深度学习中的数据布局考虑
当您构建使用生成的CUDA的应用程序时®C ++代码,您必须提供调用生成的代码的CUDA C ++主函数。默认情况下,用于使用源代码,静态库,动态库和可执行文件的代码生成Codegen.命令,GPU编码器™生成示例CUDA c++主文件(main.cu.源文件和主要标题文件例子构建文件夹的子文件夹)。此示例主文件是一个模板,可帮助您将生成的CUDA代码合并到您的应用程序中。示例主函数声明并初始化数据,包括动态分配的数据。它调用入口点函数但不使用入口点函数返回的值。
在为深度卷积神经网络(CNN)生成代码时,代码生成器利用NVIDIA®CUDNN,NVIDIA GPU或ARM的Rensorrt®arm mali gpus的计算库。这些库具有用于保持图像,视频和任何其他数据的输入张量的特定数据布局要求。创建自定义主函数用于构建应用程序时,必须创建输入缓冲区,该缓冲区以这些库的预期的格式为生成的入口点函数提供数据。
CNN的数据布局格式
对于深度卷积神经网络(CNN),4-D张量描述符用于定义具有以下字母的批量的2-D图像格式:
N.- 批量大小C- 特征映射的数量(通道数)H——高度W.- 宽度
显示最常用的4-D张量格式,其中字母以减小的顺序排序。
NCHWNHWC.CHWN
其中,GPU编码器使用NCHW格式(默认情况下列 - 主要布局)。使用行主要布局通过-Rowmajor.选择Codegen.命令。或者,通过修改cfg.rowmajor.参数在代码生成配置对象中。
例如,考虑一批具有以下维度的图像:n = 1那C = 3.那H = 5那W = 4.。如果图像像素元素由一系列整数表示,则输入图像可以被视为如下。
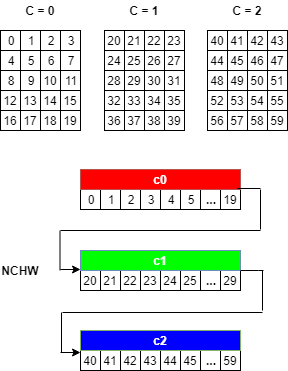
在主函数中创建输入缓冲区时,4-D图像在内存中布置出来NCHW格式为:
从第一频道开始(
C = 0.),元素以行主要顺序连续布置。继续使用第二和后续渠道,直到所有渠道的元素都被布置出来。
继续到下一个批处理(如果
N > 1)。
LSTM的数据布局格式
长期内记忆(LSTM)网络是一种复发性神经网络(RNN),可以在序列数据的时间步长之间学习长期依赖性。对于LSTM,可以使用以下字母描述数据布局格式:
N.- 批量大小S.- 序列长度(时间次数)D.- 一个输入序列中的单位数
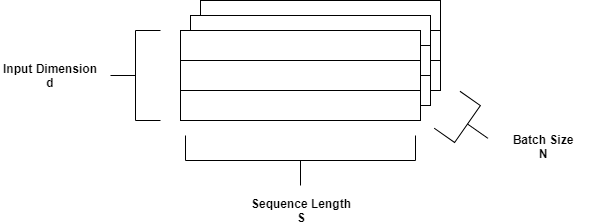
对于LSTM,GPU编码器使用SND.默认格式。
也可以看看
职能
对象
Coder.gpuconfig.|coder.codeConfig|Coder.embeddedCodeConfig|coder.gpuenvconfig.|编码器。CuDNNConfig|编码器。TensorRTConfig
相关的话题
你也可以从以下列表中选择一个网站:
