使用MEX访问高级CUDA功能
这个例子演示了如何使用MEX文件访问GPU的高级特性。它建立在例子的基础上模板对GPU的操作.前面的例子使用了Conway的“Game of Life”来演示如何使用在GPU上运行的MATLAB®代码执行模板操作。现在的例子演示了如何使用GPU的两个高级特性进一步提高模板操作的性能:共享内存和纹理内存。您可以通过在MEX文件中编写自己的CUDA代码并从MATLAB调用MEX文件来实现这一点。你可以在MEX文件中找到关于GPU使用的介绍运行包含CUDA代码的MEX函数.
如前一示例中所定义,在“模具操作”中,输出数组的每个元素都依赖于输入数组的一个小区域。示例包括有限差分法、卷积法、中值滤波法和有限元法。如果我们假设模具操作是我们工作流程的一个关键部分,我们可以花时间将其转换为手写的CUDA内核,以期从GPU中获得最大的好处。本例使用Conway的“生命游戏”作为模板操作,并将计算移动到MEX文件中。
“生活游戏”遵循一些简单的规则:
单元格按2D网格排列
在每一步中,每个细胞的命运都是由它最邻近的八个细胞的活力决定的
任何有三个邻居的细胞在下一步就会有生命
一个有两个邻居的活细胞在下一步仍然是活的
所有其他单元格(包括有三个以上邻居的单元格)都会在下一步死亡或保持空状态
因此,本例中的“模具”是每个元素周围的3x3区域。欲知详情,,查看paralleldemo_gpu_stencil的代码.
这个例子是一个允许我们使用子函数的函数:
函数paralleldemo_gpu_mexstencil()
生成随机初始总体
在一个2D网格上创建一个初始的细胞群,其中大约有25%的位置是活的。
gridSize = 500;numGenerations = 100;initialGrid = (rand(gridSize,gridSize) > .75);持有从imagesc(initialGrid);彩色地图([1;0.5 0]);标题(“初始网格”);

在MATLAB中创建一个基准GPU版本
为了获得性能基线,我们从第一个实现开始MATLAB实验.这个版本可以在GPU上运行,只要确保初始人口是在使用的GPU上gpuArray.
函数updateGrid(X, N) p = [1 1:N-1];q = [2:N N];数一下八个邻居中有多少人还活着。邻居=X(:,p)+X(:,q)+X(p,:)+X(q,:)+...X(p,p) + X(q,q) + X(p,q) + X(q,p);一个活的细胞有两个活的邻居,或者任何有三个活着的邻居,是活着的下一步。。X = (X & (neighbors == 2))) | (neighbors == 3);结束currentGrid = gpuArray (initialGrid);%循环每一代更新网格并显示它为generation=1:numGenerations currentGrid=updateGrid(currentGrid,gridSize);imagesc(currentGrid);title(num2str(generation));drawnow;结束

现在重新运行游戏,测量每代人需要多长时间。
这个函数定义了调用每代的外部循环,没有%做显示。函数网格= callUpdateGrid(网格、gridSize N)为gen=1:N grid=updateGrid(grid,gridSize);结束结束gpuInitialGrid=gpuArray(initialGrid);%保留此结果以验证以下每个版本的正确性。expectedResult = callUpdateGrid(gpuInitialGrid, gridSize, numGenerations);gpuBuiltinsTime = gputimeit(@() callUpdateGrid(gpuInitialGrid),...gridSize numGenerations));fprintf(“在GPU上的平均时间:%2.3fms /代\n”,...1000 * gpuBuiltinsTime / numGenerations);
GPU上的平均时间:每代1.528毫秒
创建使用共享内存的MEX版本
在编写CUDA内核版本的模具操作时,我们必须将输入数据拆分为块,每个线程块都可以在这些块上操作。块中的每个线程将读取块中其他线程也需要的数据。减少读取操作次数的一种方法是在处理之前将所需的输入数据复制到共享内存中。此副本必须包含一些相邻图元,以便正确计算块边。对于生命的游戏,我们的模板只是一个3x3平方的元素,我们需要一个元素边界。例如,对于使用3x3块处理的9x9网格,第五个块将在高亮显示的区域上操作,其中黄色元素是它还必须读取的“光环”。
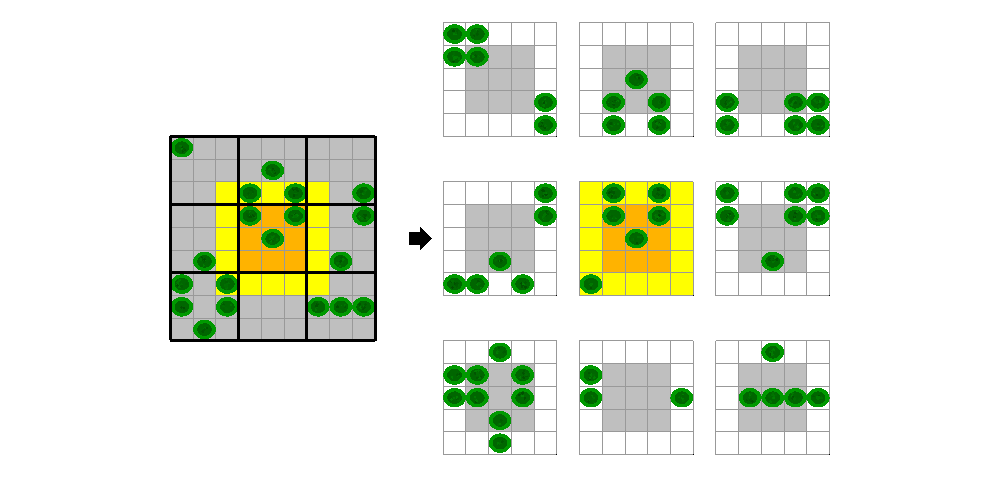
我们已将说明此方法的CUDA代码放入文件中pctdemo_life_cuda_shmem.cu.本文件中的CUDA设备功能操作如下:
所有线程都将输入网格的相关部分复制到共享内存中,包括晕轮。
线程彼此同步以确保共享内存准备就绪。
适合于输出网格的线程执行Game of Life计算。
这个文件中的主机代码使用CUDA运行时API,每一代调用一次CUDA设备函数。它为输入和输出使用两个不同的可写缓冲区。在每次迭代时,mex文件交换输入和输出指针,因此不需要复制。
为了从MATLAB中调用该函数,我们需要一个MEX网关来打开MATLAB中的输入数组,在GPU上构建一个工作空间,并返回输出。可以在文件中找到MEX网关函数pctdemo_life_mex_shmem.cpp.
在调用mex文件之前,必须使用mexcuda,需要安装nvcc编译器。可以使用如下命令将这两个文件编译为单个MEX函数
mexcuda-输出pctdemo\U life\U mex\U shmem…pctdemo\U life\U cuda\U shmem.cu pctdemo\U life\U mex\U shmem.cpp
将生成一个名为pctdemo_life_mex_shmem.
%使用带有共享内存的MEX文件计算输出值。的%初始输入值被复制到MEX文件中的GPU。grid=pctdemo\u life\u mex\u shmem(初始网格,numGenerations);gpuMexTime=gputimeit(@()pctdemo\u life\u mex\u shmem)(初始网格,...numGenerations));%打印平均计算时间,并检查结果是否不变。fprintf(每一代的平均时间%2.3fms (%1.1fx快),...1000 * gpuMexTime / numGenerations gpuBuiltinsTime / gpuMexTime);断言(isequal(网格、expectedResult));
每代平均时间为0.055ms(快27.7倍)。
创建一个使用纹理内存的MEX版本
处理重复读取操作问题的第二种方法是使用GPU的纹理内存。当多个线程访问重叠的二维数据时,纹理访问以一种试图提供良好性能的方式进行缓存。这正是我们在模具操作中使用的访问模式。
有两个CUDA API可用于读取纹理内存。我们选择使用CUDA纹理参考API,该API在所有CUDA设备上都受支持。绑定到纹理的数组中可以包含的最大元素数为万博1manbetx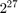 ,所以如果输入有更多的元素,纹理方法将不起作用。
,所以如果输入有更多的元素,纹理方法将不起作用。
说明这种方法的CUDA代码在pctdemo_life_cuda_texture.cu. 与上一版本一样,此文件包含主机代码和设备代码。此文件的三个功能允许在设备功能中使用纹理内存。
纹理变量在mex文件的顶部声明。
CUDA设备函数从纹理引用获取输入。
mex -文件将纹理引用绑定到输入缓冲区。
在这个文件中,CUDA设备函数比以前简单。它只需要执行生命游戏的计算。不需要复制到共享内存或同步线程。
与共享内存版本一样,主机代码使用CUDA运行时API为每一代调用CUDA设备函数一次。它再次为输入和输出使用两个可写缓冲区,并在每次迭代时交换它们的指针。在每次调用设备函数之前,它将纹理引用绑定到适当的缓冲区。在设备函数已执行,它将解除纹理引用的绑定。
这个版本有一个MEX网关文件,pctdemo_life_mex_texture.cpp它负责输入和输出数组以及工作空间分配。可以使用如下命令将这些文件构建到单个MEX文件中。
输出pctdemo_life_mex_texture…pctdemo_life_cuda_texture.cupctdemo_life_mex_texture.cpp
%使用带有纹理的MEX文件计算输出值。grid=pctdemo\u life\u mex\u纹理(initialGrid,numGenerations);gpuTexMexTime=gputimeit(@()pctdemo\u life\u mex\u纹理(initialGrid,...numGenerations));%打印平均计算时间,并检查结果是否不变。fprintf(每一代的平均时间%2.3fms (%1.1fx快),...1000 * gpuTexMexTime / numGenerations gpuBuiltinsTime / gpuTexMexTime);断言(isequal(网格、expectedResult));
每一代平均耗时0.025ms(快61.5倍)。
结论
在这个例子中,我们展示了两种不同的方法来处理模板操作的复制输入:显式地将块复制到共享内存中,或者利用GPU的纹理缓存。最好的方法将取决于模板的大小、重叠区域的大小以及GPU的硬件生成。重要的一点是,您可以将这些方法与MATLAB代码结合使用来优化应用程序。
fprintf('第一个版本使用gpuArray: %2.3fms每代\n',...1000 * gpuBuiltinsTime / numGenerations);流([使用共享内存的MEX:每代%2.3fms,...“(%1.1fx更快)。\n”],1000*gpuMexTime/numGenerations,...gpuBuiltinsTime / gpuMexTime);流(['带有纹理内存的MEX:每代%2.3fms '...“(%1.1fx更快)。\n”],1000*gpuTexMexTime/numGenerations,...gpuBuiltinsTime / gpuTexMexTime);
使用gpuArray的第一个版本:每代1.528ms。使用共享内存的MEX:每代0.055ms(快27.7x)。使用纹理内存的MEX:每代0.025ms(快61.5x)。
结束
你也可以从以下列表中选择一个网站: