GPU性能测试
这个例子展示了如何衡量GPU的一些关键性能特征。
gpu可以用来加速某些类型的计算。然而,GPU性能在不同的GPU设备之间差异很大。为了量化GPU的性能,使用了三个测试:
数据发送到GPU或从GPU读取数据的速度有多快?
GPU内核读写数据的速度有多快?
GPU的计算速度有多快?
测量完这些后,GPU的性能就可以与主机CPU进行比较。这提供了一个指南,说明GPU需要多少数据或计算才能比CPU更有优势。
设置
gpu = gpu device ();流('使用%s GPU。\n', gpu.Name) sizeOfDouble = 8;每个双精度数需要8字节的存储空间尺寸=功率(2,14:28);
使用特斯拉K40c GPU。
测试主机/GPU带宽
第一个测试估计数据发送到GPU和从GPU读取数据的速度。因为GPU是插在PCI总线上的,这在很大程度上取决于PCI总线有多快,以及有多少其他东西在使用它。然而,度量中也包含了一些开销,特别是函数调用开销和数组分配时间。因为这些在GPU的任何“真实世界”使用中都存在,所以包含这些是合理的。
在以下测试中,分配内存并将数据发送到GPUgpuArray函数。分配内存并将数据传输回主机内存收集.
请注意,在此测试中使用的PCI express v3,每个通道的理论带宽为0.99GB/s。对于NVIDIA计算卡所使用的16通道插槽(PCIe3 x16),这提供了理论上的15.75GB/s。
sendTimes = inf(大小(大小));gatherTimes = inf(大小(大小));为ii=1: numElements = size (ii)/sizeOfDouble;hostData = randi([0 9], numElements, 1);gpuData = randi([0 9], numElements, 1,“gpuArray”);%发送到GPU的时间sendFcn = @() gpuArray(hostData);sendTimes(ii) = gputimeit(sendFcn);%从GPU返回的时间gatherFcn = @() gather(gpuData);gatherTimes(ii) = gputimeit(gatherFcn);结束sendBandwidth = (size ./sendTimes)/1e9;[maxSendBandwidth, maxsenddidx] = max(sendBandwidth);流('实现峰值发送速度%g GB/s\n',maxSendBandwidth) gatherBandwidth = (size ./gatherTimes)/1e9;[maxGatherBandwidth,maxGatherIdx] = max(gatherBandwidth);流('实现峰值采集速度%g GB/s\n'马克斯(gatherBandwidth))
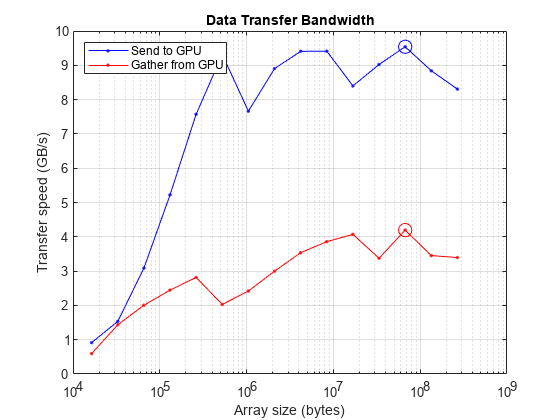
峰值采集速度为3.31891 GB/s
在下面的图表中,每一种情况的峰值都被圈了出来。对于小数据集,开销占主导地位。对于较大的数据量,PCI总线是限制因素。
持有从semilogx(大小、sendBandwidth“b -”,大小,带宽,' r . - ')举行在maxSendBandwidth semilogx(大小(maxSendIdx),“bo - - - - - -”,“MarkerSize”10);maxGatherBandwidth semilogx(大小(maxGatherIdx),“ro - - - - - -”,“MarkerSize”10);网格在标题(“数据传输带宽”)包含('数组大小(字节)') ylabel (传输速度(GB/s))传说(“发送到GPU”,“从GPU收集”,“位置”,“西北”)
测试内存密集型操作
许多操作对数组的每个元素只做很少的计算,因此主要取决于从内存中获取数据或写回数据所花费的时间。函数如的,0,南,真正的只写它们的输出,而函数像转置,下三角阵既能读又能写,但不做计算。即使是简单的操作符+,-,mtimes每个元素只做很少的计算,以至于它们只受内存访问速度的限制。
这个函数+为每个浮点运算执行一次内存读和一次内存写。因此,它应该受到内存访问速度的限制,并提供一个读+写操作速度的良好指示器。
memoryTimesGPU = inf(大小(大小));为ii=1: numElements = size (ii)/sizeOfDouble;gpuData = randi([0 9], numElements, 1,“gpuArray”);plusFcn = @() + (gpuData, 1.0);memoryTimesGPU(ii) = gputimeit(plusFcn);结束memorybandwidth = 2*(size ./memoryTimesGPU)/1e9;[maxBWGPU, maxBWIdxGPU] = max(memoryBandwidthGPU);流(在GPU上实现峰值读写速度:%g GB/s\n'maxBWGPU)
GPU最高读写速度:186.494 GB/s
现在将它与CPU上运行的相同代码进行比较。
memoryTimesHost = inf(大小(大小));为ii=1: numElements = size (ii)/sizeOfDouble;hostData = randi([0 9], numElements, 1);plusFcn = @() + (hostData, 1.0);memoryTimesHost(ii) = timeit(plusFcn);结束memoryBandwidthHost = 2*(sizes./memoryTimesHost)/1e9;[maxBWHost, maxBWIdxHost] = max(memoryBandwidthHost);流('在主机上实现峰值读写速度:%g GB/s\n'maxBWHost)绘制CPU和GPU结果。持有从semilogx(大小、memoryBandwidthGPU“b -”,...大小、memoryBandwidthHost' r . - ')举行在maxBWGPU semilogx(大小(maxBWIdxGPU),“bo - - - - - -”,“MarkerSize”10);maxBWHost semilogx(大小(maxBWIdxHost),“ro - - - - - -”,“MarkerSize”10);网格在标题(“阅读+写作带宽”)包含('数组大小(字节)') ylabel (“速度(GB / s)”)传说(“图形”,“主机”,“位置”,“西北”)
主机最高读写速度:40.2573 GB/s

将此图与上面的数据传输图进行比较,可以清楚地看到gpu读取和写入内存的速度通常比从主机获取数据的速度快得多。因此,最小化主机- gpu或gpu -主机内存传输的数量是很重要的。理想情况下,程序应该将数据传输到GPU,然后在GPU上尽可能多地处理数据,只有在完成时才将数据带回主机。更好的方法是在GPU上创建数据。
测试计算密集型操作
对于每个元素读取或写入内存所执行的浮点计算数很高的操作,内存速度就不那么重要了。在这种情况下,浮点单元的数量和速度是限制因素。这些操作被认为具有很高的“计算密度”。
计算性能的一个很好的测试是矩阵-矩阵乘法。乘以2 矩阵,浮点运算的总数是
矩阵,浮点运算的总数是
 .
.
读取两个输入矩阵,写入一个结果矩阵,总共为 元素已读或已写。这给出了一个计算密度
元素已读或已写。这给出了一个计算密度(2n - 1)/3失败/元素。对比一下+如上所述,其计算密度为1/2失败/元素。
尺寸=功率(2,12:2:24);N =根号(大小);mmTimesHost = inf(大小(大小));mmTimesGPU = inf(大小(大小));为2 = 1:元素个数(大小)首先在主机上做A = rand(N(ii), N(ii));B = rand(N(ii), N(ii));mmTimesHost(ii) = timeit(@() A*B);%现在在GPU上A = gpuArray(A);B = gpuArray(B);mmTimesGPU(ii) = gputimeit(@() A*B);结束mmGFlopsHost = (2*N.;^3 - n ^2)./mmTimesHost/1e9;[maxGFlopsHost,maxGFlopsHostIdx] = max(mmGFlopsHost);mmGFlopsGPU = (2*N。^3 - n ^2)./mmTimesGPU/1e9;[maxGFlopsGPU,maxGFlopsGPUIdx] = max(mmGFlopsGPU);流([达到的峰值计算率,...'%1.1f GFLOPS(主机),%1.1f GFLOPS (GPU)\n'],...maxGFlopsHost maxGFlopsGPU)
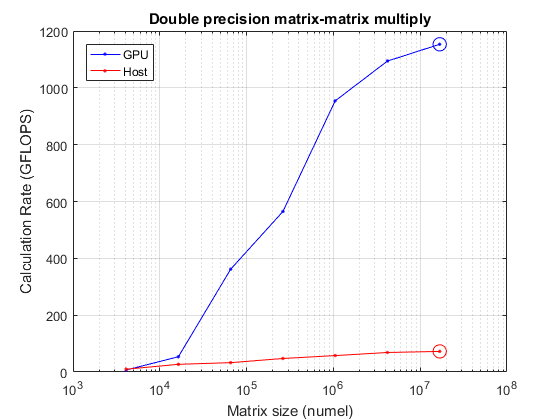
峰值计算速率为72.5 GFLOPS(主机),1153.3 GFLOPS (GPU)
现在画出顶点的位置。
持有从semilogx(大小、mmGFlopsGPU“b -”, mmGFlopsHost,' r . - ')举行在maxGFlopsGPU semilogx(大小(maxGFlopsGPUIdx),“bo - - - - - -”,“MarkerSize”10);maxGFlopsHost semilogx(大小(maxGFlopsHostIdx),“ro - - - - - -”,“MarkerSize”10);网格在标题(“双精度矩阵-矩阵乘法”)包含(矩阵大小(数字)) ylabel (计算速率(GFLOPS))传说(“图形”,“主机”,“位置”,“西北”)
结论
这些测试揭示了GPU性能的一些重要特征:
从主机内存到GPU内存的传输相对较慢。
一个好的GPU读/写内存的速度比主机CPU读/写内存的速度快得多。
给定足够大的数据,gpu可以比主机CPU更快地执行计算。
值得注意的是,在每次测试中,都需要相当大的阵列来完全饱和GPU,无论是受内存限制还是受计算限制。gpu在同时处理数百万个元素时提供了最大的优势。
中提供了更详细的GPU基准测试,包括不同GPU之间的比较GPUBench在MATLAB®中央文件交换.
您也可以从以下列表中选择一个网站: