基准\ b
此示例显示如何在群集中求解线性系统。MATLAB®代码用于解决x在A * x =是非常简单的。最常见的是使用矩阵左除法,也称为mldivide或反斜杠操作符(\)来计算x(即,x = A \ b)。然而,基准测试矩阵对群体的性能并不直接。
基准测试最具挑战性的方面之一是避免陷入寻找代表系统整体性能的单个数字的陷阱。我们将查看性能曲线,这可能帮助您确定集群上的性能瓶颈,甚至可能帮助您了解如何对代码进行基准测试,并能够从结果中得出有意义的结论。
相关例子:
此示例中显示的代码可以在此功能中找到:
函数结果= paralleldemo_backslash_bench (memoryPerWorker)
为群集选择适当的矩阵大小非常重要。我们可以通过指定每个工人可用的GB中的系统内存量作为此示例功能的输入来执行此操作。默认值非常保守;您应该指定适合您系统的值。
如果nargin == 0 memoryPerWorker = 8.00;%在GB%警告('pctexample:backslashbench:backslashbenchusingdefaultmemory',...%['每个worker可用的系统内存数量',…%的未指定。使用保守默认值',…%的%。每个工人2f g。'], memoryPerWorker);结尾
避免开销
为了准确衡量我们解决线性系统的能力,我们需要删除任何可能的开销来源。这包括获取当前并行池并暂时禁用死锁检测功能。
p =质量;如果isempty (p)错误('PCTExample:Backslashbench:poolclosed',...[“此示例需要并行池。'...使用parpool命令或set命令手动启动一个pool..."你的平行偏好自动启动池"]);结尾poolsize = p.numworkers;pctRunOnAll'Mpisettings('''''''''''''');'
使用“bigMJS”配置文件启动并行池(parpool)…连接到12个工人。
基准测试函数
我们想基准矩阵左除法(\),而不是进入一个成本spmd块、创建矩阵或其他参数所需的时间。因此,我们将数据生成与线性系统的求解分离开来,只测量后者所需的时间。我们使用二维块循环共分配器生成输入数据,因为这是求解线性系统的最有效的分配方案。我们的基准测试包括测量所有工人完成线性系统求解所需的时间A * x =.同样,我们试图消除任何可能的开销来源。
函数[a,b] = getData(n)fprintf(“创建大小为%d-by-%d.\n的矩阵”n, n);spmd%使用通常提供最佳性能的译码员%用于求解线性方程组。codistr = codistributor2dbc (codistributor2dbc.defaultLabGrid,...codistributor2dbc.defaultBlockSize,...'col');一个= codistributed。兰特(n, n, codistr);b = codistributed。兰特(n, 1, codistr);结尾结尾函数time = timesresolve (A, b)spmdtic;x = a \ b;%#ok不需要x的值。 时间= gop(@max, toc);%全部完成的时间。结尾时间= {1};结尾
选择问题的大小
与许多其他并行算法一样,并行求解线性系统的性能在很大程度上取决于矩阵的大小。我们的先天的因此,期望计算是:
对于小矩阵有些低效
非常有效地对大矩阵
如果矩阵太大以适合系统存储器,并且操作系统启动将存储器转换为磁盘
因此,对于多种不同矩阵大小的计算是值得注意的,以了解在这种情况下对“小”,“大”和“太大”均值的理解。根据之前的实验,我们期待:
“太小”的矩阵大小不能达到1000 × 1000
“大”矩阵占用每个工人可用内存的略小于45%
“太大”矩阵占用50%或更多的系统内存
这些都是启发式的,精确的值可能会在不同的版本之间改变。因此,我们使用跨越整个范围的矩阵大小来验证预期的性能是很重要的。
注意,通过根据工人的数量改变问题的大小,我们采用了弱缩放。其他基准测试的例子,例如使用21点对PARFOR进行简单的基准测试和对集群上的独立作业进行基准测试,也采用弱缩放。由于这些示例基准任务并行计算,它们的弱缩放包括使与工人数量成比例的迭代次数。然而,此示例是基准测试数据并行计算,因此我们将矩阵的大小限制与工人数量相关联。
声明矩阵大小,范围从1000 × 1000到系统的45%每个worker可用的内存%。maxmusageperworker = 0.45 * Moderperworker * 1024 ^ 3;%的字节。maxMatSize =圆(√maxMemUsagePerWorker * poolSize / 8));= round(linspace(1000, maxMatSize, 5));
比较性能:Gigaflops
我们使用每秒浮点运算数作为性能的衡量标准,因为这允许我们比较不同矩阵大小和不同工人数量下算法的性能。如果我们成功地测试了矩阵左除法在足够宽的矩阵大小范围内的性能,我们期望性能图看起来类似于以下:

通过生成这样的图表,我们可以回答以下问题:
最小的矩阵是否太小以至于我们的性能很差?
当矩阵如此之大时,我们是否看到了性能下降,它占据了总系统内存的45%?
对于给定数量的员工,我们所能达到的最佳绩效是多少?
在哪个矩阵尺寸中,16个工人比8个工人表现更好?
系统内存是否限制了峰值性能?
给定矩阵大小,基准函数创建矩阵一个和右侧b一次,然后解一个\ b多次来精确测量所需的时间。我们使用HPC Challenge的浮点运算计数,因此对于一个n × n矩阵,我们将浮点运算计数为2/3 * n ^ 3 + 3/2 * n ^ 2.
函数gflops = benchFcn(n) numrep = 3;[A, b] = getData(n);时间=正;我们解了线性系统几次,并计算了千兆浮点运算%基于最佳时间。为了itr = 1: numrep tcurr = timeSolve(A, b);如果Itr == 1 fprintf(执行时间:% f ', tcurr);别的流(”,% f ', tcurr);结尾Time = min(tcurr, Time);结尾流(' \ n ');= 2/3*n^3 + 3/2*n^2;gflops =失败/时间/ 1 e9;结尾
执行标准
完成所有设置后,执行基准测试就很简单了。然而,计算可能需要很长时间才能完成,因此我们在完成对每个矩阵大小的基准测试时打印一些中间状态信息。
fprintf(['具有%D不同矩阵大小的启动基准范围范围\ n'...%d-by-%d.\n `],...长度(迷水),Matsize(1),Matsize(1),Matsize(END),...matSize(结束));gflops = 0(大小(matSize));为了i = 1:length(matSize) gflops(i) = benchFcn(matSize(i));流(“吉拍:% f \ n \ n”gflops(我));结尾结果。matSize = matSize;结果。gflops = gflops;
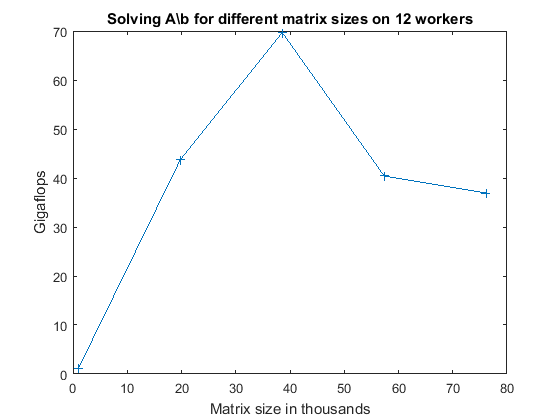
从5个不同的矩阵大小开始基准测试,从1000-by-1000到76146-by-76146。创建一个大小为1000 × 1000的矩阵。分析和传送文件给工人…完成。执行时间:1.038931,0.592114,0.575135 Gigaflops: 1.161756创建大小为19787 × 19787的矩阵。执行时间:119.402579,118.087116,119.323904 Gigaflops: 43.741681执行时间:552.256063,549.088060,555.753578 Gigaflops: 69.685485创建大小为57360 × 57360的矩阵。执行时间:3580.232186,3726.588242,3113.261810 Gigaflops: 40.414533执行时间:9261.720799,9099.777287,7968.750495 Gigaflops: 36.937936
绘制性能
现在我们可以绘制结果,并与上面所示的预期图进行比较。
无花果=图;ax =轴('父母'图);情节(ax, matSize / 1000 gflops);行= ax.Children;行。标志=“+”;ylabel (ax,“吉拍”)包含(ax,“矩阵大小以千为单位”) titleStr = sprintf(['求解不同矩阵大小的A\\b '...' % d工人],池化);标题(AX,Tittestr,“翻译”,'没有任何');
如果基准测试的结果没有你预期的那么好,这里有一些事情需要考虑:
基础实施是使用缩放标签,其具有高性能的经过验证的声誉。因此,算法或图书馆非常不可能导致效率低下,而是如下所示的使用方式。
如果矩阵对于您的集群来说太小或太大,那么结果的性能就会很差。
如果网络通信缓慢,性能将受到严重影响。
如果cpu和网络通信都非常快,但内存数量有限,那么可能无法使用足够大的矩阵进行基准测试,以充分利用可用的cpu和网络带宽。
为了最终的性能,重要的是使用为您的网络设置量身定制的MPI版本,并让工作人员以这样一种方式运行,即尽可能多的通信通过共享内存进行。但是,解释如何识别和解决这些类型的问题超出了本示例的范围。
比较不同数量的工人
现在,我们看看如何通过查看使用不同数量的工人运行这个示例所获得的数据来比较不同数量的工人。这个数据是在与上面的不同的集群上获得的。
其他例子如对集群上的独立作业进行基准测试解释说,当对不同数量的工人进行并行算法的基准测试时,通常采用弱扩展。也就是说,当我们增加工人的数量时,问题的规模也相应增加。在矩阵左除法的情况下,我们必须格外小心,因为除法的性能很大程度上取决于矩阵的大小。下面的代码为我们测试的所有矩阵大小和所有不同数量的工人创建了一个千兆浮点运算的性能图表,因为这给了我们矩阵左除法的性能特征的最详细的图片在这个特定的集群上.
s =负载('pctdemo_data_backslash.mat',“workers4”,“workers8”,...'工人16',“workers32”,“workers64”);无花果=图;ax =轴('父母'图);情节(ax, s.workers4.matSize。s.workers4.gflops / 1000,...s.workers8.matSize。s.workers8.gflops / 1000,...s.workers16.matSize。s.workers16.gflops / 1000,...S.Workers32.Matsize./1000,S.Workers32.gflops,...s.workers64.matSize。/ 1000, s.workers64.gflops);行= ax.Children;集(线,{“标记”}, {“+”;“o”;'v';“。”;‘*’});ylabel (ax,“吉拍”)包含(ax,“矩阵大小以千为单位”)标题(ax,...“不同工人数量下求解A\\b的比较数据”);传奇(“4个工人,“8工人,'16工人',“32工人,...64年的工人,“位置”,“西北”);

我们在上面看图表时,我们注意到的第一件事是64名工人允许我们解决比只有4名工人的更大的方程线性系统。此外,我们还可以看到,即使人们可以在4名工人上使用大小60,000乘以60,000的矩阵,我们将获得大约10个Gigaflops的性能。因此,即使这位工人有足够的内存来解决这么大的问题,64名工人仍然可能会大大超越。
看看4个工人的曲线斜率,我们可以看到,在三个最大的矩阵大小之间,只有适度的性能增长。将此与之前的预期性能图进行比较一个\ b对于不同的矩阵尺寸,我们得出的结论是,对于矩阵尺寸为7772 × 7772的4个工人,我们非常接近于达到最佳性能。
查看8和16个worker的曲线,我们可以看到最大的矩阵大小的性能下降,这表明我们接近或已经耗尽了可用的系统内存。然而,我们看到,在第二大和第三大矩阵大小之间的性能增加是非常温和的,表明某种稳定性。因此,我们推测,当使用8或16个工作人员时,如果我们增加系统内存并使用更大的矩阵尺寸进行测试,我们很可能不会看到Gigaflops的显著增加。
看着32和64名工人的曲线,我们看到第二大矩阵尺寸和第三大矩阵尺寸之间存在显着的性能。对于64名工人,两种最大矩阵大小之间也存在显着的性能。因此,我们猜测我们在达到峰值性能之前,我们在32和64名工人用完了系统内存。如果这是正确的,则将更多内存添加到计算机允许我们解决更大的问题并在那些较大的矩阵大小上执行更好。
加速
用反斜杠等线性代数算法来衡量加速的传统方法是比较峰值性能。因此,我们计算出每个工作人员达到的最大Gigaflops数。
peakPerf = [max(s.workers8.gflops), max(s.workers8.gflops),...马克斯(s.workers16.gflops)、马克斯(s.workers32.gflops),...马克斯(s.workers64.gflops)];disp (“4-64个工人每秒千兆浮点运算的峰值性能”)DISP(峰值)DISP('从4名工人到8,16,32和64名工人时加速:')DISP(峰值(2:结束)/峰值(1))
4-64 workers: 10.9319 23.2508 40.7157 73.5109 147.0693从4 workers到8、16、32和64 workers: 2.1269 3.7245 6.7244 13.4532
因此,我们得出结论,当工人数量增加16倍时,我们得到大约13.5的加速,从4个工人增加到64个。如上所述,性能图表明,通过增加集群计算机上的系统内存,我们可以提高64个worker上的性能(从而进一步提高加速)。
群集使用
使用16双处理器,Octa-Core计算机生成此数据,每个计算机具有64 GB内存,与千兆以太网连接。使用4名工人时,它们都在一台计算机上。我们使用了2台工人的2台计算机,为16台工人等4台计算机等。
重新启用死锁检测
现在我们已经结束了基准测试,我们可以安全地在当前并行池中重新启用死锁检测。
pctRunOnAll“mpiSettings(“DeadlockDetection”、“on”);”
结尾
ans = struct with fields: matSize: [1000 19787 38573 57360 76146] gflops: [1.1618 43.7417 69.6855 40.4145 36.9379]
你也可以从以下列表中选择一个网站: