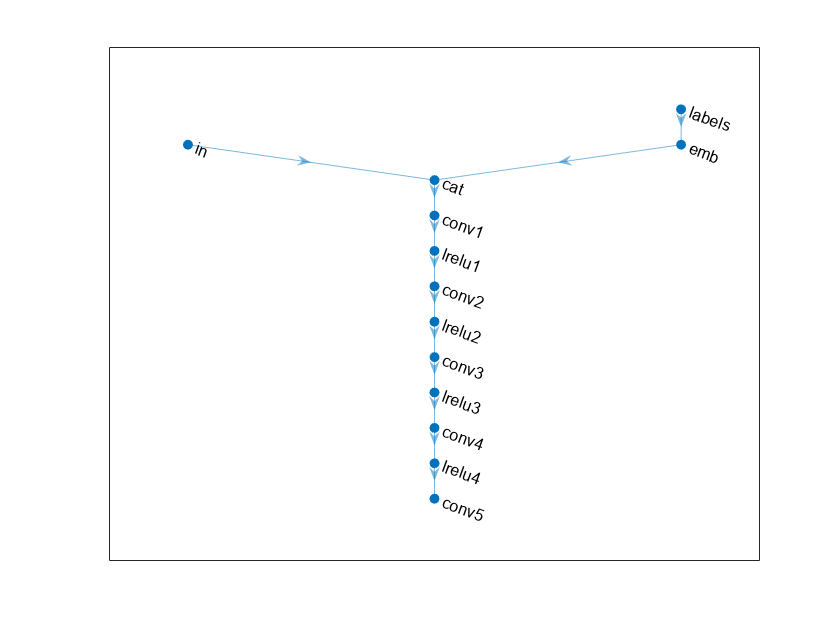
定义以下两个输入网络,把真实和生成1201 -的- 1信号给定一组信号及其对应的标签。
这个网络:
需要1201 -通过- 1 - 1信号作为输入。
转换分类标签嵌入向量并重塑了他们1201 - 1 - 1阵列。
沿着通道连接的结果两个输入维度。输出是1201 - 1 - 1025的数组。
Downsamples标量预测分数,结果数组1-by-1-by-1数组,使用一系列一维卷积层和漏ReLU层规模为0.2。
%鉴别器网络规模= 0.2;inputSize = (1201 1);layersDiscriminator = [imageInputLayer inputSize,“归一化”,“没有”,“名字”,“在”)concatenationLayer (3 2“名字”,“猫”)convolution2dLayer ([17 1] 8 * numFilters,“步”2,“填充”(1 0),“名字”,“conv1”)leakyReluLayer(规模、“名字”,“lrelu1”)convolution2dLayer (4 * numFilters [16 1],“步”4“填充”(1 0),“名字”,“conv2”)leakyReluLayer(规模、“名字”,“lrelu2”)convolution2dLayer (2 * numFilters [16 1],“步”4“填充”(1 0),“名字”,“conv3”)leakyReluLayer(规模、“名字”,“lrelu3”1)convolution2dLayer ([8], numFilters“步”4“填充”(1 0),“名字”,“conv4”)leakyReluLayer(规模、“名字”,“lrelu4”1)convolution2dLayer ([8], 1“名字”,“conv5”));lgraphDiscriminator = layerGraph (layersDiscriminator);层= [imageInputLayer ([1],“名字”,“标签”,“归一化”,“没有”)embedAndReshapeLayer (inputSize embeddingDimension numClasses,“循证”));lgraphDiscriminator = addLayers (lgraphDiscriminator层);lgraphDiscriminator = connectLayers (lgraphDiscriminator,“循证”,“猫/ in2”);
鉴频器的网络结构。
情节(lgraphDiscriminator)
训练网络使用一个自定义训练循环和启用自动分化、转换层图dlnetwork对象。
dlnetDiscriminator = dlnetwork (lgraphDiscriminator);
火车模型
火车CGAN模型使用自定义训练循环。循环训练数据和更新网络参数在每个迭代。监控培训进展,使用两个固定数组显示生成的健康和故障信号的随机值输入到发电机以及成绩的两个网络的阴谋。
对于每一个时代,洗牌的训练数据和遍历mini-batches数据。
为每个mini-batch:
生成一个
dlarray对象包含一组随机值生成器网络。GPU培训,将数据转换成
gpuArray(并行计算工具箱)对象。评估模型梯度使用
dlfeval和辅助功能modelGradients。更新网络参数使用
adamupdate函数。
辅助函数modelGradients需要作为输入生成器和鉴别器网络,mini-batch输入数据,和随机值的数组,并返回损失的梯度对可学的参数在网络和两个网络的分数。损失函数中定义的helper函数ganLoss。
指定培训选项
设置训练参数。
参数个数。numLatentInputs = numLatentInputs;参数个数。numClasses = numClasses;参数个数。sizeData = [inputSize长度(标签)];参数个数。numEpochs = 1000;参数个数。miniBatchSize = 256;%为亚当优化器指定选项参数个数。learnRate = 0.0002;参数个数。gradientDecayFactor = 0.5;参数个数。squaredGradientDecayFactor = 0.999;
设置在CPU上运行CGANs执行环境。运行在GPU CGANs,集executionEnvironment“gpu”或选择“运行在GPU在编辑器活”选项。使用GPU需要并行计算工具箱™。看到支持gpu,明白了万博1manbetxGPU的万博1manbetx支持版本(并行计算工具箱)。
executionEnvironment = “cpu”;参数个数。executionEnvironment = executionEnvironment;
“cpu”;参数个数。executionEnvironment = executionEnvironment;

跳过加载pretrained网络的训练过程。培训网络在你的电脑上,集trainNow来真正的或选择“现在火车CGAN”选项编辑器。
trainNow =假;如果trainNow%训练CGAN[dlnetGenerator, dlnetDiscriminator] = trainGAN (dlnetGenerator,…dlnetDiscriminator flowNormalized,标签,params);% #好吧其他的%使用pretrained CGAN(默认)负载(fullfile (tempdir“PumpSignalGAN”,“GANModel.mat”))%加载数据集结束
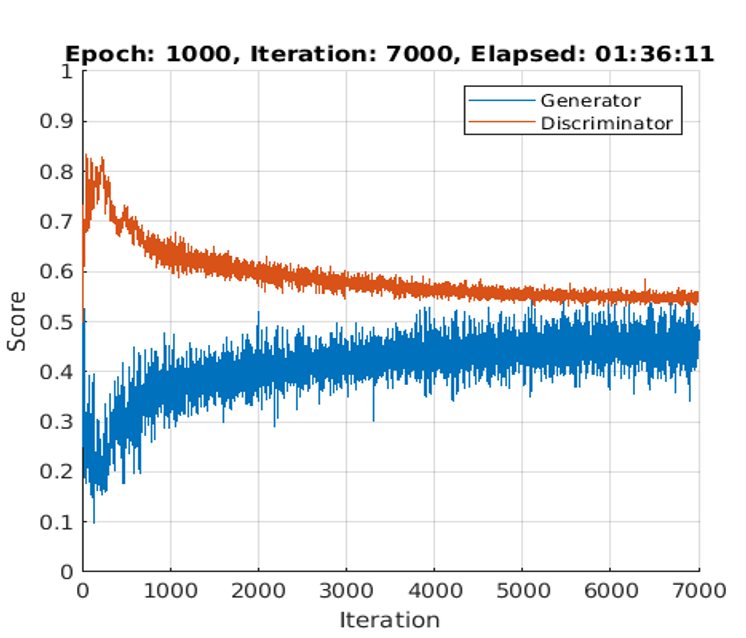
下面的训练图显示了一个示例的分数发生器和鉴别器网络。了解更多关于如何解释网络分数,看看监测GAN培训进展并确定常见的失效模式。在这个例子中,发电机和鉴频器的收敛接近0.5,表明训练性能好。
合成流信号
创建一个dlarray对象包含一批1 - 2000 - 1 -到- 100随机值数组输入生成器网络。重置的随机数字生成器可重复的结果。
rng默认的numTests = 2000;ZNew = randn (1, 1, numLatentInputs numTests,“单一”);dlZNew = dlarray (ZNew,“SSCB”);
指定第一个1000个随机阵列是健康的,其余的都是错误的。
TNew = 1 (1, 1, 1, numTests,“单一”);TNew (1, 1, 1, numTests / 2 + 1:结束)=单(2);dlTNew = dlarray (TNew,“SSCB”);
使用GPU来产生信号,转换数据gpuArray对象。
如果executionEnvironment = =“图形”dlZNew = gpuArray (dlZNew);dlTNew = gpuArray (dlTNew);结束
使用预测函数发生器与批1 -到- 1 -到- 100随机值数组和标签来生成合成信号和恢复执行的标准化步骤中,您在原始流信号。
dlXGeneratedNew =预测(dlnetGenerator dlZNew dlTNew) * stdFlow + meanFlow;
信号特征可视化
与图像和音频信号,一般信号特征,人类的感知使他们难以分辨。比较真实的和生成的信号或健康的和错误的信号,您可以应用主成分分析(PCA)真正的信号的统计特性,然后项目的特点生成的信号相同的PCA子空间。
特征提取
结合原始真实信号和生成的信号在一个数据矩阵。使用辅助函数extractFeatures提取特征包括常见信号均值和方差等统计数据以及光谱特征。
idxGenerated = 1: numTests;idxReal = numTests + 1: numTests +大小(流,2);XGeneratedNew =挤压(extractdata(收集(dlXGeneratedNew)));x = [XGeneratedNew单(流)];特点= 0(大小(x, 2), 14日“喜欢”,x);为2 = 1:尺寸(x, 2)特性(二世:)= extractFeatures (x (:, ii));结束
每一行的特性对应于一个信号的特点。
修改生成的标签健康和错误的信号以及真正的健康和错误的信号。
L =[挤压(TNew) + 2;标签。');
标签现在有这些定义:
1 -生成健康的信号
2 -生成错误的信号
3 -真正的健康信号
4 -真正的故障信号
主成分分析
执行真正的PCA特征信号和项目的特点生成的信号相同的PCA子空间。W是系数,Y是分数。
% PCA通过圣言featuresReal =特性(idxReal:);μ=意味着(featuresReal, 1);[~ S W] =圣言(featuresReal-mu);S =诊断接头(年代);Y = (features-mu) * W;
从奇异向量年代,前三个奇异值占99%的能量年代。你可以想象的信号特性,利用前三个主成分。
sum (S (1:3)) / (S)和
ans =单0.9923
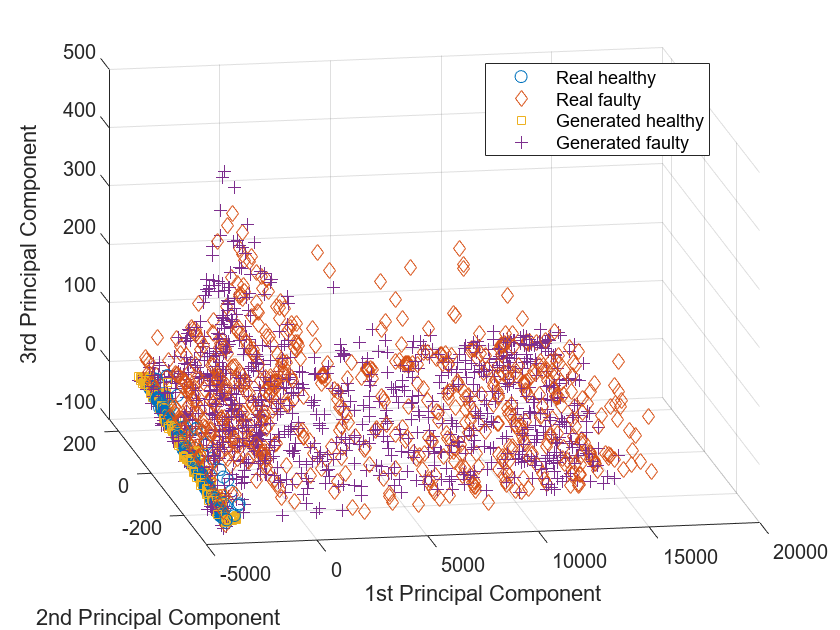
情节的特征信号使用前三个主成分。PCA子空间的分布生成的信号类似于真实的信号。
idxHealthyR = L = = 1;idxFaultR = L = = 2;idxHealthyG = L = = 3;idxFaultG = L = = 4;页= Y (:, 1:3);图scatter3 (pp (idxHealthyR, 1)、pp (idxHealthyR, 2)、pp (idxHealthyR, 3),“o”)包含(第一主成分的)ylabel (第二主成分的)zlabel (第三主成分的)举行在scatter3 (pp (idxFaultR, 1), pp (idxFaultR, 2)、pp (idxFaultR, 3),' d ')scatter3 (pp (idxHealthyG, 1)、pp (idxHealthyG, 2)、pp (idxHealthyG, 3),“年代”)scatter3 (pp (idxFaultG, 1)、pp (idxFaultG, 2)、pp (idxFaultG, 3),“+”(-10年,20)传说)视图(真正的健康的,“真正的问题”,“生成健康”,“生成错误的”,…“位置”,“最佳”)举行从
更好地捕捉真正的信号和生成的信号之间的区别,子空间使用前两个主成分的阴谋。
视图(2)
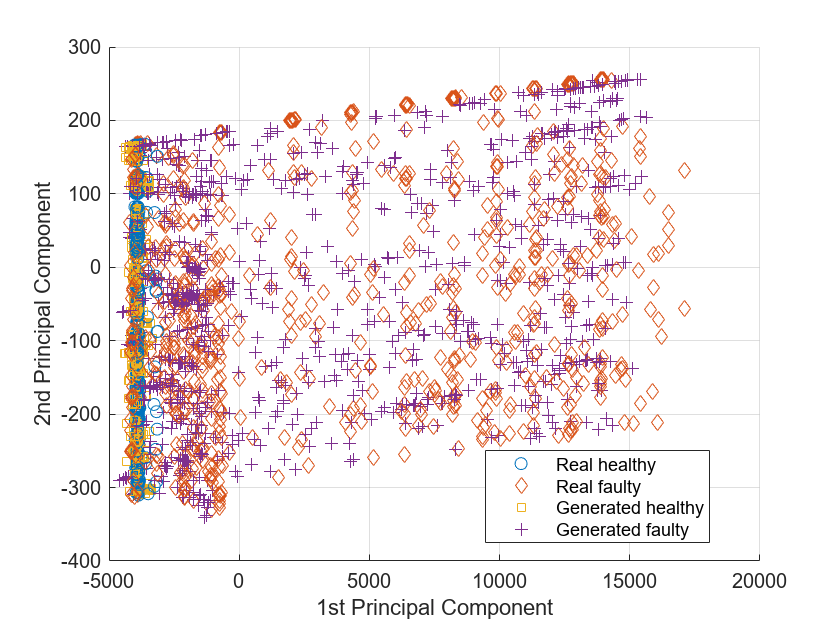
健康和故障信号躺在同一地区的PCA子空间不管他们的真实的或生成,说明生成的信号功能类似的信号。
预测标签的信号
进一步说明CGAN的性能,火车一个支持向量机分类器基于生成的信号,然后预测是否真正的信号是健康的或错误的。
设置生成的信号作为训练数据集和真实的信号作为测试数据集。数字标签更改为特征向量。
标签= {“健康”,“错误”};strL =标签([挤压(TNew);标签。”)。“;dataTrain =特性(idxGenerated:);人数(=特性(idxReal:);labelTrain = strL (idxGenerated);labelTest = strL (idxReal);预测= dataTrain;响应= labelTrain;本量利= cvpartition(大小(预测,1),“KFold”5);
火车一个支持向量机分类器使用生成的信号。
SVMClassifier = fitcsvm (…预测(cvp.training (1):)…响应(cvp.training (1)),“KernelFunction”,多项式的,…“PolynomialOrder”2,…“KernelScale”,“汽车”,…“BoxConstraint”,1…“类名”、标签…“标准化”,真正的);
使用训练分类器获得真正的信号预测标签。分类器达到预测精度在90%以上。
actualValue = labelTest;predictedValue =预测(SVMClassifier、人数();predictAccuracy =意味着(cellfun (@strcmp, actualValue predictedValue))
predictAccuracy = 0.9460
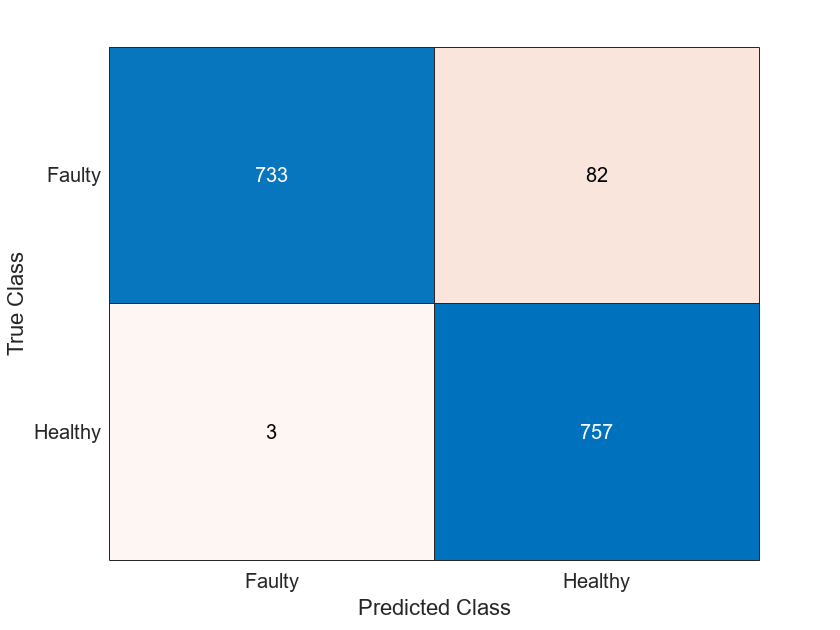
使用一个混淆矩阵查看详细信息为每个类别预测性能。混淆矩阵表明,在每个类别,分类器训练基于生成的信号达到高度的准确性。
图confusionchart (actualValue predictedValue)
案例研究
比较真实的光谱特性和生成的信号。由于GPU的不确定性行为训练,如果你CGAN模型训练自己,您的结果可能不同于这个例子中的结果。
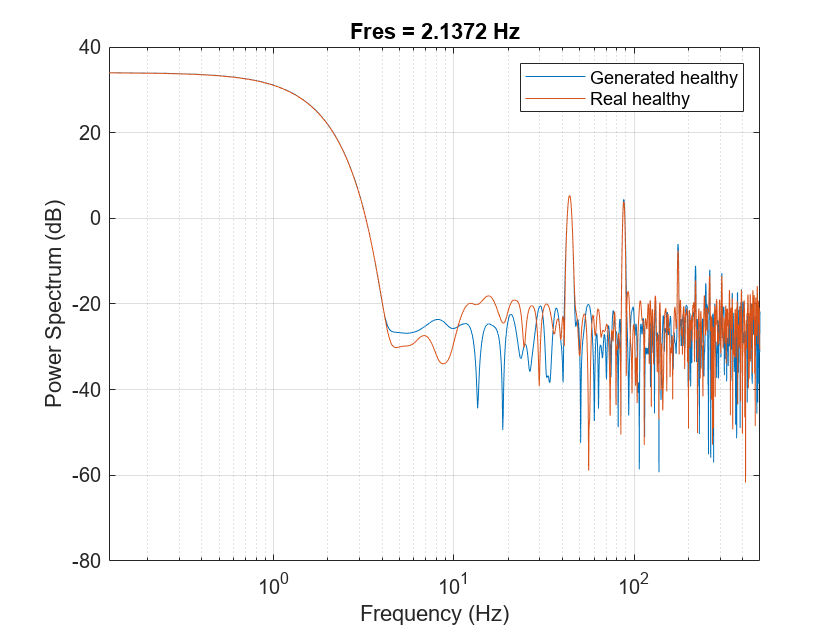
泵电动机转速为950 rpm,或15.833赫兹,由于泵有三个缸流量预计将有一个基本在3 * 15.833赫兹,或47.5赫兹,谐波的倍数47.5赫兹。画出频谱的一个案例中真正的和生成的健康信号。从情节,生成的健康信号相对高功率值在47.5赫兹和2 * 47.5赫兹,一模一样的真正的健康信号。
Fs = 1000;pspectrum ([x (: 1) x (:, 2006)], Fs)组(gca),“XScale”,“日志”)传说(“生成健康”,真正的健康的)
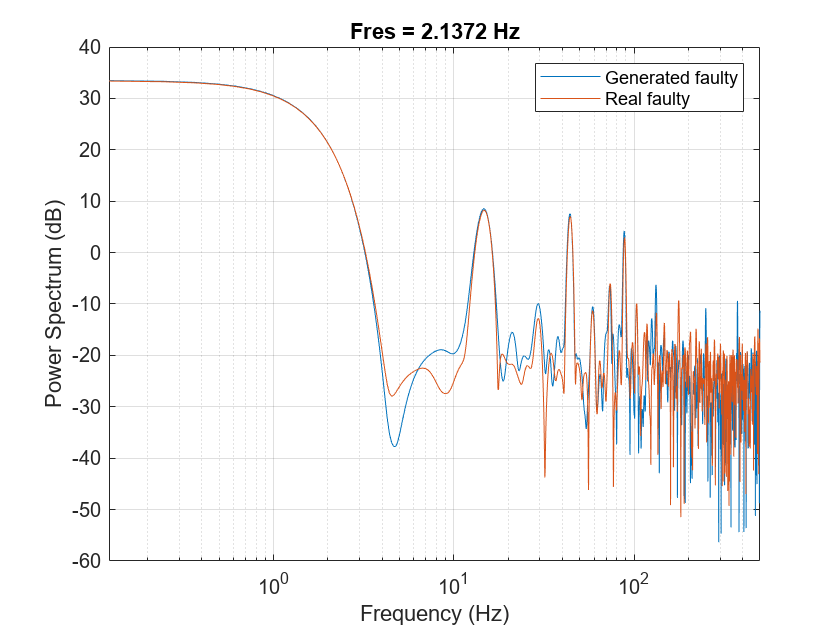
如果故障存在,会发生共振泵电动机转速,15.833赫兹,和它的谐波。情节产生的光谱为一个真正的和错误的信号。生成的信号相对高功率值在15.833赫兹及其谐波,这类似于真正的故障信号。
pspectrum ([x (:, 1011) (:, 2100)], Fs)组(gca),“XScale”,“日志”)传说(“生成错误的”,“真正的问题”)
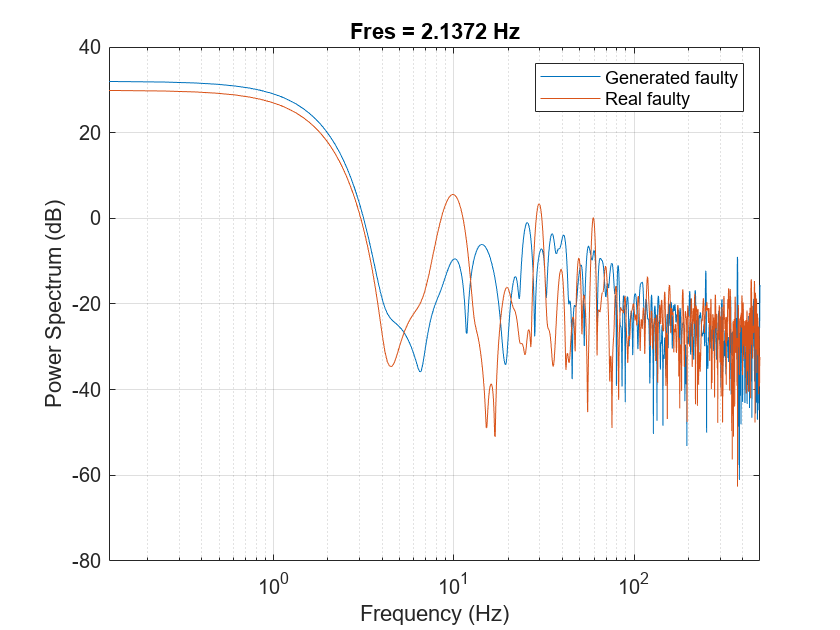
情节谱生成另一个真正的和错误的信号。生成的错误信号的光谱特性不匹配理论分析非常好,不同于真正的故障信号。CGAN仍然可以通过调优网络结构或hyperparameters可能改善。
pspectrum ([x (:, 1001) (:, 2600)], Fs)组(gca),“XScale”,“日志”)传说(“生成错误的”,“真正的问题”)
计算时间
仿真软件万博1manbetx仿真需要大约14个小时产生2000泵流量信号。这个时间可以减少到大约1.7小时与八个平行的工人如果有并行计算工具箱™。
CGAN需要1.5个小时的火车,70秒生成等量的合成数据的NVIDIA GPU泰坦V。
