dsp。LMSFilter
计算LMS自适应滤波器的输出、误差和权重
描述
的dsp。LMSFilter系统对象™实现了一个自适应有限脉冲响应(FIR)滤波器,该滤波器使用以下算法之一将输入信号收敛到所需信号:
LMS
归一化LMS
Sign-Data LMS
符号误差LMS
Sign-Sign LMS
有关这些方法的详细信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">算法.
滤波器自适应其权重,直到主输入信号和所需信号之间的误差最小。该误差(MSE)的均方计算使用<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter.msesim.html">msesim函数。模型中的维纳滤波器确定了MSE的预测版本<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter.msepred.html">msepred函数。的<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter.maxstep.html">maxstep函数计算控制收敛速度的最大自适应步长。
有关自适应滤波方法的概述,以及自适应滤波最常见的应用,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ug/overview-of-adaptive-filters-and-applications.html" class="a">自适应滤波器及其应用概述.
使用自适应FIR滤波器对信号进行滤波:
创建
dsp。LMSFilter对象并设置其属性。调用带有参数的对象,就像调用函数一样。
要了解更多关于System对象如何工作的信息,请参见<一个href="//www.tianjin-qmedu.com/help/matlab/matlab_prog/what-are-system-objects.html" class="a">什么是系统对象?(MATLAB)。
创建
描述
lms= dsp。LMSFilterlms,该算法使用最小均方(LMS)算法计算给定输入和所需信号的滤波输出、滤波误差和滤波权值。
LMS = dsp。LMSFilter (返回一个LMS筛选器对象<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">长度属性设置为l)l.
LMS = dsp。LMSFilter (返回一个LMS筛选器对象,其中每个指定的属性设置为指定的值。将每个属性名用单引号括起来。您可以将此语法与前面的输入参数一起使用。名称,值)
属性
除非另有说明,属性为nontunable,这意味着在调用对象后不能更改它们的值。对象在调用时锁定,而<一个href="//www.tianjin-qmedu.com/help/matlab/ref/releasesystemobject.html">释放函数解锁它们。
如果属性是可调,您可以随时更改其值。
有关更改属性值的更多信息,请参见<一个href="//www.tianjin-qmedu.com/help/matlab/matlab_prog/system-design-in-matlab-using-system-objects.html" class="a">在MATLAB中使用系统对象设计系统(MATLAB)。
方法- - - - - -计算过滤器权重的方法
“LMS”(默认)|“归一化LMS”|“Sign-Data LMS”|“符号误差LMS”|“Sign-Sign LMS”
方法来计算过滤器权重,指定为以下之一:
“LMS”求解Weiner-Hopf方程,求出自适应滤波器的滤波系数。“归一化LMS”——LMS算法的归一化变异。“Sign-Data LMS”——每次迭代时对过滤器权值的修正取决于输入的符号x.“符号误差LMS”-每次迭代对当前过滤器权重的修正取决于错误的符号,犯错.“Sign-Sign LMS”——每次迭代对当前过滤器权重的修正取决于的符号x而符号犯错.
有关算法的详细信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">算法.
长度- - - - - -FIR滤波器权重向量的长度
32(默认)|正整数
FIR过滤器权重向量的长度,指定为正整数。
例子:64
例子:16
数据类型:单|双|int8|int16|int32|int64|uint8|uint16|uint32|uint64
StepSizeSource- - - - - -方法指定自适应步长
“属性”(默认)|输入端口的
方法指定自适应步长,指定为以下之一:
“属性”——财产<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">StepSize指定每个适应步骤的大小。输入端口的——指定自适应步长作为对象的输入之一。
StepSize- - - - - -适应步长
0.1(默认)|非负的标量
自适应步长因子,指定为非负标量。对于归一化LMS方法的收敛性,步长必须大于0小于2。
小的步长确保输出之间有小的稳态误差<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">y和期望的信号<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">d.步长越小,滤波器的收敛速度越慢。为了提高收敛速度,增大步长。注意,如果步长过大,过滤器会变得不稳定。要计算过滤器在不变得不稳定的情况下所能接受的最大步长,请使用<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter.maxstep.html">maxstep函数。
可调:是的
依赖关系
设置时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">StepSizeSource来“属性”.
数据类型:单|双|int8|int16|int32|int64|uint8|uint16|uint32|uint64
LeakageFactor- - - - - -泄漏LMS法中使用的泄漏因子
1(默认)|[0 1]
在实现泄漏LMS方法时使用的泄漏因子,指定为范围中的标量[0 1].当取值为1时,自适应方法不存在泄漏。当该值小于1时,过滤器实现漏LMS方法。
例子:0.5
可调:是的
数据类型:单|双|int8|int16|int32|int64|uint8|uint16|uint32|uint64
InitialConditions- - - - - -滤波器权值的初始条件
0(默认)|标量|向量
的值指定为标量或长度的向量<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">长度财产。当输入为实数时,该属性的值必须为实数。
例子:0
例子:[1 3 1 2 7 8 9 0 2 2 8 2]
数据类型:单|双|int8|int16|int32|int64|uint8|uint16|uint32|uint64
复数支持:万博1manbetx是的
AdaptInputPort- - - - - -标志以适应过滤器权重
假(默认)|真正的
标志以适应过滤器权重,指定为以下之一:
假——对象不断更新过滤器权重。真正的当你调用对象的算法时,它会提供一个自适应控制输入。如果该输入的值非零,则该对象持续更新过滤器权重。如果此输入的值为零,则过滤器权重保持当前值。
WeightsResetInputPort- - - - - -标志重置过滤器权重
假(默认)|真正的
标志重置过滤器权重,指定为以下之一:
假—对象不重设权重。真正的当你调用对象的算法时,一个重置控制输入被提供给对象。此设置启用<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">WeightsResetCondition财产。对象的值重置筛选器权重WeightsResetCondition属性和提供给对象算法的重置输入。
WeightsResetCondition- - - - - -事件重置过滤器权重
“零”(默认)|“前沿”|的下降沿|“要么边缘”
事件,触发过滤器权重的重置,指定为以下之一。每当在其重置输入中检测到重置事件时,该对象重置过滤器权重。
“零”——当重置输入不为零时,在每个采样点触发重置操作。“前沿”——当重置输入执行以下操作之一时触发重置操作:从负值上升到正值或零。
从0上升到正值,而不是从负值上升到零的延续。

的下降沿——当重置输入执行以下操作之一时触发重置操作:从正值下降到负值或零。
从0下降到负值,这种下降不是从正下降到零的延续。
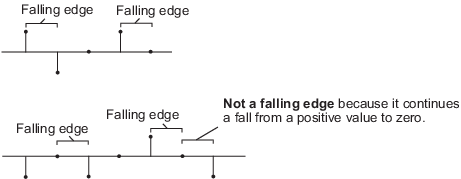
“要么边缘”—当重置输入是上升边或下降边时触发重置操作。


对象根据此属性的值和重置输入重置过滤器权重r提供给对象算法。
依赖关系
属性时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">WeightsResetInputPort财产真正的.
WeightsOutput- - - - - -方法来输出自适应的过滤器权重
“最后一次”(默认)|“没有”|“所有”
方法来输出适应的过滤器权重,指定为以下之一:
“最后一次”(默认)-对象返回一个权重的列向量,对应于数据帧的最后一个样本。权重向量的长度是由<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">长度财产。“所有”—对象返回aFrameLength——- - - - - -长度权矩阵。该矩阵对应于所有权重的完整样本历史FrameLength输入值的示例。矩阵中的每一行对应于为相应的输入样本计算的一组LMS滤波器权值。“没有”—此设置禁用权重输出。
定点属性
RoundingMethod- - - - - -定点运算的舍入方法
“地板”(默认)|“天花板”|“收敛”|“最近的”|“圆”|“简单”|“零”
指定定点操作的舍入模式。有关更多细节,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ug/concepts-and-terminology.html" class="a">舍入模式.
OverflowAction- - - - - -定点操作的溢出动作
“包装”(默认)|“饱和”
定点操作的溢出动作,指定为以下之一:
“包装”——对象包装其定点操作的结果。“饱和”——对象饱和其定点操作的结果。
有关溢出操作的详细信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ug/concepts-and-terminology.html" class="a">溢出模式对于定点运算。
StepSizeDataType- - - - - -步长、字长和分数长度设置
“与第一次输入的单词长度相同”(默认)|“自定义”
步长字长和分数长度设置,指定为以下之一:
“与第一次输入的单词长度相同”——对象指定字的步长与第一个输入相同。计算分数长度以获得最佳的精度。“自定义”方法将步长数据类型指定为自定义数字类型<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">CustomStepSizeDataType财产。
有关此对象使用的步长数据类型的更多信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">不动点部分。
CustomStepSizeDataType- - - - - -步长字和分式长度
numerictype([], 16岁,15)(默认)
步长的字长度和分数长度,指定为自签名数字类型,字长度为16,分数长度为15。
例子:numerictype ([], 32)
依赖关系
此属性适用于以下条件:
StepSizeSource属性设置为
“属性”而且<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">StepSizeDataType设置为“自定义”.StepSizeSource属性设置为输入端口的.
LeakageFactorDataType- - - - - -泄漏因子字长度和分数长度设置
“与第一次输入的单词长度相同”(默认)|“自定义”
泄漏因子字长度和分数长度设置,指定为以下之一:
“与第一次输入的单词长度相同”——对象指定泄漏因子的字长与第一个输入的字长相同。计算分数长度以获得最佳的精度。“自定义”方法将泄漏系数数据类型指定为自定义数字类型<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">CustomLeakageFactorDataType财产。
有关此对象使用的泄漏因子数据类型的更多信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">不动点部分。
CustomLeakageFactorDataType- - - - - -泄漏因子的字和分数长度
numerictype([], 16岁,15)(默认)
泄漏因子的字长度和分数长度,指定为自签名数字类型,字长度为16,分数长度为15。
例子:numerictype ([], 32)
依赖关系
属性时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">LeakageFactorDataType财产“自定义”.
WeightsDataType- - - - - -加权字长度和分数长度设置
“与第一次输入相同”(默认)|“自定义”
加权字长度和分数长度设置,指定为以下之一:
“与第一次输入相同”——对象指定过滤器权重的数据类型与第一个输入的数据类型相同。“自定义”方法将过滤器权重的数据类型指定为自定义数字类型<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">CustomWeightsDataType财产。
有关此对象使用的筛选器权重数据类型的详细信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">不动点部分。
CustomWeightsDataType- - - - - -过滤权值的字和分数长度
numerictype([], 16岁,15)(默认)
过滤器权重的字长度和分数长度,指定为自签名数字类型,字长度为16,分数长度为15。
例子:numerictype([], 32岁,20)
依赖关系
属性时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">WeightsDataType财产“自定义”.
EnergyProductDataType- - - - - -能源产品字长和分数长度设置
“与第一次输入相同”(默认)|“自定义”
能源产品字长和分数长度设置,指定为以下之一:
“与第一次输入相同”——对象指定能源产品的数据类型与第一次输入的数据类型相同。“自定义”方法将能源产品的数据类型指定为自定义数字类型<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">CustomEnergyProductDataType财产。
有关此对象使用的能源产品数据类型的更多信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">不动点部分。
依赖关系
属性时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">方法财产“归一化LMS”.
CustomEnergyProductDataType- - - - - -能量积的字和分数长度
numerictype([], 32岁,20)(默认)
能量乘积的字和分数长度,指定为自签名数字类型,字长度为32,分数长度为20。
依赖关系
属性时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">方法财产“归一化LMS”而且<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">EnergyProductDataType财产“自定义”.
EnergyAccumulatorDataType- - - - - -能量蓄能器字长度和分数长度设置
“与第一次输入相同”(默认)|“自定义”
能量累加器字长度和分数长度设置,指定为以下之一:
“与第一次输入相同”——对象指定能量蓄能器的数据类型与第一个输入的数据类型相同。“自定义”参数指定能量蓄能器的数据类型为自定义数字类型<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">CustomEnergyAccumulatorDataType财产。
有关此对象使用的能量累积器数据类型的更多信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">不动点部分。
依赖关系
属性时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">方法财产“归一化LMS”.
CustomEnergyAccumulatorDataType- - - - - -能量蓄能器的字和分数长度
numerictype([], 32岁,20)(默认)
能量累积器的字和分数长度,指定为自签名数字类型,字长度为32,分数长度为20。
依赖关系
属性时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">方法财产“归一化LMS”而且<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">EnergyAccumulatorDataType财产“自定义”.
ConvolutionProductDataType- - - - - -卷积积字长度和分数长度的设置
“与第一次输入相同”(默认)|“自定义”
卷积积字长度和分数长度设置,指定为以下之一:
“与第一次输入相同”——对象指定卷积积的数据类型与第一个输入的数据类型相同。“自定义”函数将卷积乘积的数据类型指定为自定义数值类型<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">CustomConvolutionProductDataType财产。
有关此对象使用的卷积积数据类型的更多信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">不动点部分。
CustomConvolutionProductDataType- - - - - -卷积积的字和分数的长度
numerictype([], 32岁,20)(默认)
卷积乘积的字长度和分数长度,指定为自签名数值类型,字长度为32,分数长度为20。
依赖关系
属性时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">ConvolutionProductDataType财产“自定义”.
ConvolutionAccumulatorDataType- - - - - -卷积累加器字长度和分数长度设置
“与第一次输入相同”(默认)|“自定义”
卷积累加器字长度和分数长度设置,指定为以下之一:
“与第一次输入相同”——对象指定卷积累加器的数据类型与第一个输入的数据类型相同。“自定义”函数将卷积累加器的数据类型指定为自定义数值类型<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">CustomConvolutionAccumulatorDataType财产。
有关此对象使用的卷积累加器数据类型的更多信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">不动点部分。
CustomConvolutionAccumulatorDataType- - - - - -卷积累加器的字和分数长度
numerictype([], 32岁,20)(默认)
卷积累加器的字长度和分数长度,指定为自签名数值类型,字长度为32,分数长度为20。
依赖关系
属性时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">ConvolutionAccumulatorDataType财产“自定义”.
StepSizeErrorProductDataType- - - - - -步长误差、乘积字长和分数长度设置
“与第一次输入相同”(默认)|“自定义”
步长误差积字长和分数长度设置,指定为以下之一:
“与第一次输入相同”——对象指定步长误差积的数据类型与第一个输入的数据类型相同。“自定义”方法将步长误差产品的数据类型指定为自定义数字类型<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">CustomStepSizeErrorProductDataType财产。
有关此对象使用的步长误差产品数据类型的详细信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">不动点部分。
CustomStepSizeErrorProductDataType- - - - - -步长误差乘积的字长度和分数长度
numerictype([], 32岁,20)(默认)
步长误差乘积的字长度和分数长度,指定为自签名数字类型,字长度为32,分数长度为20。
依赖关系
属性时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">StepSizeErrorProductDataType财产“自定义”.
WeightsUpdateProductDataType- - - - - -过滤器权重更新产品字长度和分数长度设置
“与第一次输入相同”(默认)|“自定义”
过滤器权重更新乘积的字和分数长度设置,指定为以下之一:
“与第一次输入相同”——对象指定过滤器权重更新产品的数据类型与第一个输入的数据类型相同。“自定义”方法将过滤器权重更新产品的数据类型指定为自定义数字类型<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">CustomWeightsUpdateProductDataType财产。
有关此对象使用的过滤器权重更新产品数据类型的详细信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">不动点部分。
CustomWeightsUpdateProductDataType- - - - - -过滤器权重的字和分数长度更新乘积
numerictype([], 32岁,20)(默认)
过滤器权重更新乘积的字和分数长度,指定为自签名数字类型,字长度为32,分数长度为20。
依赖关系
属性时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">WeightsUpdateProductDataType财产“自定义”.
QuotientDataType- - - - - -商字长度和分数长度设置
“与第一次输入相同”(默认)|“自定义”
商字长度和分数长度设置,指定为以下之一:
“与第一次输入相同”——对象指定商数数据类型与第一个输入相同。“自定义”方法将商数据类型指定为自定义数字类型<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">CustomQuotientDataType财产。
有关此对象使用的商数据类型的更多信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">不动点部分。
依赖关系
属性时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">方法财产“归一化LMS”.
CustomQuotientDataType- - - - - -商的字和分数长度
numerictype([], 32岁,20)(默认)
过滤器权重更新乘积的字和分数长度,指定为自签名数字类型,字长度为32,分数长度为20。
依赖关系
属性时应用此属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">方法财产“归一化LMS”而且<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">QuotientDataType财产“自定义”.
使用
语法
描述
[<一个href="#mw_4f7962fc-d669-4ca5-af7e-d27994ae7c12" class="intrnllnk">过滤输入信号,y,<一个href="#mw_1e74b671-711b-486a-a14f-3660a116662f" class="intrnllnk">犯错,<一个href="#mw_4e72967f-118d-4608-906e-5f36f4540872" class="intrnllnk">出世= lms(<一个href="#mw_530d713b-71b8-4a14-a78e-a000adad6302" class="intrnllnk">x,<一个href="#mw_db6b9f37-cc93-4e7f-8fd6-2bfe27289079" class="intrnllnk">d)x,使用d作为所需的信号,并返回过滤后的输出y,滤波器误差在犯错的估计滤波器权重出世.LMS滤波对象估计所需的滤波权值,以最小化输出信号和所需信号之间的误差。
[<一个href="#mw_4f7962fc-d669-4ca5-af7e-d27994ae7c12" class="intrnllnk">过滤输入信号,y,<一个href="#mw_1e74b671-711b-486a-a14f-3660a116662f" class="intrnllnk">犯错= lms(<一个href="#mw_530d713b-71b8-4a14-a78e-a000adad6302" class="intrnllnk">x,<一个href="#mw_db6b9f37-cc93-4e7f-8fd6-2bfe27289079" class="intrnllnk">d)x,使用d作为所需的信号,并返回过滤后的输出y和滤波器误差在犯错当<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">WeightsOutput属性设置为“没有”.
[___= lms(<一个href="#mw_530d713b-71b8-4a14-a78e-a000adad6302" class="intrnllnk">过滤输入信号,x,<一个href="#mw_db6b9f37-cc93-4e7f-8fd6-2bfe27289079" class="intrnllnk">d,<一个href="#mw_a361d18d-f06c-4d7e-8ebd-3054f34d39d4" class="intrnllnk">μ)x,使用d作为所需的信号和μ作为步长,当<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">StepSizeSource属性设置为输入端口的.这些输入可以与前一组输出中的任何一组一起使用。
[___= lms(<一个href="#mw_530d713b-71b8-4a14-a78e-a000adad6302" class="intrnllnk">过滤输入信号,x,<一个href="#mw_db6b9f37-cc93-4e7f-8fd6-2bfe27289079" class="intrnllnk">d,<一个href="#mw_cecf3006-18e5-4310-b90d-6809970ee595" class="intrnllnk">一个)x,使用d作为所需的信号和一个作为适应控制时<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">AdaptInputPort属性设置为真正的.当一个非零时,System对象持续更新过滤器权重。当一个为零时,滤波器权值保持不变。
[___= lms(<一个href="#mw_530d713b-71b8-4a14-a78e-a000adad6302" class="intrnllnk">过滤输入信号,x,<一个href="#mw_db6b9f37-cc93-4e7f-8fd6-2bfe27289079" class="intrnllnk">d,<一个href="#mw_db29e741-8beb-4e26-a9a8-29875bac5b1d" class="intrnllnk">r)x,使用d作为所需的信号和r作为复位信号时<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">WeightsResetInputPort属性设置为真正的.的<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">WeightsResetCondition属性可用于设置重置触发条件。如果发生重置事件,System对象将过滤器权重重置为初始值。
[<一个href="#mw_4f7962fc-d669-4ca5-af7e-d27994ae7c12" class="intrnllnk">过滤输入信号,y,<一个href="#mw_1e74b671-711b-486a-a14f-3660a116662f" class="intrnllnk">犯错,<一个href="#mw_4e72967f-118d-4608-906e-5f36f4540872" class="intrnllnk">出世= lms(<一个href="#mw_530d713b-71b8-4a14-a78e-a000adad6302" class="intrnllnk">x,<一个href="#mw_db6b9f37-cc93-4e7f-8fd6-2bfe27289079" class="intrnllnk">d,<一个href="#mw_a361d18d-f06c-4d7e-8ebd-3054f34d39d4" class="intrnllnk">μ,<一个href="#mw_cecf3006-18e5-4310-b90d-6809970ee595" class="intrnllnk">一个,<一个href="#mw_db29e741-8beb-4e26-a9a8-29875bac5b1d" class="intrnllnk">r)x,使用d作为所需信号,μ作为步长,一个作为适应控制,和r作为复位信号,并返回滤波后的输出y,滤波器误差在犯错,自适应滤波器权重为出世.
输入参数
输出参数
对象的功能
要使用对象函数,请将System对象指定为第一个输入参数。例如,释放名为obj,使用以下语法:
发行版(obj)
例子
LMS滤波器的均方误差预测
均方误差(MSE)测量自适应滤波器输入的期望信号和主信号之间误差的平方的平均值。减少这个误差将主要输入收敛到所需的信号。确定各时刻的均方误差预测值和模拟均方误差值msepred而且msesim功能。将这些MSE值相互比较,并与最小MSE值和稳态MSE值比较。另外,计算由系数协方差矩阵的迹给出的系数误差的平方和。
请注意:如果您使用的是R2016a或更早的版本,请用等效的步骤语法替换对对象的每次调用。例如,obj (x)就变成了步骤(obj, x).
初始化
创建一个dsp。FIRFilter表示未知系统的系统对象™。传递信号,x,到FIR滤波器。未知系统的输出是期望的信号,d,它是未知系统(FIR滤波器)的输出与加性噪声信号之和,n.
Num = fir1(31,0.5);Fir = dsp。FIRFilter (“分子”, num);Iir = dsp。IIRFilter (“分子”sqrt (0.75),...“分母”-0.5 [1]);X = iir(sign(randn(2000,25)));N = 0.1*randn(size(x));D = fir(x) + n;
LMS滤波器
创建一个dsp。LMSFilter对象,以创建适合于输出所需信号的滤波器。将自适应滤波器的长度设置为32点,步长设置为0.008,用于分析和模拟的抽取因子设置为5。的变量simmse表示未知系统输出之间的模拟MSE,d,自适应滤波器的输出。的变量均方误差给出相应的预测值。
L = 32;Mu = 0.008;M = 5;LMS = dsp。LMSFilter (“长度”l,“StepSize”μ);[mmse,emse,meanW,mse,traceK] = msepred(lms,x,d,m);[simmse,meanWsim,Wsim,traceKsim] = msesim(lms,x,d,m);
绘制MSE结果
比较模拟均方误差、预测均方误差、最小均方误差和最终均方误差。最终的均方误差值由最小均方误差和超额均方误差之和给出。
Nn = m:m:size(x,1);simmse semilogy (nn,大小(x, 1) [0], [(emse + mmse)...(emse + mmse)], nn, mse,大小(x, 1) [0], [mmse mmse])标题(“均方误差性能”([0 size(x,1) 0.001 10])图例(“MSE (Sim)。”,“最后的MSE”,MSE的,“最小MSE。”)包含(“时间指数”) ylabel (“平方误差值”)
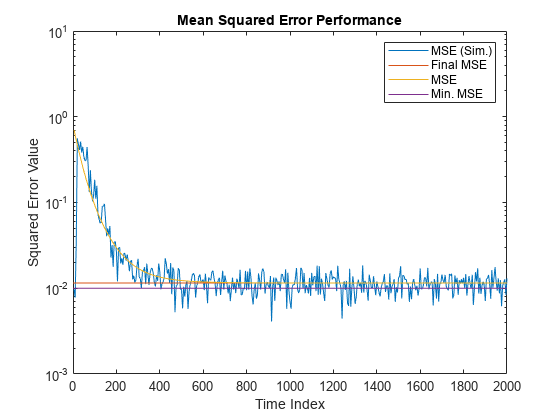
预测的均方误差与模拟的均方误差轨迹相同。这两个轨迹都收敛于稳态(最终)MSE。
画出系数轨迹
meanWsim模拟系数的平均值是由msesim.meanW预测系数的平均值是由msepred.
比较LMS滤波系数12、13、14和15的模拟平均值和预测平均值。
情节(nn meanWsim (: 12),“b”、神经网络、meanW (: 12),“r”神经网络,...meanWsim (:, 13:15),“b”、神经网络、meanW (:, 13:15),“r”)情节标题={“平均系数轨迹”;...'W(12), W(13), W(14), W(15)'}
PlotTitle =2 x1细胞{'} {'W(12), W(13), W(14),和W(15)'}的平均系数轨迹
标题(PlotTitle)传说(“模拟”,“理论”)包含(“时间指数”) ylabel (的系数值)

在稳态下,两个轨迹都收敛。
系数误差的平方和
比较系数误差的平方和msepred而且msesim.这些值由系数协方差矩阵的迹给出。
traceK traceKsim semilogy(神经网络,神经网络,“r”)标题(“系数误差平方和”轴([0 size(x,1) 0.0001 1])图例(“模拟”,“理论”)包含(“时间指数”) ylabel (“平方误差值”)

计算LMS自适应滤波器的最大步长
的maxstep函数计算自适应滤波器的最大步长。这个步长使滤波器在最大可能的收敛速度下保持稳定。创建主输入信号,x,通过向IIR滤波器传递有符号随机信号。信号x包含50帧,每帧2000个样本。创建一个LMS过滤器,点击32,步长0.1。
X = 0 (2000,50);IIRFilter = dsp。IIRFilter (“分子”sqrt (0.75),“分母”-0.5 [1]);为k = 1:尺寸(x, 2) x (:, k) = IIRFilter(标志(randn(大小(x, 1), 1)));结束Mu = 0.1;LMSFilter = dsp。LMSFilter (“长度”32岁的“StepSize”μ);
计算最大自适应步长和均方意义上的最大步长maxstep函数。
[mumax,mumaxmse] = maxstep(LMSFilter,x)
Mumax = 0.0625
Mumaxmse = 0.0536
基于LMS算法的FIR滤波器系统辨识
系统辨识是利用自适应滤波器辨识未知系统系数的过程。该过程的概览见<一个href="//www.tianjin-qmedu.com/help/dsp/ug/overview-of-adaptive-filters-and-applications.html" class="a">系统识别——使用自适应滤波器识别未知系统.所涉及的主要组成部分是:
自适应滤波算法。在本例中,设置
方法的属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="a">dsp。LMSFilter来“LMS”选择LMS自适应滤波算法。要适应的未知系统或过程。在本例中,由<一个href="//www.tianjin-qmedu.com/help/dsp/ref/fircband.html" class="a">
fircband是未知系统。适当的输入数据以执行适应过程。对于一般的LMS模型,这些是所需的信号 输入信号 .
自适应滤波器的目标是使自适应滤波器输出之间的误差信号最小化 和未知系统(或待识别系统)的输出 .一旦误差信号最小化,自适应滤波器就像未知系统。两个滤波器的系数非常匹配。
请注意:如果您使用的是R2016a或更早的版本,请用等效的步骤语法替换对对象的每次调用。例如,obj (x)就变成了步骤(obj, x).
未知的系统
创建一个dsp。FIRFilter对象,表示要标识的系统。使用fircband函数来设计滤波器系数。所设计的滤波器是一个低通滤波器,阻带纹波限制在0.2以内。
filt = dsp.FIRFilter;filt。Numerator = fircband(12,[0 0.4 0.5 1],[1 1 0 0],[1 0.2],...{' w '“c”});
传递信号x到FIR滤波器。所需信号d是未知系统(FIR滤波器)的输出和加性噪声信号的总和吗n.
X = 0.1*randn(250,1);N = 0.01*randn(250,1);D = filt(x) + n;
自适应滤波器
在未知滤波器设计和所需信号就位后,创建并应用自适应LMS滤波器对象来识别未知滤波器。
准备自适应滤波对象需要初始值估计滤波器系数和LMS步长(μ).你可以从一组非零值开始,作为滤波器系数的估计值。本例对13个初始过滤器权重使用0。设置InitialConditions的属性dsp。LMSFilter到所需的过滤器权重的初始值。对于步长而言,0.8是一个很好的折衷方案,它既足够大,可以在250次迭代(250个输入样本点)内很好地收敛,又足够小,可以对未知过滤器进行精确估计。
创建一个dsp。LMSFilter对象表示使用LMS自适应算法的自适应滤波器。将自适应滤波器的长度设置为13点,步长设置为0.8。
Mu = 0.8;LMS = dsp。LMSFilter (13,“StepSize”μ)
LMS = dsp。LMSFilterwith properties: Method: 'LMS' Length: 13 StepSizeSource: 'Property' StepSize: 0.8000 LeakageFactor: 1 InitialConditions: 0 AdaptInputPort: false WeightsResetInputPort: false WeightsOutput: 'Last' Show all properties
传递主输入信号x和期望的信号d到LMS过滤器。运行自适应过滤器来确定未知系统。输出y自适应滤波器的是收敛到所需信号的信号d从而使误差最小化e在两个信号之间。
画出结果。输出信号与预期的期望信号不匹配,使得两者之间的误差非平凡。
[y,e,w] = lms(x,d);情节(1:250,[d,y,e])“FIR滤波器的系统识别”)传说(“想要的”,“输出”,“错误”)包含(“时间指数”) ylabel (的信号值)

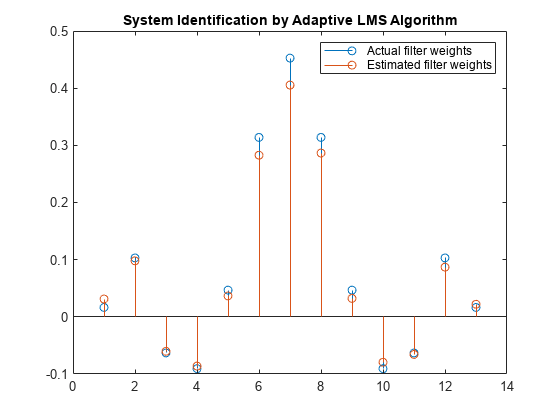
比较权重
权重向量w表示适应于类似未知系统的LMS滤波器(FIR滤波器)的系数。为了验证其收敛性,将FIR滤波器的分子与估计的自适应滤波器的权值进行比较。
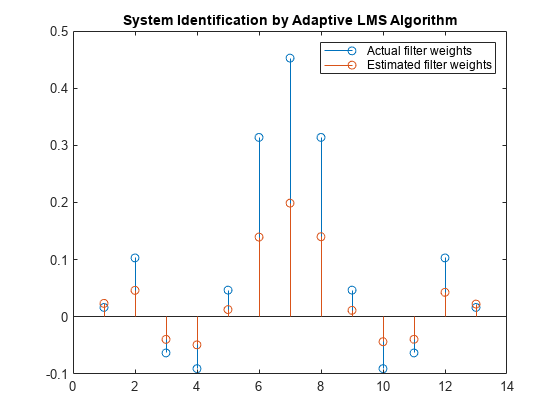
估计的滤波器权值与实际滤波器权值不太匹配,这证实了在前面的信号图中看到的结果。
茎([(filt.Numerator)。' w])标题(“自适应LMS算法识别系统”)传说(“实际过滤器重量”,“估计过滤器重量”,...“位置”,“东北”)
改变步长
作为实验,将步长更改为0.2。重复示例Mu = 0.2结果如下图所示。滤波器不收敛,估计的权重不是很好的近似于实际权重。
Mu = 0.2;LMS = dsp。LMSFilter (13,“StepSize”μ);[~,~,w] = lms(x,d);茎([(filt.Numerator)。' w])标题(“自适应LMS算法识别系统”)传说(“实际过滤器重量”,“估计过滤器重量”,...“位置”,“东北”)
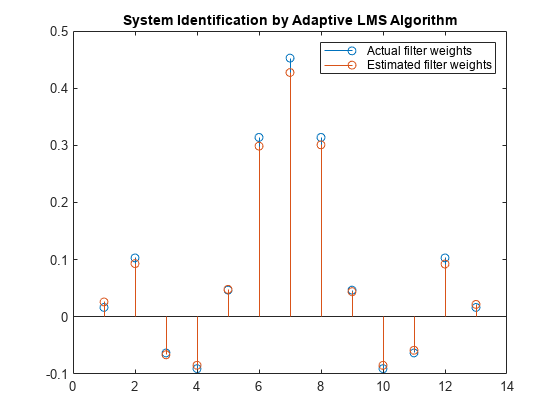
增加数据样本的数量
增加所需信号的帧大小。尽管这增加了计算量,LMS算法现在有更多的数据可以用于适应。在1000个信号数据样本,步长为0.2的情况下,系数比以前更接近,表明收敛性改善。
释放(filt);X = 0.1*randn(1000,1);N = 0.01*randn(1000,1);D = filt(x) + n;[y,e,w] = lms(x,d);茎([(filt.Numerator)。' w])标题(“自适应LMS算法识别系统”)传说(“实际过滤器重量”,“估计过滤器重量”,...“位置”,“东北”)
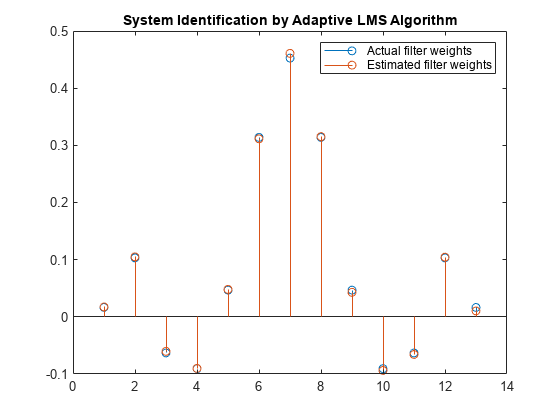
通过迭代输入数据,进一步增加数据样本的数量。在4000个样本数据上运行算法,在4次迭代中将1000个样本分批传递给LMS算法。
比较过滤器的权重。LMS滤波器的权值与FIR滤波器的权值非常接近,表明具有良好的收敛性。
释放(filt);N = 0.01*randn(1000,1);为Index = 1:4 x = 0.1*randn(1000,1);D = filt(x) + n;[y,e,w] = lms(x,d);结束茎([(filt.Numerator)。' w])标题(“自适应LMS算法识别系统”)传说(“实际过滤器重量”,“估计过滤器重量”,...“位置”,“东北”)
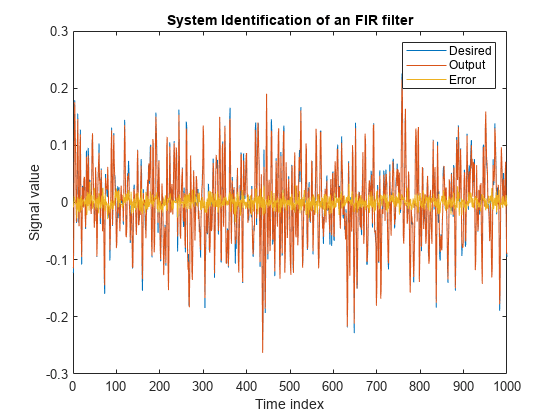
输出信号与期望信号非常接近,使得两者之间的误差接近于零。
情节(1:1000,[d,y,e])“FIR滤波器的系统识别”)传说(“想要的”,“输出”,“错误”)包含(“时间指数”) ylabel (的信号值)
基于归一化LMS算法的FIR滤波器系统辨识
为了提高LMS算法的收敛性能,归一化变体(NLMS)采用了基于信号功率的自适应步长。随着输入信号功率的变化,算法计算输入功率并调整步长以保持一个合适的值。步长随时间变化,因此在很多情况下,归一化算法在较少样本的情况下收敛速度更快。对于随时间变化缓慢的输入信号,归一化LMS算法是一种更有效的LMS方法。
有关使用LMS方法的示例,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ug/system-identification-fir-filter-using-lms-algorithm.html" class="a">基于LMS算法的FIR滤波器系统辨识.
请注意:如果您使用的是R2016a或更早的版本,请用等效的步骤语法替换对对象的每次调用。例如,obj (x)就变成了步骤(obj, x).
未知的系统
创建一个dsp。FIRFilter对象,表示要标识的系统。使用fircband函数来设计滤波器系数。所设计的滤波器是一个低通滤波器,阻带纹波限制在0.2以内。
filt = dsp.FIRFilter;filt。Numerator = fircband(12,[0 0.4 0.5 1],[1 1 0 0],[1 0.2],...{' w '“c”});
传递信号x到FIR滤波器。所需信号d是未知系统(FIR滤波器)的输出和加性噪声信号的总和吗n.
X = 0.1*randn(1000,1);N = 0.001*randn(1000,1);D = filt(x) + n;
自适应滤波器
若要使用归一化LMS算法变体,请设置方法上的物业dsp。LMSFilter来“归一化LMS”.将自适应滤波器的长度设置为13点,步长设置为0.2。
Mu = 0.2;LMS = dsp。LMSFilter (13,“StepSize”亩,“方法”,...“归一化LMS”);
传递主输入信号x和期望的信号d到LMS过滤器。
[y,e,w] = lms(x,d);
输出y自适应滤波器的是收敛到所需信号的信号d从而使误差最小化e在两个信号之间。
情节(1:1000,[d,y,e])“用归一化LMS算法进行系统辨识”)传说(“想要的”,“输出”,“错误”)包含(“时间指数”) ylabel (的信号值)

自适应滤波器与未知系统的比较
权重向量w表示LMS滤波器的系数,该滤波器适应于类似于未知系统(FIR滤波器)。为了验证其收敛性,将FIR滤波器的分子与估计的自适应滤波器的权值进行比较。
茎([(filt.Numerator)。' w])标题(“用归一化LMS算法进行系统辨识”)传说(“实际过滤器重量”,“估计过滤器重量”,...“位置”,“东北”)

比较LMS算法与归一化LMS算法的收敛性能
自适应滤波器使它的滤波器系数与未知系统的系数相匹配。目标是使未知系统输出和自适应滤波器输出之间的误差信号最小化。当这两个输出收敛并对相同的输入密切匹配时,系数称为密切匹配。这种状态下的自适应滤波器类似于未知系统。这个例子比较了归一化LMS (NLMS)算法和未归一化LMS算法的收敛速度。
未知的系统
创建一个dsp。FIRFilter它表示未知系统。传递信号x作为未知系统的输入。所需信号d是未知系统(FIR滤波器)的输出和加性噪声信号的总和吗n.
filt = dsp.FIRFilter;filt。Numerator = fircband(12,[0 0.4 0.5 1],[1 1 0 0],[1 0.2],...{' w '“c”});X = 0.1*randn(1000,1);N = 0.001*randn(1000,1);D = filt(x) + n;
自适应滤波器
创建两个dsp。LMSFilter对象,其中一组为LMS算法,另一组为规范化LMS算法。选择自适应步长0.2,并将自适应滤波器的长度设置为13点。
Mu = 0.2;Lms_nonnormalized = dsp。LMSFilter (13,“StepSize”亩,...“方法”,“LMS”);Lms_normalized = dsp。LMSFilter (13,“StepSize”亩,...“方法”,“归一化LMS”);
传递主输入信号x和期望的信号dLMS算法的两个变体。的变量e1而且e2分别表示期望信号与归一化和非归一化滤波器输出之间的误差。
[~,e1,~] = lms_normalized(x,d);[~,e2,~] = lms_nonnormalized(x,d);
画出这两个变化的错误信号。NLMS变体的误差信号收敛到零的速度比LMS变体的误差信号快得多。规范化版本只需要很少的迭代就可以得到几乎和非规范化版本一样好的结果。
情节((e1, e2));标题(“比较LMS和NLMS转换性能”);传奇(“NLMS派生的过滤器权重”,...“LMS衍生滤波器权重”,“位置”,“东北”);包含(“时间指数”) ylabel (的信号值)

使用LMS滤波器消除噪声
取消使用LMS自适应滤波器添加到未知系统的加性噪声n。LMS滤波器调整它的系数,直到它的传递函数与未知系统的传递函数尽可能接近。自适应滤波器的输出和未知系统的输出之间的差值代表误差信号,e.使这个误差信号最小化是自适应滤波器的目标。
未知系统和LMS滤波器处理相同的输入信号,x,并产生输出d而且y,分别。如果自适应滤波器的系数与未知系统的系数匹配,则误差,e,实际上代表加性噪声。
请注意:如果您使用的是R2016a或更早的版本,请用等效的步骤语法替换对对象的每次调用。例如,obj (x)就变成了步骤(obj, x).
初始化
创建一个dsp。FIRFilter系统对象来表示未知系统。创建一个dsp。LMSFilter对象并将长度设置为11点,步长设置为0.05。创建一个正弦波来表示添加到未知系统中的噪声。查看时间范围内的信号。
FrameSize = 100;NIter = 10;Lmsfilt2 = dsp。LMSFilter (“长度”11“方法”,“归一化LMS”,...“StepSize”, 0.05);Firfilt2 = dsp。FIRFilter (“分子”fir1(10(。5、综合成绩));正弦波= dsp。SineWave (“频率”, 0.01,...“SampleRate”, 1“SamplesPerFrame”, FrameSize);TS = dsp。TimeScope(“时间间隔”, FrameSize *硝石,“TimeUnits”,“秒”,...“YLimits”3 [3],“BufferLength”2 * FrameSize *硝石,...“ShowLegend”,真的,“ChannelNames”,...{噪声信号的,误差信号的});
创建一个随机输入信号,x并将信号传递给FIR滤波器。在FIR滤波器的输出端加一个正弦波产生噪声信号,d.的信号,d是未知系统的输出。将噪声信号和主输入信号传递给LMS滤波器。查看时间范围内的噪声信号和错误信号。
为k = 1:NIter x = randn(FrameSize,1);D = firfilt2(x) +正弦波();[y,e,w] = lmsfilt2(x,d);TS ((d, e))结束发行版(TS)

错误信号,e,为添加到未知系统的正弦噪声。最小化误差信号将使添加到系统中的噪声最小化。
基于符号数据LMS算法的噪声消除
当推导自适应滤波器所需的计算量驱动开发过程时,LMS (SDLMS)算法的符号数据变体可能是一个非常好的选择,如本例所示。
在LMS自适应滤波器的标准和归一化变化中,自适应滤波器的系数来自于期望信号与未知系统输出信号之间的均方误差。符号数据算法通过使用输入数据的符号来改变滤波系数,从而改变均方误差计算。
当误差为正时,新的系数是先前的系数加上误差乘以步长µ.如果误差是负的,则新的系数还是以前的系数减去误差乘以µ-注意符号的变化。
当输入为零时,新的系数与前一组相同。
向量形式的符号数据LMS算法为:
在哪里
与向量 包含应用于滤波系数和向量的权重 包含输入数据。向量 是期望信号与滤波信号之间的误差。SDLMS算法的目标是最小化这种错误。步长表示为 .
用一个更小的 ,每个样本对滤波器权值的修正变小,SDLMS误差下降更慢。一个更大的 每一步改变更多的权值,因此误差下降得更快,但产生的误差不能尽可能接近理想解。为了保证良好的收敛速度和稳定性,请选择 在以下实际范围内。
在哪里 是信号中的样本数。此外,定义 作为2的幂来进行高效计算。
注意:如何设置符号数据算法的初始条件将深刻影响自适应过程的有效性。由于该算法本质上是对输入信号进行量化,因此算法很容易变得不稳定。
一系列大的输入值,加上量化过程可能导致误差增长超出所有边界。通过选择小步长来抑制符号数据算法失控的趋势 并将算法的初始条件设为非零正负值。
在此噪声消除示例中,设置方法的属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="a">dsp。LMSFilter来“Sign-Data LMS”.这个例子需要两个输入数据集:
包含被噪声损坏的信号的数据。在下面的框图中<一个href="//www.tianjin-qmedu.com/help/dsp/ug/overview-of-adaptive-filters-and-applications.html" class="a">噪声或干扰消除——使用自适应滤波器从未知系统中去除噪声,这就是所需要的信号 .噪声消除过程去除信号中的噪声。
包含随机噪声的数据。在下面的框图中<一个href="//www.tianjin-qmedu.com/help/dsp/ug/overview-of-adaptive-filters-and-applications.html" class="a">噪声或干扰消除——使用自适应滤波器从未知系统中去除噪声,这是 .信号 与破坏信号数据的噪声有关。如果没有噪声数据之间的相关性,自适应算法无法从信号中去除噪声。
对于信号,使用正弦波。请注意,信号是包含1000个元素的列向量。
信号= sin(2*pi*0.055*(0:1000-1)');
现在,加上相关的白噪声信号.为了确保噪声是相关的,将噪声通过低通FIR滤波器,然后将滤波后的噪声添加到信号中。
噪声= randn(1000,1);filt = dsp.FIRFilter;filt。Numerator = fir1(11,0.4); fnoise = filt(noise); d = signal + fnoise;
fnoise是相关的噪声和d现在是符号数据算法所需的输入。
准备dsp。LMSFilter对象进行处理,设置过滤器权重和的初始条件μ(StepSize).如本节前面所述,您设置的值多项式系数而且μ确定自适应滤波器能否去除信号路径中的噪声。
在<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">基于LMS算法的FIR滤波器系统辨识,您构造了一个默认过滤器,将过滤器系数设置为零。在大多数情况下,这种方法不适用于符号数据算法。你设置的初始滤波系数越接近期望值,算法就越有可能保持良好的表现,并收敛到有效去除噪声的滤波解决方案。
对于这个例子,从噪声滤波器(filt。Numerator),并稍微修改它们,以便算法能够适应。
coeffs = (filter . numerator).'-0.01;设置筛选器初始条件。Mu = 0.05;设置算法更新的步长。
所需的输入参数dsp。LMSFilter准备,构造LMS筛选对象,运行适配,并查看结果。
LMS = dsp。LMSFilter (12,“方法”,“Sign-Data LMS”,...“StepSize”亩,“InitialConditions”、多项式系数);[~,e] = lms(噪声,d);L = 200;情节(0:L - 1、信号(1:L), 0: L - 1, e (1: L));标题(“用符号数据算法消除噪音”);传奇(“实际信号”,“消除噪音的结果”,...“位置”,“东北”);包含(“时间指数”) ylabel (的信号值)

当dsp。LMSFilter运行时,它使用的乘法运算比任何一种标准LMS算法都要少得多。此外,当步长为2的幂时,执行符号数据自适应只需要乘以位移位。
尽管如图所示的符号数据算法的性能相当好,但符号数据算法比标准LMS变体的稳定性差得多。在这个噪声消除例子中,处理后的信号与输入信号匹配得非常好,但算法很容易无限制增长,而不能达到良好的性能。
改变权值初始条件(InitialConditions),μ(StepSize),甚至是你用来创建相关噪声的低通滤波器,都可能导致噪声消除失败。
用符号误差LMS算法消除噪声
在LMS自适应滤波器的标准和归一化变化中,自适应滤波器的系数来自于计算期望信号与未知系统输出信号之间的均方误差,并将结果应用于当前滤波器系数。符号误差LMS (SELMS)算法利用误差的符号来修改滤波系数,取代了均方误差的计算。
当误差为正时,新的系数是先前的系数加上误差乘以步长 .如果误差为负,则新的系数是先前的系数减去误差乘以 -注意符号的变化。当输入为零时,新的系数与前一组相同。
向量形式的符号误差LMS算法为:
,
在哪里
与向量 包含应用于滤波系数和向量的权重 包含输入数据。向量 是期望信号与滤波信号之间的误差。SELMS算法的目标是最小化这种误差。
用一个更小的 ,每个样本对滤波器权值的修正变小,SELMS误差下降更慢。一个更大的 每一步改变更多的权重,这样误差下降得更快,但结果的误差不能接近理想解。为了保证良好的收敛速度和稳定性,请选择 在以下实际范围内。
在哪里 是信号中的样本数。此外,定义 作为2的幂,便于高效计算。
注意:如何设置符号误差算法的初始条件深刻影响自适应过程的有效性。由于算法本质上是对误差信号的量化,因此算法很容易变得不稳定。
一系列的大误差值,加上量化过程可能导致误差增长超出所有边界。通过选择较小的步长来抑制符号误差算法变得不稳定的趋势 并将算法的初始条件设为非零正负值。
在此噪声消除示例中,设置方法的属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="a">dsp。LMSFilter来“符号误差LMS”.这个例子需要两个输入数据集:
包含被噪声损坏的信号的数据。在下面的框图中<一个href="//www.tianjin-qmedu.com/help/dsp/ug/overview-of-adaptive-filters-and-applications.html" class="a">噪声或干扰消除——使用自适应滤波器从未知系统中去除噪声,这就是所需要的信号 .噪声消除过程去除信号中的噪声。
包含随机噪声的数据。在下面的框图中<一个href="//www.tianjin-qmedu.com/help/dsp/ug/overview-of-adaptive-filters-and-applications.html" class="a">噪声或干扰消除——使用自适应滤波器从未知系统中去除噪声,这是 .信号 与破坏信号数据的噪声有关。如果没有噪声数据之间的相关性,自适应算法无法从信号中去除噪声。
对于信号,使用正弦波。请注意,信号是包含1000个元素的列向量。
信号= sin(2*pi*0.055*(0:1000-1)');
现在,加上相关的白噪声信号.为了确保噪声是相关的,将噪声通过低通FIR滤波器,然后将滤波后的噪声添加到信号中。
噪声= randn(1000,1);filt = dsp.FIRFilter;filt。Numerator = fir1(11,0.4); fnoise = filt(noise); d = signal + fnoise;
fnoise是相关的噪声和d现在是符号误差算法的期望输入。
准备dsp。LMSFilter对象进行处理时,设置过滤器权重的初始条件(InitialConditions),μ(StepSize).如本节前面所述,您设置的值多项式系数而且μ确定自适应滤波器能否去除信号路径中的噪声。
在<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">基于LMS算法的FIR滤波器系统辨识,您构造了一个默认过滤器,将过滤器系数设置为零。在大多数情况下,这种方法不适用于符号误差算法。你设置的初始滤波系数越接近期望值,算法就越有可能保持良好的表现,并收敛到有效去除噪声的滤波解决方案。
对于这个例子,从噪声滤波器(filt。Numerator),并对它们稍加修改,以便算法能够适应。
coeffs = (filter . numerator).'-0.01;设置筛选器初始条件。Mu = 0.05;设置算法更新的步长。
所需的输入参数dsp。LMSFilter准备好后,运行适配并查看结果。
LMS = dsp。LMSFilter (12,“方法”,“符号误差LMS”,...“StepSize”亩,“InitialConditions”、多项式系数);[~,e] = lms(噪声,d);L = 200;情节(0:199、信号(1:200)0:199 e (1:200));标题(符号误差LMS算法的噪声消除性能);传奇(“实际信号”,“降噪后的误差”,...“位置”,“东北”)包含(“时间指数”) ylabel (的信号值)

当符号错误LMS算法运行时,它使用的乘法运算比任何一种标准LMS算法都要少得多。此外,当步长为2的幂时,执行符号错误自适应只需要位移动的倍数。
尽管如图所示的符号错误算法的性能相当好,但符号错误算法比标准LMS变体的稳定性差得多。在这个噪声消除的例子中,自适应信号与输入信号非常匹配,但算法很容易变得不稳定,而不能达到良好的性能。
改变权值初始条件(InitialConditions),μ(StepSize),甚至是你用来创建相关噪声的低通滤波器,都可能导致噪声消除失败,算法变得无用。
用Sign-Sign LMS算法消除噪声
符号-符号LMS算法(SSLMS)通过使用输入数据的符号来改变滤波系数,取代了均方误差计算。当误差为正时,新的系数是先前的系数加上误差乘以步长 .如果误差为负,则新的系数是先前的系数减去误差乘以 -注意符号的变化。当输入为零时,新的系数与前一组相同。
本质上,该算法通过对误差和输入应用符号运算符来量化它们。
在向量形式下,符号-符号LMS算法为:
在哪里
向量 包含应用于过滤器系数和向量的权重 包含输入数据。向量 是期望信号与滤波信号之间的误差。SSLMS算法的目标是最小化这种错误。
用一个更小的 ,对于每个样本,对过滤器权值的修正变小,SSLMS错误下降得更慢。一个更大的 每一步改变更多的权值,因此误差下降得更快,但产生的误差不能尽可能接近理想解。为了保证良好的收敛速度和稳定性,请选择 在以下实际范围内。
在哪里 是信号中的样本数。此外,定义 作为2的幂,便于高效计算
注意:
如何设置符号-符号算法的初始条件深刻影响自适应过程的有效性。由于该算法本质上是对输入信号和误差信号的量化,因此算法很容易变得不稳定。
一系列的大误差值,加上量化过程可能导致误差增长超出所有边界。通过选择较小的步长来抑制符号-符号算法变得不稳定的趋势 并将算法的初始条件设为非零正负值。
在此噪声消除示例中,设置方法的属性<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="a">dsp。LMSFilter来“Sign-Sign LMS”.这个例子需要两个输入数据集:
包含被噪声损坏的信号的数据。在下面的框图中<一个href="//www.tianjin-qmedu.com/help/dsp/ug/overview-of-adaptive-filters-and-applications.html" class="a">噪声或干扰消除——使用自适应滤波器从未知系统中去除噪声,这就是所需要的信号 .噪声消除过程去除信号中的噪声。
包含随机噪声的数据。在下面的框图中<一个href="//www.tianjin-qmedu.com/help/dsp/ug/overview-of-adaptive-filters-and-applications.html" class="a">噪声或干扰消除——使用自适应滤波器从未知系统中去除噪声,这是 .信号 与破坏信号数据的噪声有关。如果没有噪声数据之间的相关性,自适应算法无法从信号中去除噪声。
对于信号,使用正弦波。请注意,信号是包含1000个元素的列向量。
信号= sin(2*pi*0.055*(0:1000-1)');
现在,加上相关的白噪声信号.为了确保噪声是相关的,将噪声通过低通FIR滤波器,然后将滤波后的噪声添加到信号中。
噪声= randn(1000,1);filt = dsp.FIRFilter;filt。Numerator = fir1(11,0.4); fnoise = filt(noise); d = signal + fnoise;
fnoise是相关的噪声和d现在是符号-符号算法的期望输入。
准备dsp。LMSFilter对象进行处理时,设置过滤器权重的初始条件(InitialConditions),μ(StepSize).如本节前面所述,您设置的值多项式系数而且μ确定自适应滤波器能否去除信号路径中的噪声。在<一个href="//www.tianjin-qmedu.com/help/dsp/ref/dsp.lmsfilter-system-object.html" class="intrnllnk">基于LMS算法的FIR滤波器系统辨识,您构造了一个默认过滤器,将过滤器系数设置为零。通常这种方法不适用于符号-符号算法。
你设置的初始滤波系数越接近期望值,算法就越有可能保持良好的表现,并收敛到有效去除噪声的滤波解决方案。对于本例,您从噪声滤波器(filt。Numerator),并稍微修改它们,以便算法能够适应。
coeffs = (filter . numerator)。“-0.01;设置筛选器初始条件。Mu = 0.05;
所需的输入参数dsp。LMSFilter准备好后,运行适配并查看结果。
LMS = dsp。LMSFilter (12,“方法”,“Sign-Sign LMS”,...“StepSize”亩,“InitialConditions”、多项式系数);[~,e] = lms(噪声,d);L = 200;情节(0:199、信号(1:200)0:199 e (1:200));标题(“符号-符号LMS算法的噪声消除性能”);传奇(“实际信号”,“降噪后的误差”,...“位置”,“东北”)包含(“时间指数”) ylabel (的信号值)

当dsp。LMSFilter运行时,它使用的乘法运算比任何一种标准LMS算法都要少得多。此外,当步长为2的幂时,执行符号-符号自适应只需要位移动的倍数。
尽管图中所示的符号-符号算法的性能相当好,但符号-符号算法比标准LMS变体的稳定性差得多。在这个噪声消除的例子中,自适应信号与输入信号非常匹配,但算法很容易变得不稳定,而不能达到良好的性能。
改变权值初始条件(InitialConditions和mu (StepSize),甚至是你用来创建相关噪声的低通滤波器,都可能导致噪声消除失败,算法变得无用。
访问LMS过滤器权重的完整历史
请注意:此示例仅在R2017a或更高版本中运行。如果您使用的是R2017a之前的版本,该对象不会输出一个完整的逐样本过滤器权重历史。如果您使用的是R2016b之前的版本,请将对函数的每次调用替换为等效函数一步语法。例如,myObject (x)就变成了步骤(myObject x).
初始化dsp。LMSFilter对象,并设置WeightsOutput财产“所有”.此设置使LMS过滤器能够输出一个具有维度的权重矩阵(FrameLength长度),对应于所有权重的完整样本历史FrameLength输入值的示例。
FrameSize = 15000;Lmsfilt3 = dsp。LMSFilter (“长度”, 63,“方法”,“LMS”,...“StepSize”, 0.001,“LeakageFactor”, 0.99999,...“WeightsOutput”,“所有”);%满权重历史记录W_actual = fir1(64,[0.5 0.75]);Firfilt3 = dsp。FIRFilter (“分子”, w_actual);正弦波= dsp。SineWave (“频率”, 0.01,...“SampleRate”, 1“SamplesPerFrame”, FrameSize);TS = dsp。TimeScope(“时间间隔”FrameSize,“TimeUnits”,“秒”,...“YLimits”(-0.25 - 0.75),“BufferLength”2 * FrameSize...“ShowLegend”,真的,“ChannelNames”,...{“Coeff 33估计”,“Coeff 34估计”,“Coeff 35估计”,...“Coeff 33 Actual”,“Coeff 34 Actual”,“Coeff 35 Actual”});
运行一帧,输出完整的自适应权重历史,w.
x = randn(FrameSize,1);输入信号%D = firfilt3(x) +正弦波();%噪声+信号[~,~,w] = lmsfilt3(x,d);
每一行w是为各自输入样本估计的一组权重。的每一栏w给出特定权重的完整历史。绘制出第33次,第34次和第35次的实际重量和整个历史。在图中,您可以看到,随着自适应滤波器接收输入样本并继续适应,估计的权值输出最终与实际权值收敛。
idxBeg = 33;idxEnd = 35;TS ([w (:, idxBeg: idxEnd) repmat (w_actual (idxBeg: idxEnd) FrameSize, 1)))

算法
LMS滤波算法由以下公式定义。
此System对象中可用的各种LMS自适应滤波算法定义为:
LMS—求解Weiner-Hopf方程,并为自适应滤波器找到滤波器系数。
归一化LMS——LMS算法的归一化变异。
在归一化LMS中,为了克服权重更新中潜在的数值不稳定性,在分母中添加了一个小的正常数ε。对于双精度浮点输入,ε为2.2204460492503131e-016。对于单精度浮点输入,ε为1.192092896e-07。对于定点输入,ε为0。
符号数据LMS——每次迭代时对过滤器权重的修正取决于输入的符号u(n)。
在哪里u(n)是实数。
符号-错误LMS——应用于当前过滤器权重的修正,每次连续迭代都取决于错误的符号,e(n)。
符号-符号LMS——应用于当前过滤器权重的修正,每次连续迭代都依赖于的符号u的符号e(n)。
在哪里u(n)是实数。
变量如下:
| 变量 | 描述 |
|---|---|
n |
当前时间索引 |
u(n) |
步进缓冲输入样本的向量n |
u *(n) |
缓冲输入样本的矢量在阶跃处的共轭复数n |
w(n) |
滤波权向量在阶跃下估计n |
y (n) |
步进过滤后的输出n |
e (n) |
阶跃估计误差n |
d (n) |
阶跃时的期望响应n |
µ |
自适应步长 |
α |
泄漏系数(0 < α≤1) |
ε |
一个常数,用于纠正在更新权值期间发生的任何潜在的数值不稳定性。 |
参考文献
海斯,M.H.统计数字信号处理与建模。纽约:John Wiley & Sons出版社,1996年。
扩展功能
C/ c++代码生成
使用MATLAB®Coder™生成C和c++代码。
使用注意事项和限制:
看到<一个href="//www.tianjin-qmedu.com/help/coder/ug/use-system-objects-in-matlab-code-generation.html" class="a">MATLAB代码生成中的系统对象(MATLAB编码器)。
定点转换
使用定点设计器设计和模拟定点系统。
控件中使用的数据类型dsp。LMSFilter对象用于定点信号。下表总结了图表中使用的变量的定义:
| 变量 | 定义 |
|---|---|
u |
输入向量 |
W |
滤波器权重向量 |
µ |
步长 |
e |
错误 |
问 |
商, |
产品u'u |
能量计算图中的产品数据类型 |
蓄电池u'u |
能量计算图中的蓄能器数据类型 |
产品W'u |
卷积图中的产品数据类型 |
蓄电池W'u |
卷积图中的累加器数据类型 |
产品 |
步长和误差图Product中的产品数据类型 |
产品 |
权重更新图中的产品和累加器数据类型。1 |
1此数量的累加器数据类型将自动设置为与产品数据类型相同。此累加器的最小值、最大值和溢出信息被记录为产品信息的一部分。自动伸缩将此乘积和累加器视为一种数据类型。


可以在System对象属性中设置属性、权重、积、商和累加器的数据类型。s manbetx 845定点输入、输出和系统对象属性必须具有以下特征:
输入信号和期望信号必须有相同的字长,但它们的分数长度可以不同。
步长和泄漏因子必须具有相同的字长,但它们的分数长度可以不同。
输出信号和误差信号具有与所需信号相同的字长度和相同的分数长度。
的商和乘积输出u'u,W'u, , 操作必须具有相同的字长,但是它们的分数长度可以不同。
的累加器数据类型u'u而且W'u操作必须具有相同的字长,但是它们的分数长度可以不同。
如果乘数的至少一个输入是实数,则乘数的输出在乘积输出数据类型中。如果乘数的两个输入都是复数,则乘法的结果在累加器数据类型中。有关所执行的复杂乘法的详细信息,请参见<一个href="//www.tianjin-qmedu.com/help/dsp/ug/arithmetic-operations.html" class="a">乘法数据类型.
另请参阅
功能
对象
dsp。AdaptiveLatticeFilter|dsp。AffineProjectionFilter|dsp。BlockLMSFilter|dsp。FIRFilter|dsp。FastTransversalFilter|dsp。FilteredXLMSFilter|dsp。FrequencyDomainAdaptiveFilter|dsp。KalmanFilter|dsp。RLSFilter
块
在R2012a中介绍
您也可以从以下列表中选择网站: