阐述GPU计算的三种方法:Mandelbrot集
这个例子展示了如何调整你的MATLAB®代码来使用GPU计算Mandelbrot集。
从一个现有的算法开始,这个例子展示了如何使用并行计算工具箱™调整你的代码,以三种方式利用GPU硬件:
使用现有算法,但GPU数据作为输入
使用
arrayfun在每个元素上独立执行算法使用MATLAB/CUDA接口运行一些现有的CUDA/ c++代码
设置
下面的值指定了Mandelbrot集的一个高度放大的部分,该部分位于主心脏线和它左边的p/q灯泡之间的山谷。
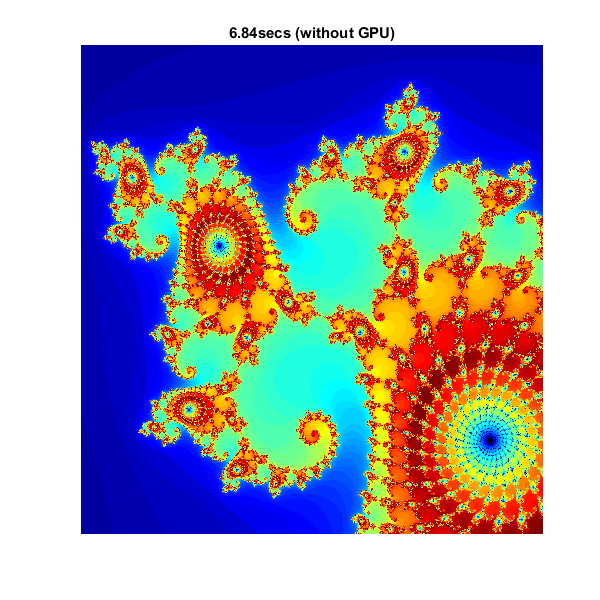
在这些极限之间创建一个1000x1000的实部(X)和虚部(Y)网格,并且在每个网格位置迭代Mandelbrot算法。对于这个特定的位置,500次迭代就足够完全渲染图像了。
maxIterations = 500;gridSize = 1000;Xlim = [-0.748766713922161, -0.748766707771757];Ylim = [0.123640844894862, 0.123640851045266];
MATLAB中的Mandelbrot集
下面是使用标准MATLAB命令在CPU上运行的Mandelbrot Set的实现。这是基于Cleve Moler's中提供的代码《MATLAB实验》电子书。
这个计算是向量化的,因此每个位置都是一次更新的。
%设置T = tic();x = linspace(xlim(1), xlim(2), gridSize);y = linspace(ylim(1), ylim(2), gridSize);[xGrid,yGrid] = meshgrid(x, y);z0 = xGrid + 1i*yGrid;Count = ones(size(z0));%计算Z = z0;为n = 0:maxIterations z = z.*z + z0;Inside = abs(z)<=2;计数=计数+内部;结束Count = log(Count);%显示cpuTime = toc(t);FIG = gcf;fig.Position = [200 200 600 600];Imagesc (x, y, count);Colormap ([jet();flipud(jet());0 0 0]);轴从标题(sprintf ('%1.2fsecs(不含GPU)', cpuTime));
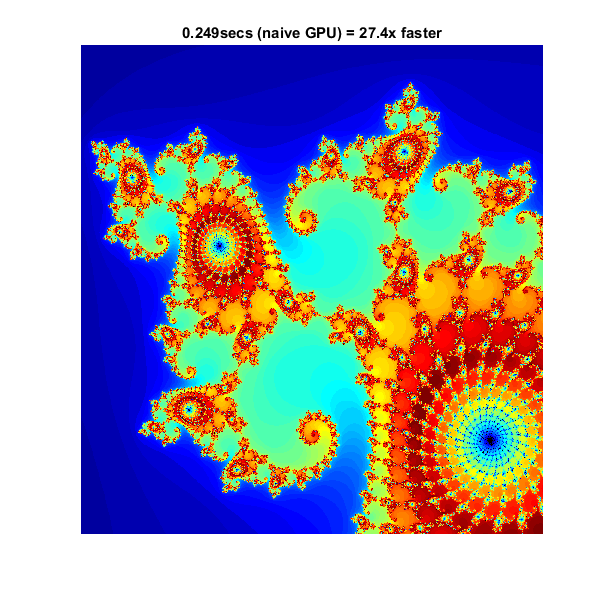
使用gpuArray
当MATLAB在GPU上遇到数据时,对该数据的计算将在GPU上执行。类gpuArray提供了可用于创建数据数组的许多函数的GPU版本,包括linspace,logspace,meshgrid这里需要的函数。类似地,数数组使用函数直接在GPU上初始化的.
有了这些数据初始化的改变,计算现在将在GPU上执行:
%设置T = tic();x = gpuArray。linspace(xlim(1), xlim(2), gridSize ); y = gpuArray.linspace( ylim(1), ylim(2), gridSize ); [xGrid,yGrid] = meshgrid( x, y ); z0 = complex( xGrid, yGrid ); count = ones( size(z0),“gpuArray”);%计算Z = z0;为n = 0:maxIterations z = z.*z + z0;Inside = abs(z)<=2;计数=计数+内部;结束Count = log(Count);%显示计数=收集(计数);从GPU取回数据naiveGPUTime = toc(t);Imagesc (x, y,计数)轴从标题(sprintf ('%1.3fsecs(原生GPU) = %1.1fx更快',...naiveGPUTime, cpuTime/naiveGPUTime))
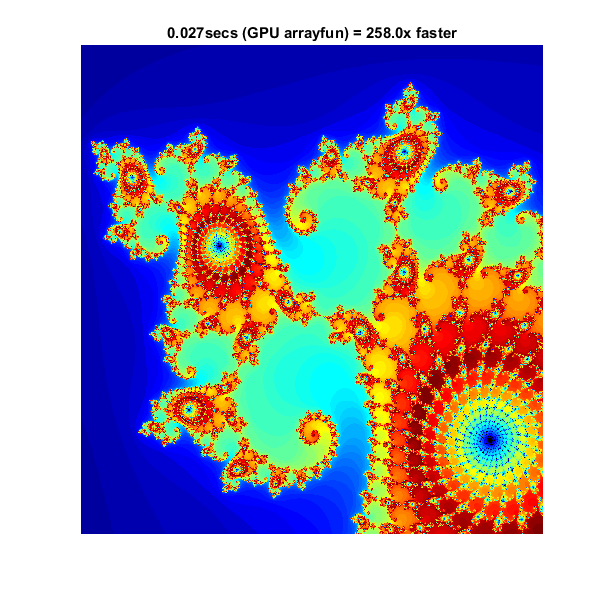
Element-wise操作
注意,算法对输入的每个元素都是平等的,我们可以将代码放在一个助手函数中,并使用它来调用它arrayfun.对于GPU阵列输入,使用的函数arrayfun被编译成原生GPU代码。在本例中,我们将循环放入pctdemo_processMandelbrotElement.m:
函数计数= pctdemo_processMandelbrotElement(x0,y0,maxIterations) z0 = complex(x0,y0);Z = z0;Count = 1;while (count <= maxIterations) && (abs(z) <= 2) count = count + 1;Z = Z * Z + z0;结束计数= log(count);
注意,这里引入了一个早期中止,因为这个函数只处理单个元素。对于Mandelbrot Set的大多数视图,大量的元素很早就停止了,这可以节省大量的处理。的为循环也被替换为而循环,因为它们通常更有效率。这个函数没有提到GPU,也没有使用特定于GPU的特性——它是标准的MATLAB代码。
使用arrayfun这意味着我们不再需要调用成千上万的GPU优化操作(每次迭代至少6次),而是只需调用一次并行GPU操作即可完成整个计算。这大大降低了开销。
%设置T = tic();x = gpuArray。linspace(xlim(1), xlim(2), gridSize ); y = gpuArray.linspace( ylim(1), ylim(2), gridSize ); [xGrid,yGrid] = meshgrid( x, y );%计算count = arrayfun(@pctdemo_processMandelbrotElement,...xGrid, yGrid, maxIterations);%显示计数=收集(计数);从GPU取回数据gpuArrayfunTime = toc(t);Imagesc (x, y,计数)轴从标题(sprintf ('%1.3fsecs (GPU arrayfun) = %1.1fx更快',...gpuArrayfunTime, cpuTime/gpuArrayfunTime));

使用CUDA
在MATLAB实验通过将基本算法转换为C-Mex函数来提高性能。如果你愿意在C/ c++中做一些工作,那么你可以使用并行计算工具箱使用MATLAB数据调用预先编写的CUDA内核。你用parallel.gpu.CUDAKernel特性。
一个CUDA/ c++实现的元素处理算法已手写在pctdemo_processMandelbrotElement.cu:然后必须使用nVidia的NVCC编译器手动编译以生成程序集级pctdemo_processMandelbrotElement.ptx(.ptx代表“并行线程执行语言”)。
CUDA/ c++代码比我们目前看到的MATLAB版本要复杂一些,因为c++中缺少复数。但是,算法的本质没有改变:
__device__ unsigned int doIterations(double const realPart0, double const imagPart0, unsigned int const max){//初始化:z = z0 double realPart = realPart0;double imagPart = imagPart0;Unsigned int count = 0;//循环直到转义while ((count <= max) && ((realPart*realPart + imagPart*imagPart) <= 4.0)) {++count;//更新:z = z*z + z0;double const oldRealPart = realPart;realPart = realPart*realPart - imagPart*imagPart + realPart0;imagPart = 2.0*oldRealPart*imagPart + imagPart0;}返回计数;}
一个GPU线程需要在Mandelbrot集中定位,线程被分组成块。内核指示了线程块的大小,在下面的代码中,我们使用它来计算所需的线程块的数量。这就变成了GridSize.
加载内核cudaFilename =“pctdemo_processMandelbrotElement.cu”;ptxFilename = [“pctdemo_processMandelbrotElement”。parallel.gpu.ptxext);Kernel = parallel.gpu。CUDAKernel(ptxFilename, cudaFilename);%设置T = tic();x = gpuArray。linspace(xlim(1), xlim(2), gridSize ); y = gpuArray.linspace( ylim(1), ylim(2), gridSize ); [xGrid,yGrid] = meshgrid( x, y );确保我们有足够的积木覆盖所有的位置。numElements = numel(xGrid);内核。ThreadBlockSize = [kernel.MaxThreadsPerBlock,1,1];内核。GridSize = [ceil(numElements/kernel.MaxThreadsPerBlock),1];调用内核count = 0 (size(xGrid),“gpuArray”);count = feval(内核,计数,xGrid, yGrid, maxIterations, numElements);%显示计数=收集(计数);从GPU取回数据gpuCUDAKernelTime = toc(t);Imagesc (x, y,计数)轴从标题(sprintf ('%1.3fsecs (GPU CUDAKernel) = %1.1fx更快',...gpuCUDAKernelTime, cpuTime/gpuCUDAKernelTime));
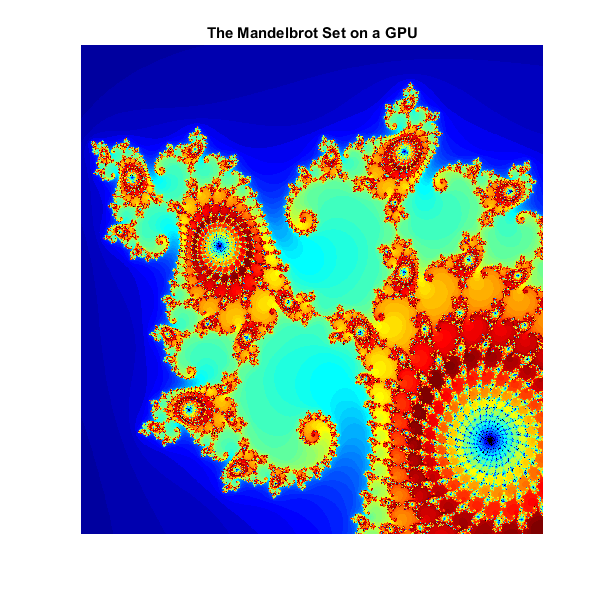
总结
这个例子展示了MATLAB算法可以使用GPU硬件的三种方式:
使用将输入数据转换为GPU上的数据
gpuArray,算法不变使用
arrayfun在一个gpuArray在输入的每个元素上独立地执行算法使用
parallel.gpu.CUDAKernel使用MATLAB数据运行一些现有的CUDA/ c++代码
标题(GPU上的Mandelbrot集)

另请参阅
相关的话题
您也可以从以下列表中选择一个网站: