使用LMS算法对FIR滤波器的系统识别
系统识别是使用自适应滤波器识别未知系统的系数的过程。该过程的一般概述显示在系统识别 - 使用自适应滤波器识别未知系统。所涉及的主要组件是:
自适应滤波算法。在此示例中,设置
方法财产dsp.lmsfilter.至'lms'选择LMS自适应滤波器算法。适应的未知系统或过程。在此示例中,由此设计的过滤器
fircband.是未知的系统。适当的输入数据以锻炼适应过程。对于通用LMS模型,这些是所需的信号 和输入信号 。
自适应滤波器的目的是最小化自适应滤波器的输出之间的误差信号 以及未知系统的输出(或要识别的系统) 。一旦误差信号最小化,所适应的过滤器就像未知系统。两个滤波器的系数密切匹配。
笔记:如果您使用的是R2016A或早期版本,请使用等效步骤语法替换对对象的每个调用。例如,obj(x)成为步骤(obj,x)。
未知的系统
创建一个dsp.firfilter.表示要识别的系统的对象。使用fircband.功能设计滤波器系数。设计的滤波器是一个低通滤波器,在阻带中受到0.2纹波。
filt = dsp.firfilter;filt.numerator = FiRCBAND(12,[0 0.4 0.5 1],[1 1 0 0],[1 0.2],......{'W''C'});
传递信号X到冷杉过滤器。期望的信号D.是未知系统(FIR滤波器)的输出和添加噪声信号的总和N。
x = 0.1 * randn(250,1);n = 0.01 * randn(250,1);d = filt(x)+ n;
自适应过滤器
使用未知过滤器设计和所需的信号,创建并应用自适应LMS滤波器对象以识别未知过滤器。
准备自适应滤波器对象需要启动滤波器系数和LMS步长的估计值(亩)。您可以从某些非零值开始作为滤波器系数的估计值。此示例使用Zeros为13初始滤波器权重。设定初始条件财产dsp.lmsfilter.到滤波器权重的所需初始值。对于阶梯尺寸,0.8是在足够大之间的良好折衷以在250次迭代(250输入采样点)内井收敛,并且足够小以创建对未知过滤器的准确估计。
创建一个dsp.lmsfilter.对象表示使用LMS自适应算法的自适应滤波器。将自适应滤波器的长度设置为13个抽头,步长到0.8。
mu = 0.8;lms = dsp.lmsfilter(13,'一步的大小',亩)
LMS = DSP.LMSFilter具有属性:方法:“LMS”长度:13步骤源:'属性'步骤:0.8000 LirectoreFactor:1 industConitions:0 AdaptInputport:False权重键:false权力汇位:'last'显示所有属性
传递主输入信号X和所需的信号D.到LMS过滤器。运行自适应滤波器以确定未知系统。输出y自适应滤波器的信号是融合到所需信号的信号D.从而最小化错误E.在两个信号之间。
绘制结果。输出信号与预期的预期不匹配所需信号,使两个非活动之间的误差。
[y,e,w] = lms(x,d);图(1:250,[D,Y,E])标题('系统识别冷杉过滤器') 传奇('想要'那'输出'那'错误')xlabel('时间指数')ylabel('信号值')

比较重量
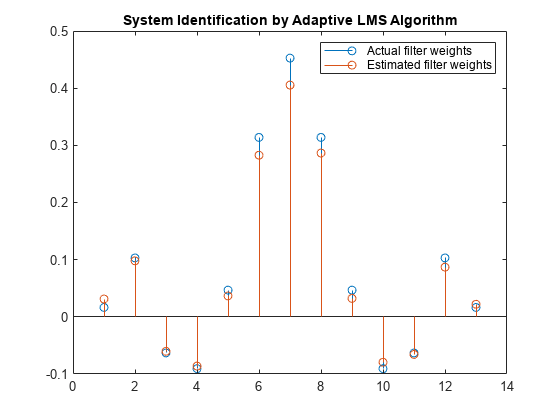
重量矢量W.表示适于类似于未知系统(FIR滤波器)的LMS滤波器的系数。要确认收敛,比较FIR滤波器的分子和自适应滤波器的估计权重。
估计的滤波器权重不与实际的滤波器权重不密切匹配,确认先前信号图中看到的结果。
茎([(filt.numerator)。'w])标题(“自适应LMS算法的系统识别”) 传奇('实际滤重权重'那'估计过滤重量'那......'地点'那'东北')
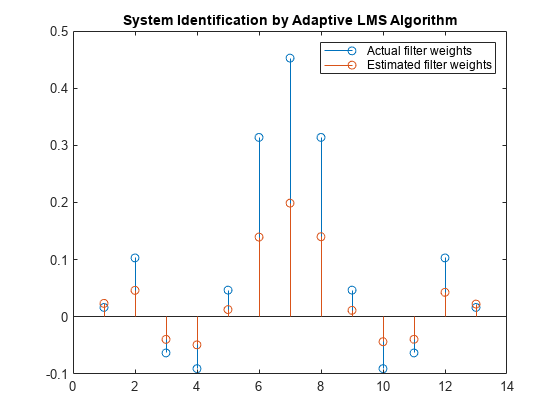
改变阶梯尺寸
作为实验,将步长改变为0.2。重复一个例子mu = 0.2导致以下干图。过滤器不收敛,估计的权重不是实际权重的良好近似。
mu = 0.2;lms = dsp.lmsfilter(13,'一步的大小',亩);[〜,〜,w] = lms(x,d);茎([(filt.numerator)。'w])标题(“自适应LMS算法的系统识别”) 传奇('实际滤重权重'那'估计过滤重量'那......'地点'那'东北')
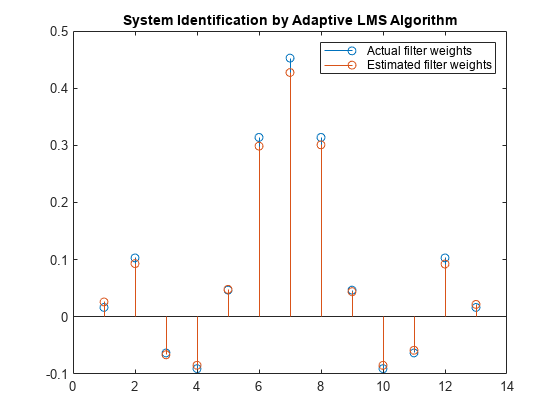
增加数据样本的数量
增加所需信号的帧大小。即使这增加了所涉及的计算,LMS算法现在也有更多的数据可用于适应。利用1000个信号数据和台阶尺寸为0.2,系数比以前更近,表示改善的收敛性。
释放(FILT);x = 0.1 * RANDN(1000,1);n = 0.01 * randn(1000,1);d = filt(x)+ n;[y,e,w] = lms(x,d);茎([(filt.numerator)。'w])标题(“自适应LMS算法的系统识别”) 传奇('实际滤重权重'那'估计过滤重量'那......'地点'那'东北')
通过迭代输入数据,进一步增加数据样本的数量。在4000个数据样本上运行算法,通过4次迭代的批量传递给LMS算法。
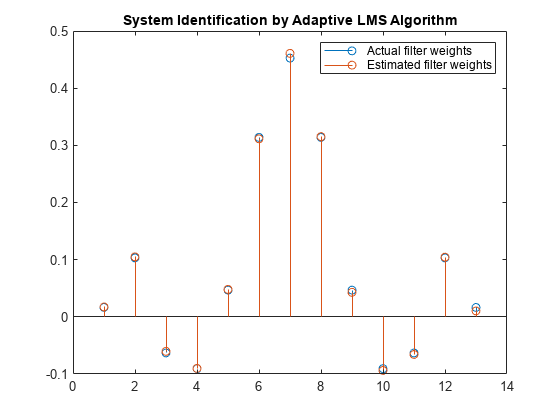
比较滤波器权重。LMS滤波器的重量非常紧密地匹配FIR滤波器的重量,表示良好的收敛性。
释放(FILT);n = 0.01 * randn(1000,1);为了索引= 1:4 x = 0.1 * Randn(1000,1);d = filt(x)+ n;[y,e,w] = lms(x,d);结尾茎([(filt.numerator)。'w])标题(“自适应LMS算法的系统识别”) 传奇('实际滤重权重'那'估计过滤重量'那......'地点'那'东北')
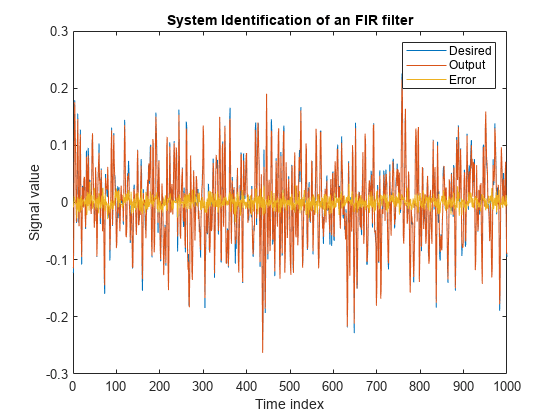
输出信号非常紧密地匹配所需的信号,使两个接近零之间的误差。
图(1:1000,[D,Y,E])标题('系统识别冷杉过滤器') 传奇('想要'那'输出'那'错误')xlabel('时间指数')ylabel('信号值')
也可以看看
对象
相关话题
参考
[1] Hayes,Monson H.,统计数字信号处理和建模。Hoboken,NJ:John Wiley&Sons,1996,PP.493-552。
[2] Haykin,Simon,自适应滤波理论。上部马鞍河,NJ:Prentice-Hall,Inc。,1996年。
您还可以从以下列表中选择一个网站: