分散-聚集类型操作的内核
GPU编码器™也支持减少的概念-万博1manbetx循环迭代必须是独立的规则的一个重要例外。reduce变量累积的值依赖于所有的迭代,但与迭代顺序无关。约简变量出现在赋值语句的两边,例如在求和、点积和排序中。下面的示例展示了reduction变量的典型用法x:
x =...;x的一些初始化为I = 1:n x = x + d(I);结束
的变量x在每次迭代中,在进入循环之前或从循环的前一次迭代中获取其值。由于顺序执行中的依赖链,这种串行顺序类型的实现不适合并行执行。另一种方法是采用基于二叉树的方法。
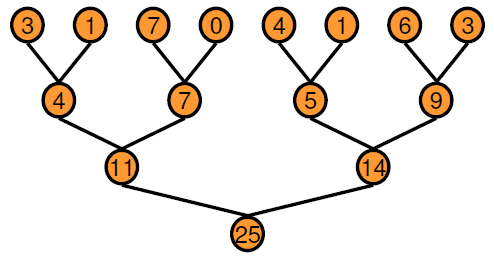
在基于树的方法中,您可以通过一定数量的传递并行地执行树的每个水平层。与顺序执行相比,二叉树确实需要更多的内存,因为每次传递都需要一个临时值数组作为输出。您获得的性能好处远远超过增加内存使用的成本。GPU编码器通过使用这种基于树的方法创建约简核,其中每个线程块减少数组的一部分。并行减少需要线程块之间的部分结果数据交换。在旧CUDA®在设备上,这个数据交换是通过使用共享内存和线程同步来实现的。从Kepler GPU架构开始,CUDA提供了shuffle (shfl)指令和快速设备内存原子操作,使减少甚至更快。GPU编码器创建的还原内核使用shfl_down在线程的一个经线(32个线程)上进行简化的指令。然后,每个warp的第一个线程使用原子操作指令来更新减少的值。
有关说明的更多信息,请参阅NVIDIA®文档。
矢量和例子
这个例子展示了如何使用GPU编码器创建CUDA缩减类型的内核。假设你想要创建一个向量v并计算其元素之和。你可以用MATLAB来实现这个例子®函数。
函数s = VecSum(v) s = 0;为I = 1:length(v) s = s + v(I)结束结束
为内核创建准备vecSum
GPU编码器不需要特殊的pragma来推断约简核。在本例中,使用coder.gpu.kernelfunpragma生成CUDA约简核。使用修改后的VecSum函数。
函数s = VecSum (v)% # codegens = 0;coder.gpu.kernelfun ();为I = 1:length(v) s = s + v(I)结束结束
生成的CUDA代码
当您使用GPU Coder应用程序或从命令行生成CUDA代码时,GPU Coder创建一个执行矢量和计算的单个内核。下面是一个片段vecSum_kernel1.
static __global__ __launch_bounds__(512, 1) void vecSum_kernel1(const real_T *v, real_T *s) {uint32_T threaddid;uint32_T threadStride;uint32_T thdBlkId;uint32_T idx;real_T tmpRed;;;thdBlkId = (threadIdx。z * blockDim。x * blockDim。y + threadIdx。y * blockDim.x) + threadadidx .x; threadId = ((gridDim.x * gridDim.y * blockIdx.z + gridDim.x * blockIdx.y) + blockIdx.x) * (blockDim.x * blockDim.y * blockDim.z) + thdBlkId; threadStride = gridDim.x * blockDim.x * (gridDim.y * blockDim.y) * (gridDim.z * blockDim.z); if (!((int32_T)threadId >= 512)) { tmpRed = 0.0; for (idx = threadId; threadStride < 0U ? idx >= 511U : idx <= 511U; idx += threadStride) { tmpRed += v[idx]; } tmpRed = workGroupReduction1(tmpRed, 0.0); if (thdBlkId == 0U) { atomicOp1(s, tmpRed); } } }
在调用之前VecSum_kernel1,两个cudaMemcpy调用传递矢量v和标量年代从主机到设备。内核有一个线程块,每个线程块包含512个线程,与输入向量的大小一致。第三个cudaMemcpy调用将计算结果复制回主机。下面是main函数的一个片段。
cudaMemcpy((void *)gpu_v, (void *)v, 4096ULL, cudaMemcpyHostToDevice);cudaMemcpy((void *)gpu_s, (void *)&s, 8ULL, cudaMemcpyHostToDevice);VecSum_kernel1 < < < dim3 (1 u, 1 u, 1 u), dim3 (512 u, 1 u, 1 u) > > > (gpu_v gpu_s);cudaMemcpy(&s, gpu_s, 8U, cudaMemcpyDeviceToHost);
请注意
为了更好的性能,GPU编码器优先考虑并行内核。如果你的算法在并行循环中包含约简,GPU编码器将其推断为常规循环并为其生成内核。
对GPU的1-D还原操作
你可以使用gpucoder.reduce函数生成CUDA代码,在GPU上执行高效的一维缩减操作。生成的代码使用CUDA shuffle intrinsic来实现reduce操作。
例如,要找到总和和马克斯数组元素一个:
函数s = myReduce(A) s = gpucoder. txt减少(A, {@mysum, @mymax});mysum(a, b) = mysum(a, b);函数c = mymax(a, b);结束
gpucoder.reduce功能有以下要求:
输入必须是数字或逻辑数据类型。
通过@handle传递的函数必须是一个二进制函数,接受两个输入并返回一个输出。输入和输出必须是相同的数据类型。
这个函数必须是交换的和结合的。
请注意
对于一些整数数据类型的输入,为gpucoder.reduce函数可能包含达到饱和的中间计算。在这种情况下,生成的代码的结果可能与MATLAB的仿真结果不匹配。
另请参阅
coder.gpu.constantMemory|coder.gpu.kernel|coder.gpu.kernelfun|gpucoder.matrixMatrixKernel|gpucoder.reduce|gpucoder.stencilKernel
相关的话题
你也可以从以下列表中选择一个网站:
