使用LMS和NLMS算法的信号增强
使用最小均线(LMS)和归一化LMS算法,通过滤除噪声来从噪声损坏信号中提取所需信号。这两种算法都可用dsp.lmsfilter.系统对象™。
创建用于适配的信号
所需的信号(过程输出)是每个帧的正弦曲线,每个样本有1000个样本。
正弦= dsp。SineWave (“频率”,375,'采样率', 8000,'samplesperframe',1000)
正弦= dsp。带属性的正弦波:振幅:1频率:375相位偏移:0 ComplexOutput: false方法:三角函数SampleRate: 8000 SamplesPerFrame: 1000 OutputDataType: 'double'
s = sin ();
要执行适配,过滤器需要两个信号:
参考信号
一种噪声信号,它既包含所需的信号,又包含附加的噪声成分
产生噪音信号
创建具有自回归噪声的噪声信号(定义为v1.)。在自回归噪声中,时间t的噪声仅取决于先前的值和随机干扰。
v = 0.8 * randn(sine.samplesperframe,1);%随机噪声部分。AR = [1,1 / 2];%autoregray系数。arfilt = dsp.iirfilter('分子',1,'分母',AR)
arfilt = dsp.iirfilter具有属性:结构:'直接表格II转置'分子:1分母:[1 0.5000]初始条件:0显示所有属性
v1 = arfilt(v);
破坏期望的信号以产生噪声信号
要生成包含所需信号和噪声的嘈杂信号,请添加噪声信号v1.到所需的信号S.。的正弦信号X是:
x = s + v1;
自适应滤波处理寻求恢复S.从X通过删除v1.。为了完成执行自适应滤波所需的信号,适应过程需要参考信号。
创建一个参考信号
定义移动平均信号v2.与之相关v1.。信号v2.是本例的参考信号。
ma = [1,-0.8,0.4,-0.2];mafilt = dsp.firfilter('分子',嘛)
mafilt = dsp.firfilter具有属性:结构:'直接表格'NumeratorSource:'属性'分子:[1 -0.8000 0.4000 -0.2000] Initialconditions:0显示所有属性
v2 = mafilt(v);
构造两个自适应滤波器
两个类似的,第六阶自适应滤波器 - LMS和NLMS - 形成此示例的基础。将订单设置为Matlab™中的变量,并创建过滤器。
L = 7;lms = dsp.lmsfilter(l,'方法'那'LMS')
LMS = DSP.LMSFilter具有属性:方法:'LMS'长度:7步骤源:'属性'步骤顺化:0.1000 Lifeta ofactor:1 initialconditions:0 AdaptInputport:False权重intinputport:false权重汇:'last'显示所有属性
nlms = dsp。LMSFilter (L,'方法'那'标准化LMS')
nlms = dsp。LMSFilter with properties: Method: 'Normalized LMS' Length: 7 StepSizeSource: 'Property' StepSize: 0.1000 LeakageFactor: 1 InitialConditions: 0 AdaptInputPort: false WeightsResetInputPort: false WeightsOutput: 'Last'显示所有属性
选择步长
LMS样算法具有步骤尺寸,用于确定应用于滤波器的校正量,从一个迭代到下一个迭代。太小的步长增加了过滤器收敛于一组系数的时间。太大的步长可能导致调整过滤器分歧,永不达到收敛。在这种情况下,所得到的滤波器可能不稳定。
通常,较小的步长提高了滤波器收敛以匹配未知系统的特性的准确性,以适应适应所需的时间。
这maxstep.功能dsp.lmsfilter.对象确定适用于每个LMS自适应滤波器算法的最大步长,以确保滤波器收敛到一个解决方案。通常,步长用µ表示。
[mumaxlms,mumaxmselms] = maxstep(lms,x)
mumaxlms = 0.2127
Mumaxmselms = 0.1312.
[mumaxnlms,mumaxmsenlms] = maxstep(nlms,x)
mumaxnlms = 2
mumaxmsenlms = 2
设置适度的过滤器步长
第一个输出maxstep.功能是系数要收敛的平均值所需的值,而第二输出是均方格系数收敛的值所需的值。选择大的阶梯尺寸通常会导致收敛值的大变化,因此通常选择较小的步长。
lms。StepSize = mumaxmselms / 30
LMS = DSP.LMSFilter具有属性:方法:“LMS”长度:7步骤源:'属性'步骤顺化:0.0044 Lifeta ofactor:1 industConitions:0 AdaptInputport:False权重键:false权力汇位:'last'显示所有属性
nlms.stepsize = mumaxmsenlms / 20
nlms = dsp。LMSFilter with properties: Method: 'Normalized LMS' Length: 7 StepSizeSource: 'Property' StepSize: 0.1000 LeakageFactor: 1 InitialConditions: 0 AdaptInputPort: false WeightsResetInputPort: false WeightsOutput: 'Last'显示所有属性
使用自适应滤波器过滤
您已经设置了自适应滤波器的参数,现在可以过滤噪声信号了。参考信号v2是自适应滤波器的输入。X是该配置中的期望信号。
通过适应,y,滤波器的输出,尝试尽可能地模拟x。
由于v2只与x的噪声分量v1相关,所以它只能真正模拟v1。误差信号(期望的x)减去实际输出y,构成对x部分不相关的估计,v2 - s是要从x中提取的信号。
[〜,elm,wlms] = lms(v2,x);[〜,lemms,wnlms] = nlms(v2,x);
计算最佳解决方案
例如,计算最佳FIR维纳滤波器。
重置(Mafilt);bw = firwiener(l-1,v2,x);%最佳冷杉维纳滤波器mafilt = dsp.firfilter('分子',BW)
Mafilt = DSP.Firfilter具有属性:结构:'直接表格'NumeratorSource:'Property'Umerator:[1.0001 0.3060 0.1050 0.0959 0.0477]初始化:0显示所有属性
yw = MAfilt (v2);使用Wiener滤波器估计xEw = x - yw;实际正弦波估计%
绘制结果
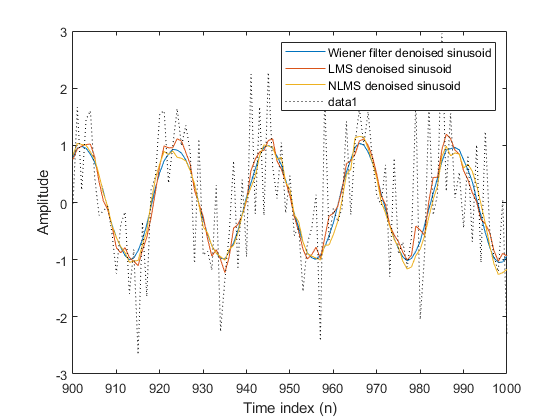
为每个滤波器绘制所产生的去噪正弦曲线 - Wiener滤波器,LMS自适应滤波器和NLMS自适应滤波器 - 以比较各种技术的性能。
n =(1:1000)';plot(n(900:结束),[EW(900:结束),ELMS(900:结束),lemms(900:结束)])传奇('Wiener过滤器去了正弦骨'那......'LMS denooze sinusoid'那'nlms denoised sinusoid')包含('时间索引(n)') ylabel ('振幅')
作为参考点,包括噪声信号作为图中的虚线。
抓住在绘图(n(900:结束),x(900:结束),'k:')包含('时间索引(n)') ylabel ('振幅')举行离开
比较最终系数
最后,将Wiener滤波器系数与自适应滤波器的系数进行比较。在调整时,Adaptive Filters尝试收敛到维纳系数。
[BW'。WLMS WNLMS]
ans =.7×31.0001 0.8644 0.9690 0.3060 0.1198 0.1198 0.2661 0.1050 -0.0020 0.1226 0.0482 -0.0046 0.074 0.1360 0.00680 0.2210 0.0959 0.0211 0.0959 0.0210 0.0959 0.0211 0.0959
过滤前重置过滤器
您可以通过调用的任何时间重置内部过滤器状态重启滤波器对象上的函数。
例如,这些连续调用在重置对象后产生相同的输出。
[ylms,榆树,wlm) = lms (v2, x);[ynlms, enlms wnlms] = nlms (v2, x);
如果未重置过滤器对象,则过滤器将使用前一个运行的最终状态和系数作为下一个运行的初始条件和数据集。
通过学习曲线调查融合
要分析自适应滤波器的收敛,请使用学习曲线。工具箱提供生成学习曲线的方法,但您需要多个实验迭代以获得显着的结果。
该示范使用嘈杂的正弦曲线的25个样本实现。
重置(arfilt)复位(正弦);释放(正弦);n =(1:5000)';sine.samplesperframe = 5000.
SINE = DSP.SINEWAVE具有属性:幅度:1频率:375相位OFFET:0 ComplexOutput:False方法:'三角函数'Samplere:8000 Sampleperframe:5000 OutputDatType:'Double'
s = sin ();nr = 25;v = 0.8 * randn (sine.SamplesPerFrame nr);arfilt = dsp.iirfilter('分子',1,'分母',AR)
arfilt = dsp.iirfilter具有属性:结构:'直接表格II转置'分子:1分母:[1 0.5000]初始条件:0显示所有属性
v1 = arfilt(v);x = REPMAT(S,1,NR)+ V1;重置(Mafilt);mafilt = dsp.firfilter('分子',嘛)
mafilt = dsp.firfilter具有属性:结构:'直接表格'NumeratorSource:'属性'分子:[1 -0.8000 0.4000 -0.2000] Initialconditions:0显示所有属性
v2 = mafilt(v);
计算学习曲线
现在计算平均方形错误。要加快速度,请每10个样本计算错误。
首先,重置自适应滤波器以避免使用已经计算的系数以及它存储的状态。然后绘制LMS和NLMS自适应滤波器的学习曲线。
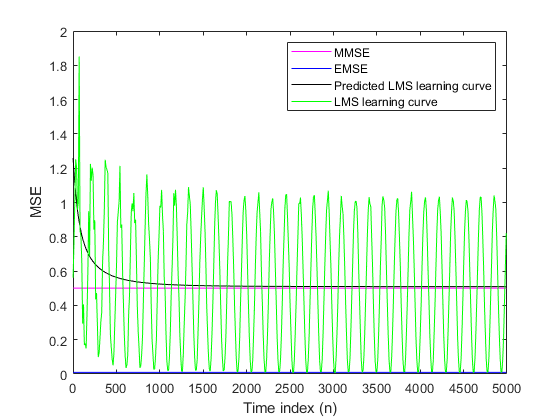
重置(LMS);重置(NLMS);m = 10;%抽取因子mselms = msesim(lms,v2,x,m);msenlms = msesim(nlms,v2,x,m);情节(1:M:N(END),MSELMS,'B'1: M: n(结束),msenlms,'G') 传奇('LMS学习曲线'那'nlms学习曲线')包含('时间索引(n)') ylabel ('妈妈')

在此情节中,您可以看到LMS和NLMS自适应滤波器的计算曲线。
计算理论学习曲线
对于LMS和NLMS算法,工具箱中的功能可帮助您计算理论学习曲线,以及最小均方误差(MMSE),多余的平均误差(EMSE)和系数的平均值。
Matlab可能需要一些时间来计算曲线。代码绘制预测和实际LMS曲线之后所示的图形。
重置(LMS);[MMSELMS,EMSELMS,MEALWLMS,PMSELMS] = MSEPRED(LMS,V2,X,M);x = 1:m:n(结束);Y1 = MMSELMS *那些(500,1);Y2 = Emselms *那些(500,1);y3 = pmselms;y4 = mselms;绘图(x,y1,“米”,x,y2,'B',x,y3,“k”,x,y4,'G') 传奇('mmse'那'emse'那'预测LMS学习曲线'那......'LMS学习曲线')包含('时间索引(n)') ylabel ('妈妈')
你也可以从以下列表中选择一个网站: