信用计分卡分析案例研究
这个例子显示了如何创建一个creditscorecard对象,本数据、显示和分箱数据信息。这个示例还展示了如何符合逻辑回归模型,获得分数计分卡模型,并确定违约概率和验证信用计分卡模型使用三个不同的指标。
步骤1。创建一个creditscorecard对象。
使用CreditCardData.mat文件加载数据(使用一个数据集从Refaat 2011)。如果你的数据包含很多因素,你可以首先使用screenpredictors(风险管理工具箱)减少潜在的大组预测最有预测力的一个子集信用计分卡反应变量。然后,您可以使用这个子集创建时的预测creditscorecard对象。此外,您可以使用阈值预测(风险管理工具箱)交互式地建立信用计分卡使用的输出预测阈值screenpredictors(风险管理工具箱)。
当创建一个creditscorecard对象,默认情况下,“ResponseVar”将最后一列数据(“状态”在这个例子中)和“GoodLabel”最高的响应值数(0在本例中)。的语法creditscorecard表明“CustID”是“IDVar”从列表中移除的预测因子。同时,虽然不是在这个例子中,当创建一个creditscorecard对象使用creditscorecard,您可以使用可选的名称-值对的论点“WeightsVar”指定观察(样本)权重或“BinMissingData”本丢失的数据。
负载CreditCardData头(数据)
ans =8×11表CustID CustAge TmAtAddress ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance UtilRate地位______ ___________ _____ _____ __________ ____ ____ ____ ________ ________ 62 53租户未知50000 55是的1055.9 - 0.22 0 2 61 22业主雇佣52000 25是的1161.6 - 0.24 0 3 47 30租户雇佣了37000 61 877.23 0.29 0 4 50 75房主雇用了53000名20是的157.37 - 0.08 0 5 68 56家老板雇用了53000名14是的561.84 - 0.11 0 6 65 13业主雇用了48000名59岁是的968.18 - 0.15 0 7 34 32房主未知32000 26是的717.82 0.02 1 8 50 57其他雇佣了51000 33没有3041.2 - 0.13 0
中的变量CreditCardData包括客户ID、客户年龄,时间在当前地址、居住状况、就业状况、客户收入、时间与银行其他信用卡,每月平均平衡,利用率和默认状态(响应)。
sc = creditscorecard(数据,“IDVar”,“CustID”)
sc = creditscorecard属性:GoodLabel: 0 ResponseVar:“地位”WeightsVar:“VarNames: {1 x11细胞}NumericPredictors: {1} x6细胞CategoricalPredictors: {“ResStatus”“EmpStatus”“OtherCC”} BinMissingData: 0 IDVar:“CustID”PredictorVars: {1 x9细胞}数据:[1200 x11表)
执行一些初始数据探索。询问预测统计类别变量“ResStatus”和策划的本信息“ResStatus”。
bininfo (sc,“ResStatus”)
ans =4×6表本好与坏的几率,悲哀出生______替InfoValue * * *{‘业主’}365 177 2.0621 0.019329 0.0001682{“租户”}307 167 1.8383 -0.095564 0.0036638{‘其他’}131年53 2.4717 0.20049 0.0059418{“总数”}803 397 0.0097738 2.0227南
plotbins (sc,“ResStatus”)
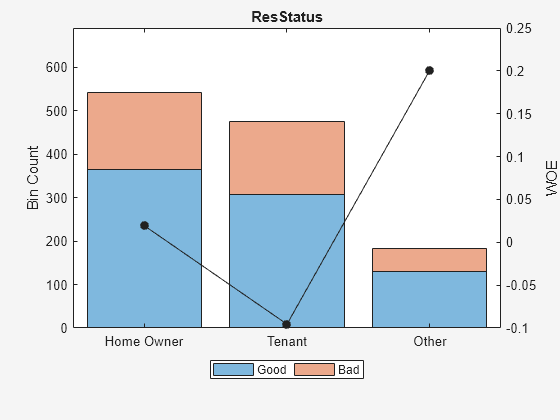
本信息包含频率的“好”和“坏”,和本统计数据。避免和频率的零箱,因为他们导致无限或未定义(南)统计数据。使用modifybins或autobinning本数据相应的功能。
对于数值型数据,一个常见的第一步是“细分级”。This means binning the data into several bins, defined with a regular grid. To illustrate this point, use the predictor“CustIncome”。
cp = 20000:5000:60000;sc = modifybins (sc,“CustIncome”,“割点”,cp);bininfo (sc,“CustIncome”)
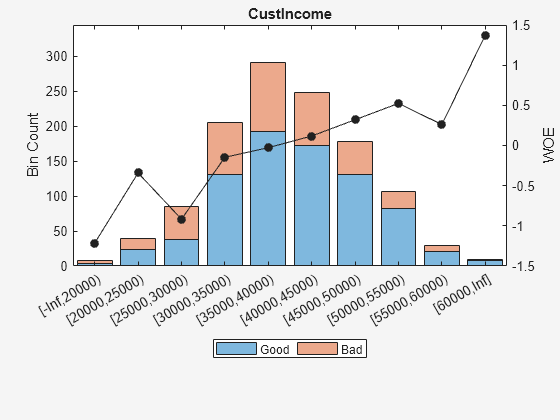
ans =11×6表本好与坏的几率,悲哀InfoValue _________________出生_____ _____{[无穷,20000)的}3 5 0.6 -1.2152 0.010765{[20000、25000)的}23日16 1.4375 -0.34151 0.0039819{[25000、30000)的}38 47 0.80851 -0.91698 0.065166{[30000、35000)的}131 75 1.7467 -0.14671 0.003782{[35000、40000)的}193 98 1.9694 -0.026696 0.00017359{[40000、45000)的}173 76 2.2763 0.11814 0.0028361{[45000、50000)}131年47 2.7872 0.32063 0.014348{[50000、55000)}82年24 3.4167 0.52425 0.021842{[55000、60000)的}21 8 2.625 0.26066 0.0015642{”(60000年,正)}8 1 8 1.375 - 0.010235{“总数”}803 397 0.13469 2.0227南
plotbins (sc,“CustIncome”)
步骤2。自动本数据。
使用autobinning函数执行自动装箱每个预测变量,使用默认值“单调”算法使用默认算法的选择。
sc = autobinning (sc);
自动装箱后一步,每一个预测本必须审查使用bininfo和plotbins函数和调整。单调,理想的线性趋势的证据的效力(悲哀)信用计分卡是可取的,因为这转化为线性点对于一个给定的预测。悲哀的趋势可以可视化使用plotbins。
预测= “ResStatus”;预测plotbins (sc)
“ResStatus”;预测plotbins (sc)


不像最初的情节“ResStatus”计分卡创建时,新的情节“ResStatus”显示了一个悲哀的趋势增加。这是因为autobinning函数,默认情况下,各种类别的顺序增加。
这些情节显示“单调”算法很好地为这个数据集找到单调趋势有祸了。完成装箱过程中,有必要让只有少数一些预测使用手动调整modifybins函数。
步骤2 b。调整箱子使用人工装箱。
常见的手动修改箱步骤:
使用
bininfo函数有两个输出参数,第二个参数包含装箱规则。手动修改装箱规则使用第二个输出参数
bininfo。更新的装箱规则集
modifybins然后使用plotbins或bininfo审查更新的垃圾箱。
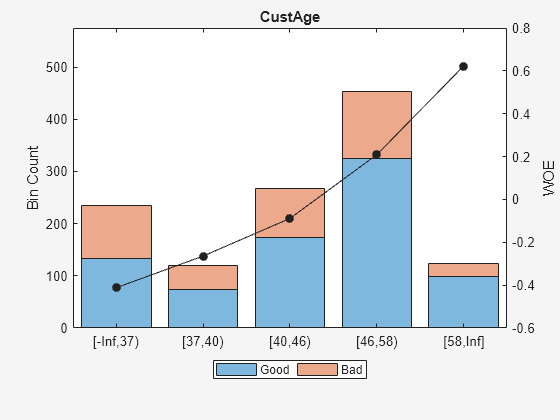
例如,基于的阴谋“CustAge”在步骤2中,箱子数量1和2也有类似的悲哀的箱数5和6。合并这些箱子使用上面列出的步骤:
预测= “CustAge”;(bi, cp) = bininfo (sc、预测)
“CustAge”;(bi, cp) = bininfo (sc、预测)

bi =8×6表本好与坏的几率,悲哀InfoValue _________________出生______替{[无穷,33)}70年53 1.3208 -0.42622 0.019746{[33岁,37)}64年47 1.3617 -0.39568 0.015308{[37、40)}73年47 1.5532 -0.26411 0.0072573{'[40岁,46)}174 94 1.8511 -0.088658 0.001781{[46岁,48)}61年25 2.44 0.18758 0.0024372{[48,58)的}263 105 2.5048 0.21378 0.013476{的[58岁的Inf]} 98年26 3.7692 0.62245 0.0352{“总数”}803 397 0.095205 2.0227南
cp =6×133 37 40 46 48 58
cp = [] ([1 5]);% 1和2合并垃圾箱,垃圾箱5和6sc = modifybins (sc,“CustAge”,“割点”,cp);plotbins (sc,“CustAge”)
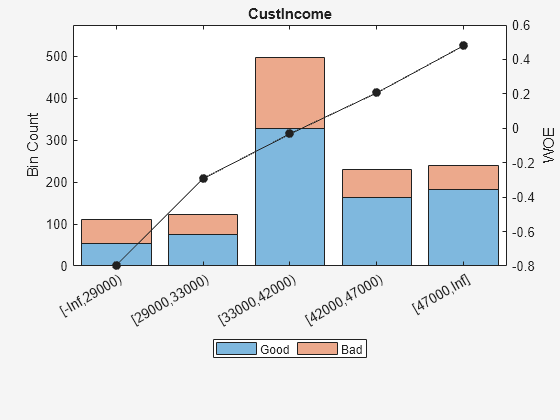
为“CustIncome”基于上面的情节,最好合并箱3、4和5,因为他们有类似的有祸了。合并这些垃圾箱:
预测= “CustIncome”;(bi, cp) = bininfo (sc、预测)
“CustIncome”;(bi, cp) = bininfo (sc、预测)

bi =8×6表本好与坏的几率,悲哀InfoValue _________________出生_____ _____{[无穷,29000)的}53 58 0.91379 -0.79457 0.06364{[29000、33000)}74年49 1.5102 -0.29217 0.0091366{[33000、35000)的36}68 1.8889 -0.06843 0.00041042{[35000、40000)的}193 98 1.9694 -0.026696 0.00017359{[40000、42000)的}68 34 2 -0.011271 - 1.0819 e-05{[42000、47000)的}164 66 2.4848 0.20579 0.0078175{”(47000年,正)}183年56 3.2679 0.47972 0.041657{“总数”}803 397 0.12285 2.0227南
cp =6×129000 33000 35000 40000 42000 47000
cp ([3 - 4]) = [];%将箱子3、4、5所示sc = modifybins (sc,“CustIncome”,“割点”,cp);plotbins (sc,“CustIncome”)
为“TmWBank”基于上面的图,最好是合并箱2和3,因为他们有类似的有祸了。合并这些垃圾箱:
预测= “TmWBank”;(bi, cp) = bininfo (sc、预测)
“TmWBank”;(bi, cp) = bininfo (sc、预测)

bi =6×6表本好与坏的几率,悲哀InfoValue _________________出生______月______ _____{'[无穷,12)}141 90 1.5667 -0.25547 0.013057{'[12、23)}165 93 1.7742 -0.13107 0.0037719{' 45(23日)}224 125 1.792 -0.12109 0.0043479{'[71)}177 67 2.6418 0.26704 0.013795{”(71年,正)}96年22 4.3636 0.76889 0.049313{“总数”}803 397 0.084284 2.0227南
cp =4×171年12日23日45
cp (2) = [];%合并箱2和3sc = modifybins (sc,“TmWBank”,“割点”,cp);plotbins (sc,“TmWBank”)

为“AMBalance”基于上面的图,最好是合并箱2和3,因为他们有类似的有祸了。合并这些垃圾箱:
预测= “AMBalance”;(bi, cp) = bininfo (sc、预测)
“AMBalance”;(bi, cp) = bininfo (sc、预测)

bi =5×6表本好与坏的几率,悲哀InfoValue _____________________出生______月______ _____{[无穷,558.88)的}346 134 2.5821 0.24418 0.022795{[558.88,1254.28)的}309 171 1.807 -0.11274 0.0051774{[1254.28,1597.44)的}76年44 1.7273 -0.15787 0.0025554{'[1597.44,正]}72年48 1.5 -0.29895 0.0093402{“总数”}803 397 0.039868 2.0227南
cp =3×1103×0.5589 1.2543 1.5974
cp (2) = [];%合并箱2和3sc = modifybins (sc,“AMBalance”,“割点”,cp);plotbins (sc,“AMBalance”)
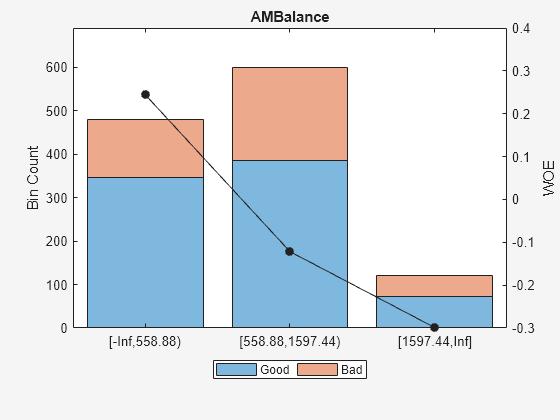
现在装箱调整完成后,所有的预测都有close-to-linear悲哀的垃圾箱的趋势。
步骤3。符合逻辑回归模型。
的fitmodel功能符合逻辑回归模型有祸了数据。fitmodel内部箱子的训练数据,将它转换成悲哀的价值观,这地图响应变量‘好’是1,符合线性逻辑回归模型。默认情况下,fitmodel使用一个逐步的过程,以确定哪些因素应该在模型中。
sc = fitmodel (sc);
1。添加CustIncome、偏差= 1490.8954 Chi2Stat = 32.545914, PValue = 1.1640961 e-08 2。添加TmWBank、偏差= 1467.3249 Chi2Stat = 23.570535, PValue = 1.2041739 e-06 3。添加AMBalance、偏差= 1455.858 Chi2Stat = 11.466846, PValue = 0.00070848829 - 4。添加EmpStatus、偏差= 1447.6148 Chi2Stat = 8.2432677, PValue = 0.0040903428 5。添加CustAge、偏差= 1442.06 Chi2Stat = 5.5547849, PValue = 0.018430237 6。添加ResStatus、偏差= 1437.9435 Chi2Stat = 4.1164321, PValue = 0.042468555 7。添加OtherCC、偏差= 1433.7372 Chi2Stat = 4.2063597, PValue = 0.040272676广义线性回归模型:状态~(与8项7预测线性公式)=二项分布估计系数:估计SE tStat PValue ________ ________ _____(拦截)0.7024 0.064 10.975 5.0407即使CustAge EmpStatus ResStatus 0.012988 0.61562 0.24783 2.4841 1.3776 0.65266 2.1107 0.034799 0.88592 0.29296 3.024 0.0024946 CustIncome TmWBank 0.0013001 0.69836 0.21715 3.216 1.106 0.23266 4.7538 1.9958 e-06 OtherCC AMBalance 0.038806 1.0933 0.52911 2.0662 1.0437 0.32292 3.2322 0.0012285 1200观察,1192错误自由度色散:1 x ^ 2-statistic与常数模型:89.7,p = 1.42 e-16
步骤4。审查和格式计分卡点。
合适的物流模式后,默认情况下,点们和直接来自悲哀的组合值和模型系数。的displaypoints总结了计分卡点函数。
p1 = displaypoints (sc);disp (p1)
____________________ ___________预测本点* * * {‘CustAge}{[负无穷,37)的-0.15314}{‘CustAge}{[37、40)的-0.062247}{‘CustAge}{[40岁,46)的0.045763}{‘CustAge}{[46岁,58)的0.22888}{“CustAge”}{的[58岁的Inf]} 0.48354 {‘CustAge}{' <失踪>}南{‘ResStatus}{“租户”}-0.031302 {‘ResStatus}{‘业主’}0.12697 {‘ResStatus}{‘其他’}0.37652 {‘ResStatus}{' <失踪>}南{‘EmpStatus}{‘未知’}-0.076369 {‘EmpStatus}{“雇佣”}0.31456 {‘EmpStatus}{' <失踪>}南{‘CustIncome}{[无穷,29000)的-0.45455}{‘CustIncome}{[29000、33000)的-0.1037}{‘CustIncome}{[33000、42000)的0.077768}{‘CustIncome}{[42000、47000)的0.24406}{‘CustIncome}{”(47000年,正)}0.43536 {‘CustIncome}{' <失踪>}南{‘TmWBank}{[无穷,12)的-0.18221}{‘TmWBank}{[12日45)的-0.038279}{‘TmWBank}{[71)的0.39569}{‘TmWBank}{”(71年,正)}0.95074 {‘TmWBank}{' <失踪>}南{‘OtherCC}{‘不’}-0.193 {‘OtherCC}{'是的'}0.15868 {‘OtherCC}{' <失踪>}南{‘AMBalance}{[无穷,558.88)的0.3552}{‘AMBalance}{[558.88, 1597.44)的-0.026797}{‘AMBalance}{'[1597.44,正]}-0.21168 {‘AMBalance}{' <失踪>}NaN
这是一个很好的时间来修改本标签,如果这是对化妆品的原因。为此,使用modifybins改变本标签。
sc = modifybins (sc,“CustAge”,“BinLabels”,…{“36”37到39的40到45的“46 57”“58,”});sc = modifybins (sc,“CustIncome”,“BinLabels”,…{“28999”“29000 - 32999”“33000 - 41999”“42000 - 46999”“47000,”});sc = modifybins (sc,“TmWBank”,“BinLabels”,…{“11”“12至44”45到70的“71,”});sc = modifybins (sc,“AMBalance”,“BinLabels”,…{“558.87”558.88到1597.43的“1597.44”,});p1 = displaypoints (sc);disp (p1)
预测本_____________________ ____分* * * {‘CustAge}{‘多达36}-0.15314 {‘CustAge}{' 37到39}-0.062247 {‘CustAge}{40到45的}0.045763 {‘CustAge} {“46 57”} 0.22888 {‘CustAge}{' 58和}0.48354 {‘CustAge}{' <失踪>}南{‘ResStatus}{“租户”}-0.031302 {‘ResStatus}{‘业主’}0.12697 {‘ResStatus}{‘其他’}0.37652 {‘ResStatus}{' <失踪>}南{‘EmpStatus}{‘未知’}-0.076369 {‘EmpStatus}{“雇佣”}0.31456 {‘EmpStatus}{' <失踪>}南{‘CustIncome} {‘28999’} -0.45455 {‘CustIncome} {“29000 - 32999”} -0.1037 {‘CustIncome} {“33000 - 41999”} 0.077768 {‘CustIncome} {“42000 - 46999”} 0.24406 {‘CustIncome}{' 47000和'}0.43536 {‘CustIncome}{' <失踪>}南{‘TmWBank} {' 11 '} -0.18221 {‘TmWBank}{' 12至44}-0.038279 {‘TmWBank}{' 45到70}0.39569 {‘TmWBank}{' 71和'}0.95074 {‘TmWBank}{' <失踪>}南{‘OtherCC}{‘不’}-0.193 {‘OtherCC}{'是的'}0.15868 {‘OtherCC}{' <失踪>}南{‘AMBalance} {‘558.87’} 0.3552 {‘AMBalance}{558.88到1597.43的}-0.026797 {‘AMBalance}{" 1597.44和}-0.21168 {‘AMBalance}{' <失踪>}NaN
点通常是按比例缩小的,也经常圆。要做到这一点,使用formatpoints函数。例如,你可以设定一个目标点对应于一个目标概率水平和水平也设置所需points-to-double-the-odds (PDO)。
“靶点= 500;TargetOdds = 2;PDO = 50;%几率的两倍sc = formatpoints (sc,“PointsOddsAndPDO”,(靶点TargetOdds PDO));p2 = displaypoints (sc);disp (p2)
_____________________ ______预测本点* * * {‘CustAge}{‘多达36}53.239 {‘CustAge}{' 37到39}59.796 {‘CustAge}{40到45的}67.587 {‘CustAge} {“46 57”} 80.796 {‘CustAge}{' 58和}99.166 {‘CustAge}{' <失踪>}南{‘ResStatus}{“租户”}62.028 {‘ResStatus}{‘业主’}73.445 {‘ResStatus}{‘其他’}91.446 {‘ResStatus}{' <失踪>}南{‘EmpStatus}{‘未知’}58.777 {‘EmpStatus}{“雇佣”}86.976 {‘EmpStatus}{' <失踪>}南{‘CustIncome} {‘28999’} 31.497 {‘CustIncome} {“29000 - 32999”} 56.805 {‘CustIncome} {“33000 - 41999”} 69.896 {‘CustIncome} {“42000 - 46999”} 81.891 {‘CustIncome}{' 47000和'}95.69 {‘CustIncome}{' <失踪>}南{‘TmWBank} {' 11 '} 51.142 {‘TmWBank}{' 12至44}61.524 {‘TmWBank}{' 45到70}92.829 {‘TmWBank}{' 71和'}132.87 {‘TmWBank}{' <失踪>}南{‘OtherCC}{‘不’}50.364 {‘OtherCC}{'是的'}75.732 {‘OtherCC}{' <失踪>}南{‘AMBalance} {‘558.87’} 89.908 {‘AMBalance}{558.88到1597.43的}62.353 {‘AMBalance}{" 1597.44和}49.016 {‘AMBalance}{' <失踪>}NaN
第5步。得分数据。
的分数函数计算训练数据的分数。一个可选的数据还可以通过输入分数例如,验证数据。分预测值为每个客户提供一个可选的输出。
(分数,分)=分数(sc);disp(分数(1:10))
528.2044 554.8861 505.2406 564.0717 554.8861 586.1904 441.8755 515.8125 524.4553 508.3169
disp(点(1:10,:))
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance ____ ____替_____ _____ 80.796 62.028 58.777 95.69 92.829 75.732 62.353 99.166 73.445 86.976 95.69 61.524 75.732 62.353 80.796 62.028 86.976 69.896 92.829 50.364 62.353 80.796 73.445 86.976 95.69 61.524 75.732 89.908 99.166 73.445 86.976 95.69 61.524 75.732 62.353 99.166 73.445 86.976 95.69 92.829 75.732 62.353 53.239 73.445 58.777 56.805 61.524 75.732 62.353 80.796 91.446 86.976 95.69 61.524 50.364 49.016 80.796 62.028 58.777 95.69 61.524 75.732 89.908 80.796 73.445 58.777 95.69 61.524 75.732 62.353
步骤6。计算违约概率。
计算违约概率,使用probdefault函数。
pd = probdefault (sc);
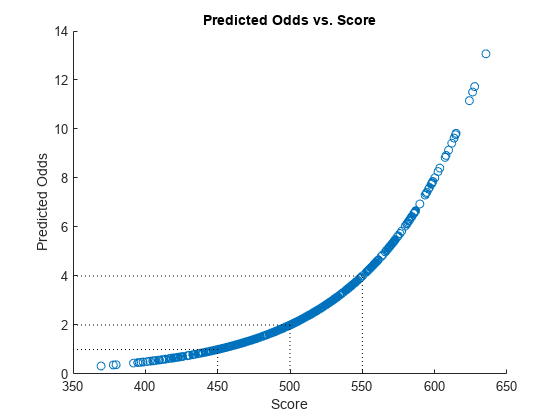
定义“好”的概率和情节预测的可能性和格式化的分数。视觉分析的目标点和目标匹配和points-to-double-the-odds (PDO)的关系。
ProbGood = 1 pd;PredictedOdds = ProbGood. / pd;图散射(分数,PredictedOdds)标题(预测概率与分数的)包含(“分数”)ylabel (“预测概率”)举行在xLimits = xlim;yLimits = ylim;%的目标点和可能性情节([靶点靶点]、[yLimits (1) TargetOdds),凯西:”)情节([xLimits(1)靶点],[TargetOdds TargetOdds),凯西:”)% + PDO目标点情节([靶点+ PDO靶点+ PDO], [yLimits (1) 2 * TargetOdds),凯西:”)情节([xLimits(1)靶点+ PDO], [2 * 2 * TargetOdds TargetOdds],凯西:”)% - PDO目标点情节([TargetPoints-PDO TargetPoints-PDO]、[yLimits (1) TargetOdds / 2),凯西:”)情节([xLimits (1) TargetPoints-PDO], [TargetOdds / 2 TargetOdds / 2)凯西:”)举行从
步骤7。验证信用计分卡模型使用帽,中华民国,Kolmogorov-Smirnov统计
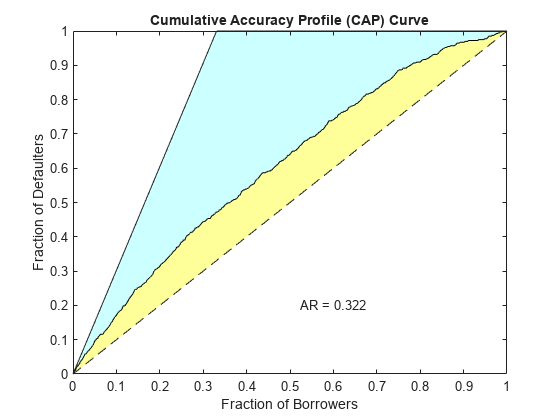
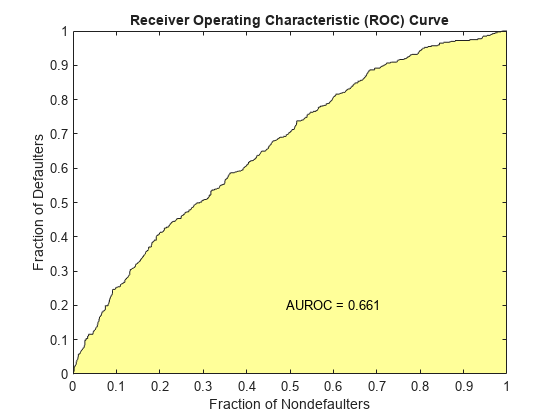
的creditscorecard类支持三种验万博1manbetx证方法,累积精度(CAP),接受者操作特征(ROC), Kolmogorov-Smirnov(钴)统计。在限制的更多信息,中华民国,KS,看到的累积准确性概要(CAP),接受者操作特征(中华民国),Kolmogorov-Smirnov统计(KS)。
(统计、T) = validatemodel (sc,“阴谋”,{“帽子”,“中华民国”,“KS”});
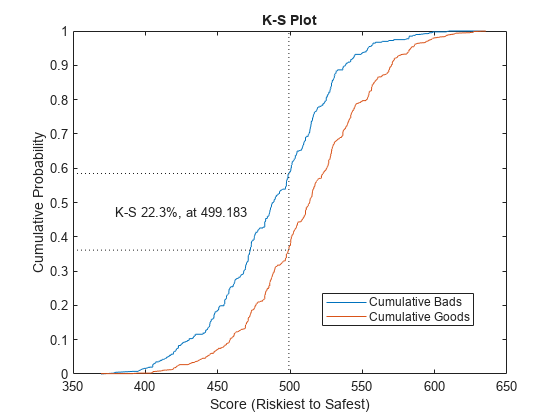
disp(统计)
测量值________________________ _________ 0.32225{的精度比}{ROC曲线下面积的}0.66113 {“KS统计”}0.22324 499.18 {“k值”}
disp (T (1:15)):
分数ProbDefault TrueBads FalseBads TrueGoods FalseGoods敏感性FalseAlarm PctObs ______⒈替__________ ________ ___________ __________ __________ 369.4 - 0.7535 0 0 0.0012453 0.00083333 377.86 0.73107 1 1 1 802 397 802 396 0.0025189 0.0012453 0.0016667 379.78 0.7258 - 2 1 802 395 3 1 802 394 0.0075567 0.0050378 0.0012453 0.0025 391.81 0.69139 0.0012453 0.0033333 394.77 0.68259 801 394 0.0075567 0.0024907 0.0041667 395.78 0.67954 - 4 2 5 801 393 0.010076 0.0024907 0.005 396.95 0.67598 801 392 0.012594 0.0024907 0.0058333 398.37 0.67167 6 2 801 391 0.015113 0.0024907 0.0066667 401.26 0.66276 801 390 0.017632 0.0024907 0.0075 403.23 0.65664 389 801 0.020151 0.0024907 0.0083333 405.09 0.65081 8 3 800 389 0.020151 0.003736 0.0091667 405.15 0.65062 11 5 798 386 0.027708 0.0062267 0.013333 405.37 0.64991 11 6 797 386 0.027708 0.007472 0.014167 406.18 0.64735 12 6 797 385 0.030227 0.007472 0.015 407.14 0.64433 13 6 797 384 0.032746 0.007472 0.015833
另请参阅
creditscorecard|autobinning|bininfo|predictorinfo|modifypredictor|modifybins|bindata|plotbins|fitmodel|displaypoints|formatpoints|分数|setmodel|probdefault|validatemodel|紧凑的
