多输出训练网络
此示例示出了如何训练深度学习网络与预测二者的标签和的手写体数字旋转角度的多个输出。
要训练具有多个输出的网络,必须将网络指定为一个函数,并使用自定义训练循环对其进行训练。
负荷训练数据
该digitTrain4DArrayData函数从垂直方向加载图像、数字标签和旋转角度。
[XTrain, YTrain anglesTrain] = digitTrain4DArrayData;一会=类别(YTrain);numClasses =元素个数(类名);numObservations =元素个数(YTrain);
从训练数据查看一些图片。
idx = randperm (numObservations, 64);我= imtile (XTrain (:,:,:, idx));图imshow(我)

定义深度学习模式
定义下列网络预测的标签,以及旋转角度。
甲卷积batchnorm-RELU块具有16个5×5滤波器。
每两个卷积batchnorm块的分支与32 3×3的过滤器之间具有RELU操作
跳过与卷积batchnorm块连接用32 1乘1卷积。
同时结合了分支机构使用加法后面是RELU操作
对于回归输出,具有尺寸1(响应数)的完全连接操作的分支。
对于分类输出,一个分支具有大小为10(类的数量)的完全连接操作和一个softmax操作。
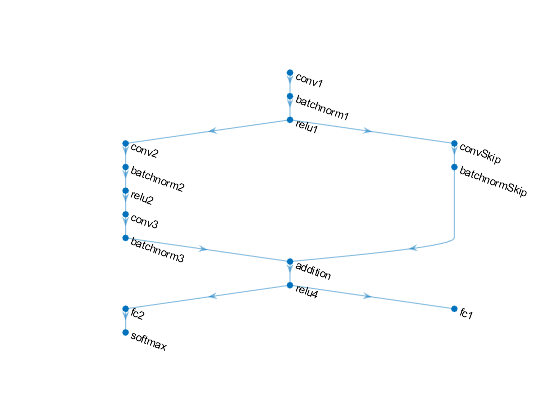
定义和初始化模型参数和状态
定义参数,每个操作并包括在结构中。使用格式parameters.OperationName.ParameterName在哪里参数结构是O吗perationName是操作的名称(例如“conv_1”)和参数名称为参数(例如,“权重”)的名称。
创建一个struct参数包含模型参数。使用示例函数初始化可学习层的权重initializeGaussian,在示例的最后列出。用零初始化可学习层偏差。分别用0和1初始化批处理归一化偏移量和标度参数。
用来执行训练和使用批标准化层推断,你还必须管理网络状态。预测之前,您必须指定数据集的均值和方差从训练数据导出。创建一个struct状态包含的状态参数。初始化批标准化训练的均值和方差的培训与国零和一,分别。
parameters.conv1。重量= dlarray (initializeGaussian ([5、5、1、16]));parameters.conv1。偏见= dlarray (0 (16 1'单'));parameters.batchnorm1。1,抵消= dlarray(0(16日'单'));parameters.batchnorm1.Scale = dlarray(酮(16,1,'单'));state.batchnorm1。1,TrainedMean = 0(16日'单');state.batchnorm1。1,TrainedVariance = 1(16日'单');parameters.convSkip.Weights = dlarray(initializeGaussian([1,1,16,32]));parameters.convSkip.Bias = dlarray(零(32,1,'单'));parameters.batchnormSkip.Offset = dlarray(零(32,1,'单'));parameters.batchnormSkip。= dlarray(的规模(32 1'单'));state.batchnormSkip.TrainedMean =零(32,1,'单');state.batchnormSkip。TrainedVariance = 1 (32 1'单');parameters.conv2.Weights = dlarray(initializeGaussian([3,3,16,32]));parameters.conv2.Bias = dlarray(零(32,1,'单'));parameters.batchnorm2。抵消= dlarray (0 (32 1'单'));parameters.batchnorm2.Scale = dlarray(酮(32,1,'单'));state.batchnorm2。TrainedMean = 0 (32 1'单');state.batchnorm2.TrainedVariance =酮(32,1,'单');parameters.conv3.Weights = dlarray(initializeGaussian([3,3,32,32]));parameters.conv3.Bias = dlarray(零(32,1,'单'));parameters.batchnorm3.Offset = dlarray(零(32,1,'单'));parameters.batchnorm3.Scale = dlarray(酮(32,1,'单'));state.batchnorm3.TrainedMean =零(32,1,'单');state.batchnorm3.TrainedVariance =酮(32,1,'单');parameters.fc2.Weights = dlarray(initializeGaussian([10,6272]));parameters.fc2.Bias = dlarray(零(numClasses,1,'单'));parameters.fc1.Weights = dlarray(initializeGaussian([1,6272]));parameters.fc1.Bias = dlarray(零(1,1,'单'));
查看参数的结构。
参数
参数=同场的结构:器CONV1:[1×1结构] batchnorm1:[1×1结构] convSkip:[1×1结构] batchnormSkip:[1×1结构] CONV2:[1×1结构] batchnorm2:[1×1结构] conv3:[1×1结构] batchnorm3:[1×1结构] FC2:[1×1结构] FC1:[1×1结构]
查看参数为“CONV1”操作。
parameters.conv1
ANS =同场的结构:重量:[5×5×1×16 dlarray]偏压:[16×1 dlarray]
查看状态的结构。
状态
状态=同场的结构:batchnorm1:[1 * 1结构]batchnormSkip:[1 * 1结构]
查看状态参数为“batchnorm1”操作。
state.batchnorm1
ANS =同场的结构:TrainedMean:[16×1单] TrainedVariance:[16×1单]
定义型号功能
创建函数模型在该示例的末尾列出的,其计算所述深度学习模型的输出如前所述。
这个函数模型获取输入数据DLX,模型参数参数,旗doTraining指定是否模型应返回输出,用于训练或预测,并且所述网络状态状态。网络输出用于标签的预测,预测为角度,和更新的网络状态。
定义模式渐变功能
创建函数modelGradients,它接受一小批输入数据DLX与相应的目标T1和T2分别包含标签和角度,返回损失相对于可学习参数的梯度、更新后的网络状态和相应的损失。
指定培训选项
指定培训选项。
numEpochs = 30;miniBatchSize = 128;地块=“训练进步”;
如果有的话,在GPU上进行训练。这需要并行计算工具箱™。使用GPU需要Parallel Computing Toolbox™和支持CUDA®的NVIDIA®GPU,计算能力为3.0或更高。
执行环境=“汽车”;
火车模型
使用自定义训练循环训练模型。
对于每一个时代,洗牌对数据的小批量数据和循环。在每个历元的端部,显示训练进度。
对于每个小批量:
转换的标签,以虚拟变量。
转换的数据
dlarray有基础型单对象,并指定尺寸的标签“SSCB”(空间、空间、通道、批处理)对于GPU训练,转换成
gpuArray对象。评估模型梯度和损失使用
dlfeval和modelGradients功能。更新使用的网络参数
adamupdate功能。
初始化训练进度图。
如果地块==“训练进步”图形lineLossTrain = animatedline('颜色',[0.85 0.325 0.098]);ylim([0 INF])xlabel(“迭代”)ylabel (“失利”)网格在结束
初始化参数亚当。
trailingAvg = [];trailingAvgSq = [];
训练模型。
numIterationsPerEpoch =地板(numObservations./miniBatchSize);迭代= 0;开始=抽动;%遍历时期。对于时代= 1:numEpochs%随机数据。IDX = randperm(numObservations);XTrain = XTrain(:,:,:,IDX);YTrain = YTrain(IDX);anglesTrain = anglesTrain(IDX);在小批量%环对于I = 1:numIterationsPerEpoch迭代=迭代+ 1;IDX =(I-1)* miniBatchSize + 1:我* miniBatchSize;数据的读%小批量和转换标签哑%变量。X = XTrain (:,:,:, idx);Y1 = 0 (numClasses, miniBatchSize,'单');对于C = 1:numClasses Y1(C,YTrain(IDX)==类名(C))= 1;结束Y2 = anglesTrain (idx)”;Y2 =单(Y2);%转换小批量数据的dlarray。DLX = dlarray(X,“SSCB”);%如果在GPU训练,然后数据转换为gpuArray。如果(执行环境==“汽车”&& canUseGPU)||执行环境==“图形”dlX = gpuArray (dlX);结束%使用dlfeval和the评估模型梯度、状态和损失%modelGradients功能。[梯度,状态,损失] = dlfeval(@modelGradients,DLX,Y1,Y2,参数,状态);%更新使用ADAM优化网络参数。[参数,trailingAvg,trailingAvgSq] = adamupdate(参数,渐变…trailingAvg trailingAvgSq,迭代);%显示训练进度。如果地块==“训练进步”D =持续时间(0,0,toc(开始),“格式”,'HH:MM:SS');addpoints(lineLossTrain,迭代,双(聚(ExtractData由(亏损))))标题(”时代:“+划时代+“消逝”+ drawnow字符串(D))结束结束结束
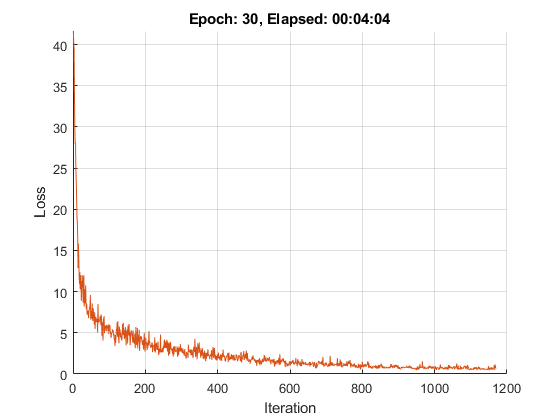
测试模型
通过测试集上的预测与真实的标签和角度进行比较,检验模型的分类精度
[XTEST,YTest,anglesTest] = digitTest4DArrayData;
转换数据到dlarray与尺寸格式对象“SSCB”。对于GPU的预测,也将数据转换成gpuArray。
dlXTest = dlarray(XTEST,“SSCB”);如果(执行环境==“汽车”&& canUseGPU)||执行环境==“图形”dlXTest = gpuArray (dlXTest);结束
利用模型函数对验证数据进行标签和角度的预测doTraining选项设置为假。
doTraining = false;[dlYPred,anglesPred] = model(dlXTest, parameters,doTraining,state);
评估分类精度。
[〜,IDX] = MAX(ExtractData由(dlYPred),[],1);labelsPred =类名(IDX);精度=平均值(labelsPred == YTest)
精度= 0.9644
评估回归精度。
angleRMSE = SQRT(平均值((ExtractData由(anglesPred) - anglesTest')^ 2))。
angleRMSE = gpuArray单5.8081
查看一些图片和他们的预测。红色显示预测的角度,绿色显示正确的标签。
IDX = randperm(大小(XTEST,4),9);数字对于i = XTest(:,:,:,idx(i));imshow (I)在SZ =尺寸(I,1);偏移量= SZ / 2;thetaPred = ExtractData由(anglesPred(IDX(I)));情节(偏移* [1-t和(thetaPred)1 + t和(thetaPred)],[SZ 0],'R--')thetaValidation = anglesTest(IDX(I));情节(偏移* [1-t和(thetaValidation)1 + t和(thetaValidation)],[SZ 0],'G - ')举行离标记=串(labelsPred(IDX(I)));标题(“标签: ”+标签)结束

型号功能
这个函数模型获取输入数据DLX,模型参数参数,旗doTraining指定是否模型应返回输出,用于训练或预测,并且所述网络状态状态。网络输出用于标签的预测,预测为角度,和更新的网络状态。
函数[DLY1,DLY2,状态] =模型(DLX,参数,doTraining,状态)卷积%W = parameters.conv1.Weights;B = parameters.conv1.Bias;海底= dlconv (dlX, W, B,'填充'2);%批次正常化,RELU抵消= parameters.batchnorm1.Offset;规模= parameters.batchnorm1.Scale;trainedMean = state.batchnorm1.TrainedMean;trainedVariance = state.batchnorm1.TrainedVariance;如果doTraining [DLY,trainedMean,trainedVariance] = batchnorm(DLY,偏移,比例trainedMean,trainedVariance);%更新状态state.batchnorm1.TrainedMean = trainedMean;state.batchnorm1.TrainedVariance = trainedVariance;其他DLY = batchnorm(DLY,偏移,比例trainedMean,trainedVariance);结束DLY = RELU(DLY);%卷积,批标准化(跳过连接)W = parameters.convSkip.Weights;B = parameters.convSkip.Bias;dlYSkip = dlconv(海底,W, B,“跨越论”2);抵消= parameters.batchnormSkip.Offset;规模= parameters.batchnormSkip.Scale;trainedMean = state.batchnormSkip.TrainedMean;trainedVariance = state.batchnormSkip.TrainedVariance;如果doTraining [dlYSkip,trainedMean,trainedVariance] = batchnorm(dlYSkip,偏移,比例trainedMean,trainedVariance);%更新状态state.batchnormSkip.TrainedMean = trainedMean;state.batchnormSkip.TrainedVariance = trainedVariance;其他dlYSkip = batchnorm(dlYSkip,偏移,比例trainedMean,trainedVariance);结束卷积%W = parameters.conv2.Weights;B = parameters.conv2.Bias;DLY = dlconv(DLY,W,B,'填充'1,“跨越论”2);%批次正常化,RELU偏移量= parameters.batchnorm2.Offset;比例= parameters.batchnorm2.Scale;trainedMean = state.batchnorm2.TrainedMean;trainedVariance = state.batchnorm2.TrainedVariance;如果doTraining [DLY,trainedMean,trainedVariance] = batchnorm(DLY,偏移,比例trainedMean,trainedVariance);%更新状态state.batchnorm2.TrainedMean = trainedMean;state.batchnorm2.TrainedVariance = trainedVariance;其他DLY = batchnorm(DLY,偏移,比例trainedMean,trainedVariance);结束DLY = RELU(DLY);卷积%W = parameters.conv3.Weights;B = parameters.conv3.Bias;DLY = dlconv(DLY,W,B,'填充',1);%批标准化偏移量= parameters.batchnorm3.Offset;比例= parameters.batchnorm3.Scale;trainedMean = state.batchnorm3.TrainedMean;trainedVariance = state.batchnorm3.TrainedVariance;如果doTraining [DLY,trainedMean,trainedVariance] = batchnorm(DLY,偏移,比例trainedMean,trainedVariance);%更新状态state.batchnorm3.TrainedMean = trainedMean;state.batchnorm3.TrainedVariance = trainedVariance;其他DLY = batchnorm(DLY,偏移,比例trainedMean,trainedVariance);结束%的添加,RELUdlY = dlYSkip + dlY;DLY = RELU(DLY);%完全连接(角度)W = parameters.fc1.Weights;B = parameters.fc1.Bias;DLY2 = fullyconnect(DLY,W,B);%通透,SOFTMAX(标签)W = parameters.fc2.Weights;B = parameters.fc2.Bias;dlY1 = fullyconnect(海底,W, B);dlY1 = softmax (dlY1);结束
型号渐变功能
该modelGradients功能,需要小批量的输入数据的DLX与相应的目标T1和T2分别包含标签和角度,返回损失相对于可学习参数的梯度、更新后的网络状态和相应的损失。
函数[梯度,状态,损失] = modelGradients(DLX,T1,T2,参数,状态)doTraining = TRUE;[DLY1,DLY2,状态] =模型(DLX,参数,doTraining,状态);lossLabels = crossentropy(DLY1,T1);lossAngles = MSE(DLY2,T2);损耗= lossLabels + 0.1 * lossAngles;梯度= dlgradient(损耗,参数);结束
权重初始化函数
该initializeGaussian从高斯分布均值为0,标准偏差0.01函数的样品重量。
函数参数= initializeGaussian(SZ)参数= randn(SZ,'单')* 0.01;结束
也可以看看
batchnorm|dlarray|dlconv|dlfeval|dlgradient|fullyconnect|线性整流函数(Rectified Linear Unit)|sgdmupdate|softmax
相关的话题
您也可以从以下列表中选择网站:
