一加仑汽油所行驶的里程的预测
此示例显示了如何使用先前记录的观测数据预测汽车的燃油消耗量(每加仑英里数)。
介绍
汽车每加仑英里数预测是一个典型的非线性回归问题,它利用汽车外形信息的多个属性来预测另一个连续属性——每加仑英里数。训练数据可在UCI(加州大学欧文分校)获得机器学习库并包含了从不同品牌和型号的汽车中收集的数据。
上面的表格是来自MPG数据集的几个观察或样本。这六个输入属性是no。气缸、排量、马力、重量、加速度和型号年份。要预测的输出变量是MPG中的油耗。(表格第一列的汽车制造商和车型不用于预测)。
分区数据
数据集从原始数据文件“auto gas.dat”中获取。然后将数据集划分为训练集(奇数索引样本)和检查集(偶数索引样本)。
[数据,输入\名称]=负荷气体;trn_data=数据(1:2:end,:);chk_数据=数据(2:2:end,:);
输入选择
功能exhsrch在可用输入内执行穷举搜索,以选择对燃油消耗影响最大的输入集。函数的第一个参数指定搜索期间要尝试的输入组合数。基本上,exhsrch为每个组合建立一个ANFIS模型,对其进行一个历元的训练,并报告所取得的绩效。在下面的示例中,exhsrch用于确定在预测输出时最具影响力的输入属性。
exhsrch(1,trn_数据,chk_数据,输入_名称);
第6列ANFIS模型,每个模型有1个从6个候选中选择的输入…ANFIS模型1:气缸-->trn=4.6400,chk=4.7255 ANFIS模型2:Disp-->trn=4.3106,chk=4.4316 ANFIS模型3:功率-->trn=4.5399,chk=4.1713 ANFIS模型4:重量-->trn=4.2577,chk=4.0863 ANFIS模型5:加速器-->trn=6.9789,chk=6.9317 ANFIS模型6:年份-->trn=6.2255,chk=6.1693
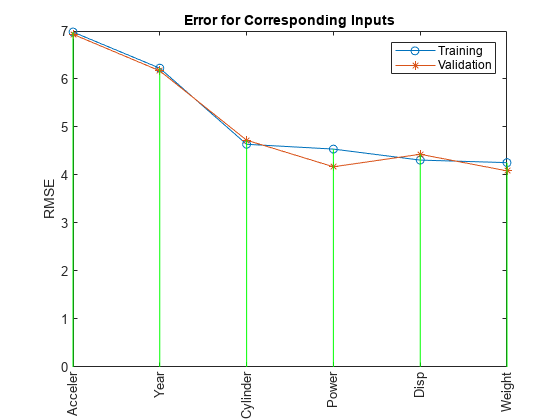
图1:各输入变量对油耗的影响
图1中最左边的输入变量错误最小,换句话说,与输出最相关。
函数的绘图和结果清楚地表明,输入属性“Weight”是最具影响力的。训练和检查错误是可比较的,这意味着没有过拟合。这意味着我们可以进一步探索是否可以选择多个输入属性来构建ANFIS模型。
凭直觉,我们可以简单地选择重量和Disp直接,因为他们有最少的错误,如图中所示。然而,这并不一定是导致最小训练误差的两个输入的最佳组合。为了验证这一点,我们可以使用exhsrch搜索两个输入属性的最佳组合。
input_index=exhsrch(2,trn_数据,chk_数据,input_名称);
训练15个ANFIS模型,每个模型从6个候选模型中选择2个输入。ANFIS model 1: Cylinder Disp—> trn=3.9320, chk=4.7920 ANFIS model 2: Cylinder Power—> trn=3.7364, chk=4.8683 ANFIS model 3: Cylinder Weight—> trn=3.8741, chk=4.6763 ANFIS model 4: Cylinder Acceler—> trn=4.3287, chk=5.9625 ANFIS model 5: Cylinder Year—> trn=3.7129, chk=4.5946 ANFIS model 6:Disp Power—> trn=3.8087, chk=3.8594 ANFIS模型7:Disp Weight—> trn=4.0271, chk=4.6350 ANFIS模型8:Disp加速器—> trn=4.0782, chk=4.4890 ANFIS模型9:Disp Year—> trn=2.9565, chk=3.3905 ANFIS模型10:Power Weight—> trn=3.9310, chk=4.2976 ANFIS模型11:Power Acceler—> trn=4.2740, chk=3.8738 ANFIS模型12:ANFIS模型14:Weight Year—> trn=2.7657, chk=2.9953 ANFIS模型15:accelerer Year—> trn=5.6242, chk=5.6481

图2:所有两个输入变量组合及其对燃油消耗的影响
结果来自exhsrch表明,重量和一年形成两个输入属性的最佳组合。训练和检查错误得到区分,表明过度拟合的开始。使用两个以上的输入来构建ANFIS模型可能不谨慎。我们可以测试这个前提以验证其有效性。
exhsrch(3,trn_数据,chk_数据,输入_名称);
第20列ANFIS模型,每个模型有3个输入,从6个候选中选择…ANFIS模型1:气缸分配功率-->trn=3.4446,chk=11.5329 ANFIS模型2:气缸分配重量-->trn=3.6686,chk=4.8922 ANFIS模型3:气缸分配加速器-->trn=3.6610,chk=5.2384 ANFIS模型4:气缸分配年份-->trn=2.5463,chk=4.9001 ANFIS模型5:气缸分配Po加权-->trn=3.4797,chk=9.3761 ANFIS 6型:气缸功率加速计-->trn=3.5432,chk=4.4804 ANFIS 7型:气缸功率年-->trn=2.6300,chk=3.6300 ANFIS 8型:气缸重量加速计-->trn=3.5708,chk=4.8379 ANFIS 9型:气缸重量年-->trn=2.4951,chk=4.0435 ANFIS 10型:气缸加速计年-->trn=3.2698,chk=6.2616 ANFIS模型11:Disp功率重量-->trn=3.5879,chk=7.4942 ANFIS模型12:Disp功率加速计-->trn=3.5395,chk=3.9953 ANFIS模型13:Disp功率年-->trn=2.4607,chk=3.3563 ANFIS模型14:Disp重量加速计-->trn=3.6075,chk=4.2318 ANFIS模型15:Disp重量年-->trn=2.5617,chk=3.7866 ANFIS模型16:Disp加速计年-->trn=2.4149,chk=3.2480 ANFIS 17型:重量加速计-->trn=3.7884,chk=4.0480 ANFIS 18型:重量年-->trn=2.4371,chk=3.2852 ANFIS 19型:重量加速计年-->trn=2.7276,chk=3.2580 ANFIS 20型:重量加速计年-->trn=2.3603,chk=2.9152
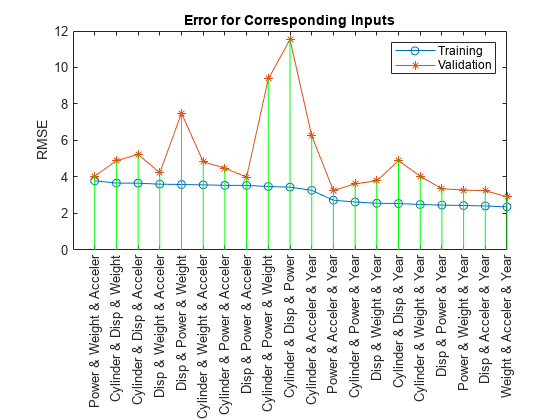
图3:所有三种输入变量组合及其对燃油消耗的影响
该图显示了选择三个输入的结果,其中重量,一年和加速者被选为三个输入变量的最佳组合。但是,最小训练(和检查)误差与最佳两个输入模型相比没有显著降低,这表明新添加的属性加速者没有太多的改进预测。为了更好的推广,我们总是喜欢结构简单的模型。因此,我们将坚持使用两个输入ANFI进行进一步的探索。
然后从原始训练和检查数据集中提取选定的输入属性。
关闭全部的; 新的trn数据=trn数据(:,[输入索引,大小(trn数据,2)]);新的chk数据=chk数据(:,[输入索引,大小(chk数据,2)]);
训练ANFIS模型
功能exhsrch只训练每个ANFIS为一个单一的时期,以便能够快速找到正确的输入。既然输入是固定的,我们可以花更多的时间在ANFIS训练上(100 epoch)。
的根菲斯函数从训练数据生成初始FIS,然后由ANFIS进行微调,生成最终模型。
在fismat=genfis(新数据(:,1:end-1),新数据(:,end));anfisOpt=ANFISOTIONS(“InitialFIS”in_fismat,“EpochNumber”, 100,...“StepSizeDecreaseRate”,0.5,...“StepSizeIncreaseRate”,1.5,...“验证数据”,新数据,...“显示信息”,0,...“DisplayErrorValues”,0,...“DisplayStepSize”,0,...“DisplayFinalResults”,0);[trn_out_fismat,trn_error,步长,chk_out_fismat,chk_error]=...anfis(新trn数据,ANFISOT);
ANFIS在其输出参数列表中返回与训练数据和检查数据相关的误差。误差图提供了训练过程的有用信息。
[a,b]=最小值(chk_误差);绘图(1:100,trn_误差,“g -”, chk_error 1:10 0的r -,b,a,“高”)头衔('训练(绿色)和检查(红色)误差曲线',“字体大小”(10)包含“数字时代”,“字体大小”(10) ylabel“RMS错误”,“字体大小”, 10)

图4:ANFIS训练和错误检查
上图显示了100次ANFIS训练的误差曲线。绿色曲线表示训练误差,红色曲线表示检查误差。最小检查错误发生在约45纪元处,由圆圈表示。请注意,检查误差曲线在50个纪元后上升,表明进一步的训练过度拟合数据,并产生更差的泛化
ANFIS与线性回归
此时,一个很好的练习是使用线性回归模型检查ANFIS模型的性能。
ANFIS预测可通过将其各自的RMSE(均方根)值与检查数据进行比较,与线性回归模型进行比较。
%执行线性回归N=尺寸(trn_数据,1);A=[trn_数据(:,1:6)个(N,1)];B=trn_数据(:,7);coef=A\B;从训练数据中求解回归参数Nc=尺寸(chk_数据,1);A_ck=[chk_data(:,1:6)个(Nc,1)];B_ck=chk_数据(:,7);lr_rmse=标准(A_ck*coef-B_ck)/sqrt(Nc);%打印结果流('\nRMSE against checking data\nANFIS: %1.3f\tLinear Regression: %1.3f\n', lr_rmse);
RMSE对照检查数据ANFIS:2.980线性回归:3.444
可以看出,ANFIS模型优于线性回归模型。
简称ANFIS模型分析
变量chk_out_fismat表示训练过程中检查误差最小时ANFIS模型的快照。模型的输入-输出面如下图所示。
chk_out_fismat.Inputs(1)。Name =“重量”;chk_out_fismat.Inputs(2)。Name =“年”; chk_out_fismat.输出(1).名称=“MPG”;%生成FIS输出曲面图gensurf (chk_out_fismat);

图5:训练FIS的输入-输出曲面
上面显示的输入-输出曲面是一个非线性单调曲面,说明了ANFIS模型将如何响应“权重”和“年份”的变化值。
限制和注意事项
我们可以在曲面的远端角看到一些虚假效果。高架角表示,汽车越重,其气体效率越高。这完全是违反直觉的,这是缺乏数据的直接结果。
绘图(新数据(:,1),新数据(:,2),“波”,...新数据(:,1),新数据(:,2),“rx”)xlabel(“重量”,“字体大小”(10) ylabel“年”,“字体大小”,10)头衔(“培训(o)和检查(x)数据”,“字体大小”, 10)
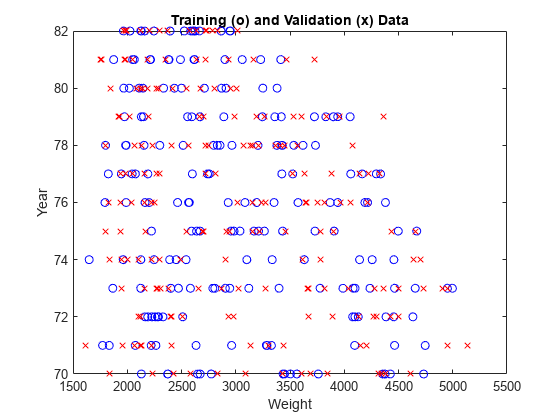
图6:右上角的Weight vs Year图显示缺少数据
上图显示了数据分布。右上角缺少训练数据导致前面提到的伪ANFIS曲面。因此,ANFIS预测应始终考虑数据分布。
另请参阅
相关话题
您还可以从以下列表中选择网站:
