时间序列回归I:线性模型
这个例子介绍了多元线性回归模型背后的基本假设。它是时间序列回归的一系列例子中的第一个,为以后所有的例子提供了基础。
多元线性模型
时间序列过程通常用多元线性回归(MLR)模型的形式:
在哪里 是观察到的反应和 包括可观察预测器的同期值的列。的偏回归系数 代表个体预测因子对变量的边际贡献 当所有其他预测器都保持不变时。
这个词 的预测值和观测值之间的差异是否具有全面性 .这些差异是由于流程波动(在 )、测量误差(变更 ),以及模型错误说明(例如,忽略了预测值或模型之间的非线性关系) 和 ).它们也来自于基础数据生成过程(DGP)的内在随机性,这也是模型试图表示的。人们通常认为 是由一个不可观察的东西产生的吗创新的过程与静止的协方差
对于任意长度的时间间隔 .在进一步的基本假设下 , ,以及它们之间的关系,对 由普通最小二乘(OLS)得到。
与其他社会科学一样,经济数据通常是通过被动观察收集的,而不是借助控制实验。理论上相关的预测可能需要被实际可用的替代指标所取代。反过来,经济观察可能具有有限的频率、低变异性和很强的相互依赖性。
这些数据的缺陷导致了OLS估计的可靠性和用于模型说明的标准统计技术方面的一些问题。系数估计可能对数据测量误差敏感,使显著性检验不可靠。多个预测因子的同时变化可能会产生相互作用,而这种相互作用很难区分为单独的影响。观察到的反应变化可能与预测因子的变化相关,但不是由预测因子的变化引起的。
在可用数据的上下文中评估模型假设是规范分析的目标。当一个模型的可靠性变得可疑时,实际的解决方案可能是有限的,但是彻底的分析可以帮助确定任何问题的来源和程度。万博 尤文图斯
这是讨论指定和诊断MLR模型的基本技术的一系列示例中的第一个。该系列还提供了一些通用策略,以解决在处理经济时间序列数据时出现的具体问题。
经典假设
经典线性模型(CLM)假设允许OLS产生估计 具有理想的性能[3]。基本假设是MLR模型和所选预测值正确指定了基础DGP中的线性关系。其他CLM假设包括:
为全秩(各预测因子之间无共线性)。
是不相关的 对所有 (预测因素的严格外生性)。
是不自相关的( 是对角)。
同方差(对角线项在 都是 ).
假设 是估计误差。这个偏见估计量的最大值是 和均方误差(MSE) 。均方误差是估计方差和偏差平方的总和,因此它简洁地总结了估计误差的两个重要来源。关于模型残差,不应将其与回归均方误差混淆,因为模型残差依赖于样本。
所有的估计器在最小化均方误差的能力上都是有限的,均方误差永远不能小于最小均方误差Cramér-Rao下界[1].这个界是通过极大似然估计(MLE)渐近地实现的(即随着样本容量的增大)。然而,在有限样本中,特别是在经济学中遇到的相对较小的样本中,其他估计量可能在相对效率也就是说,就实现的MSE而言。
在CLM假设下,高斯-马尔可夫定理表示OLS估计量 是蓝色的:
Best(最小方差)
l线性(数据的线性函数)
U偏见的( )
E系数的刺激子 .
BEST加起来等于线性估计中最小的MSE。线性是重要的,因为线性向量空间的理论可以应用于估计量的分析(见,例如[5]).
如果创新 都是正态分布的,, 也是正态分布。在这种情况下,是可靠的 和 可以对系数估计进行检验,以评估预测器的显著性,并可以使用标准公式构造置信区间来描述估计器的方差。正常也允许 实现Cramér-Rao的下限(它变成非常高效。),其估计值与MLE相同。
不管分布如何 中心极限定理保证了这一点 将在大样本中近似正态分布,因此与模型规范相关的标准推理技术将渐近有效。然而,如前所述,经济数据的样本通常相对较小,并且不能依赖中心极限定理来产生估计的正态分布。
静态计量经济学模型表示只对当前事件作出反应的系统。静态MLR模型假设构成预测列的预测因子 与回应是同步的吗 .对于这些模型来说,CLM假设的评估相对简单。
相比之下,动态模型使用滞后预测值随时间合并反馈。CLM假设中没有明确排除具有滞后或超前的预测值。事实上,滞后预测值外生预测 ,不与创新互动 ,本身并不影响OLS估计的高斯-马尔可夫最优性。如果预测因素包括近似滞后 , , ,…,但是,正如经济模型通常所做的那样,可能会引入预测相互依赖性,违反CLM的无共线假设,并产生OLS估计的相关问题。示例中讨论了此问题时间序列回归II:共线性和估计量方差.
当预测内生,由响应的滞后值决定 (自回归模型),通过预测因子和创新之间的递归交互,违反了CLM严格外生性假设。在这种情况下,会出现其他更严重的OLS估计问题。示例中讨论了该问题时间序列回归VIII:滞后变量和估计偏差.
违反CLM假设 (nonspherical创新)在示例中讨论了这些问题时间序列回归VI:残留诊断.
违反CLM假设并不一定使OLS估计结果无效。然而,重要的是要记住,个别违规行为的影响将或多或少地产生后果,这取决于它们是否与其他违规行为相结合。规范分析试图识别所有的违规,评估对模型评估的影响,并在建模目标的上下文中提出可能的补救措施。
时间序列数据
考虑一个信用违约率的简单MLR模型。该文件Data_CreditDefaults.mat包含投资级公司债券违约的历史数据,以及1984年至2004年四个潜在预测因素的数据:
负载Data_CreditDefaults
X0=数据(:,1:4);初始预测器集(矩阵)X0Tbl = DataTable (:, 1:4);%初始预测集(表格数组)predNames0=系列(1:4);%初始预测器集名称T0 =大小(X0, 1);%样本大小y0=数据(:,5);%响应数据respName0 ={5}系列;%响应数据名称
潜在的预测者,测量了一年t,有:
年龄投资级债券发行人在3年前首次获得评级的百分比。这些相对较新的发行人在首次发行的资本支出后(通常是在大约3年后)具有较高的违约经验概率。
BBB标准普尔信用评级为最低投资级BBB的投资级债券发行人的百分比。这个百分比代表了另一个风险因素。
中央公积金提前一年预测公司利润的变化,经通胀调整。该预测是对整体经济健康状况的衡量,作为更大商业周期的指标。
SPR公司债券收益率与可比政府债券收益率之差。价差是衡量当前问题风险的另一个指标。
以年为单位衡量的反应t+ 1,是:
IGD投资级公司债券违约率
中描述的[2]和[4]在美国,预测指标是由其他系列构建的代理指标。建模的目标是生成一个动态预测模型,在响应中提前一年(等效地,预测器滞后一年)。
我们首先检查数据,将日期转换为连续的日期编号,以便实用程序函数recessionplot可以覆盖显示商业周期相关低谷的波段:
将日期转换为日期编号:dateNums=datenum([日期,一(T0,2)]);% Plot潜在预测因子:图;情节(dateNums X0,“线宽”,2) ax = gca;斧子。XTick = dateNums(1:2:end); datetick(“x”,“yyyy”,“keepticks”)衰退图(“年”)伊拉贝尔(的预测水平)传说(predNames0“位置”,“西北”)标题(“{\ bf潜力预测}”)轴(“紧”)网格(“上”)

%情节反应:图;持有(“上”);绘图(日期,y0,“k”,“线宽”2);情节(dateNums y0-detrend (y0),“我——”)持有(“关闭”);ax=gca;ax.XTick=dateNums(1:2:end);datetick(“x”,“yyyy”,“keepticks”)衰退图(“年”)伊拉贝尔(“响应级别”)传说(respName0“线性趋势”,“位置”,“西北”)标题(“{\bf响应}”)轴(“紧”);网格(“上”);
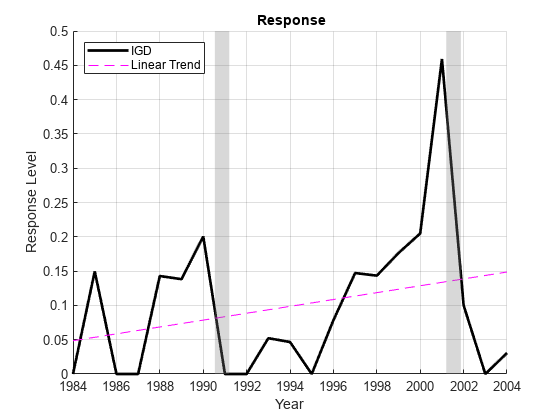
我们可以看到,BBB与其他预测因子的量表略有不同,并且随着时间的推移呈趋势。因为响应数据是针对一年的t+1,违约率的峰值实际上是在衰退之后出现的t= 2001.
模型分析
预测器和响应数据现在可以组装成一个MLR模型,OLS估计
可以使用MATLAB反斜杠找到(\)操作符:
%向模型添加截距:X0I = [(T0, 1), X0];%母体X0ITbl =[表的(T0, 1),“VariableNames”,{“常量”}),X0Tbl];%的表估计= X0I \ y0
估计=5×1-0.2274 0.0168 0.0043 -0.0149 0.0455
或者,可以使用的方法检查模型LinearModel类,它提供诊断信息和许多方便的分析选项fitlm(相当于静态方法LinearModel.fit)来估计模型的系数
从数据。默认情况下,它会添加一个拦截。以表格数组的形式传入数据,其中包含变量名和最后一列的响应值,返回一个带有标准诊断统计数据的拟合模型:
M0 = fitlm(数据表)
M0 =线性回归模型:IGD ~ 1 + AGE + BBB + CPF + SPREstimate SE tStat pValue _________ _________ _______ _________ (Intercept) -0.22741 0.098565 -2.3072 0.034747 AGE 0.016781 0.0091845 1.8271 0.086402 BBB 0.0042728 0.0026757 1.5969 0.12985 CPF -0.014888 0.0038077 -3.91 0.0012473 SPR 0.045488 0.033996 1.338 0.1996观测数:21,误差自由度:16均方根误差:0.0763 R-squared: 0.621, Adjusted R-squared: 0.526 F-statistic vs. constant model: 6.56, p-value = 0.00253
关于该模型的可靠性还有很多问题需要问。预测因子是否是所有潜在反应预测因子的良好子集?系数估计值是否准确?预测因子与反应之间的关系是否确实是线性的?模型预测是否可靠?简言之,模型是否明确规定,OLS是否有效很好地将其与数据相匹配?
另一种方法LinearModel类,方差分析,以表格数组的形式返回额外的拟合统计信息,这对于在更扩展的规范分析中比较嵌套模型很有用:
方差分析=方差分析(M0)
ANOVATable =5×5表SumSq DF MeanSq F pValue ________ __ _________ ______ _________ AGE 0.019457 1 0.019457 3.3382 0.086402 BBB 0.014863 1 0.014863 2.55 0.12985 CPF 0.089108 1 0.089108 15.288 0.0012473 SPR 0.010435 1 0.010435 1.7903 0.1996 Error 0.09326 16 0.0058287
总结
模型规范是计量分析的基本任务之一。最基本的工具是回归,广义上的参数估计,用于评估一系列候选模型。然而,任何形式的回归都依赖于某些假设和某些技术,而这些在实践中几乎从未得到充分证明。因此,使用带有默认设置的标准过程的单一应用程序很难获得信息丰富、可靠的回归结果。相反,它们需要一个经过深思熟虑的规范、分析和再规范的循环,由实践经验、相关理论和对许多情况的认识——在这些情况下,考虑不周的统计证据可能会混淆合理的结论。
探索性数据分析是此类分析的关键组成部分。实证计量经济学的基础是,好的模型只有通过与好的数据的相互作用才能产生。如果数据有限(这在计量经济学中经常发生),分析必须承认由此产生的歧义,并帮助确定一系列可供考虑的替代模型。装配最可靠的型号没有标准的程序。好的模型从数据中产生,并能适应新的信息。
本系列中的后续示例考虑线性回归模型,由一组潜在的预测因子构建并校准为相当小的一组数据。尽管如此,这些技术和所考虑的MATLAB工具箱函数仍然是典型规范分析的代表。更重要的是,从最初的数据分析,到初步的模型建立和完善,最后到在预测性能的实际领域进行测试,这一工作流程也是相当典型的。正如大多数实证研究一样,过程才是关键。
参考文献
[1]克拉姆,H。数理统计方法.新泽西州普林斯顿:普林斯顿大学出版社,1946年。
[2]Helwege,J.和P.Kleiman。“理解高收益债券的总违约率”,纽约联邦储备银行《经济与金融时事》.1996年第2卷第6期,第1-6页。
[3]肯尼迪,P。计量经济学指南.第6版。纽约:约翰·威利父子,2008。
[4]G.吕弗勒和P. N.波许。基于Excel和VBA的信用风险建模.英格兰西苏塞克斯:威利金融,2007。
[5]斯特朗,G。线性代数及其应用.第四版,太平洋格罗夫,CA:布鲁克斯科尔,2005。
您还可以从以下列表中选择网站:
