杂波模拟的加速使用GPU和代码生成
这个例子展示了如何模拟图形处理单元(GPU)或通过代码生成(MEX)代替MATLAB解释器上的混乱。该例子适用于样本矩阵求逆(SMI)算法,流行的空时自适应处理(STAP)技术中的一种,由机载雷达与线性阵列的6元件均匀(ULA)接收的信号。这个例子集中在比较GPU,代码生成和MATLAB解释之间的杂波仿真的性能。有兴趣的读者可以找到例子模拟的细节和算法简介空时自适应处理。
这个例子的完整功能需要并行计算工具箱™和MATLAB编码器™。
杂波模拟
雷达系统的工程师常常需要模拟杂波回归测试信号处理算法,如STAP算法。然而,产生高保真杂波涉及许多步骤,因此往往是计算昂贵。例如,phased.ConstantGammaClutter使用以下步骤模拟杂波:
将整个地形为小混乱补丁。贴剂的尺寸取决于方位角贴片宽度和范围的分辨率。
对于每个patch,计算其相应的参数,如随机返回、掠射角、天线阵增益等。
从所有杂乱的补丁组合收益产生的总杂波。
杂乱的补丁数量取决于地形的覆盖,但通常在数千至数百万的范围内。另外,为了对于每个脉冲来执行上述需要的所有步骤(假设脉冲雷达被使用)。因此,杂波仿真往往是系统仿真的高高的旗杆。
为了提高杂波仿真的速度,可以利用并行计算。需要注意的是,较晚脉冲产生的杂波回波可能依赖于较早脉冲产生的信号,因此MATLAB提供了一定的并行解,如万博 尤文图斯PARFOR,并不总是适用。然而,由于在每一个片的运算,是独立于其它补丁的计算的,它是适合于GPU加速。
如果你有一个支持的GPU,并万博1manbetx且可以访问并行计算工具箱,那么你可以利用GPU来生成杂乱的返回phased.gpu.ConstantGammaClutter而不是phased.ConstantGammaClutter。在大多数情况下,使用不同的系统对象是唯一的改变,你需要让你的现有程序,如图所示如下图。

如果你有机会到MATLAB编码器,你还可以通过生成C代码为加快杂波仿真phased.ConstantGammaClutter,编译并运行编译后的版本。在代码生成模式下运行时,将编译此示例stapclutter使用codegen命令:
codegen (“stapclutter”,“参数”,…{coder.Constant (maxRange)……coder.Constant (patchAzWidth)});
所有属性值phased.ConstantGammaClutter已被作为常量值传递。该代码生成命令将生成MEX文件,stapclutter_mex,这将在循环中调用。
比较杂波模拟时报
为了比较MATLAB解释器、代码生成和GPU之间的杂波仿真性能,可以输入以下图形用户界面stapcpugpu在MATLAB命令行中。启动的GUI如下图所示:
在GUI的左侧包含四个图,示出了原始的接收信号,所接收的信号,所述处理信号的角度多普勒响应,并且STAP处理权重的角度多普勒响应。再次,详情可以在实施例中找到简介空时自适应处理。在GUI的右侧,您可以通过在方位角方向(以度为单位)和最大杂波范围(以公里为单位)修改杂波块宽度来控制杂波块的数量。然后单击Start按钮开始模拟,模拟5个连贯的处理间隔(CPI),每个CPI包含10个脉冲。每CPI一次更新处理后的信号和角度多普勒响应。
对于不同的仿真运行下一个部分显示的定时。在这些模拟中,每个脉冲由200个范围样品用50μm的范围内的分辨率。杂波贴片宽度和最大杂波范围结果以各种数目的总杂波补丁的组合。例如,10度的杂波贴片宽度和5公里的最大杂波范围意味着3600个杂波补丁。该模拟是在下述的系统配置进行:
CPU: Xeon X5650, 2.66 GHz, 24gb内存
GPU:特斯拉C2075, 6gb内存
计时结果如下图所示。
helperCPUGPUResultPlot
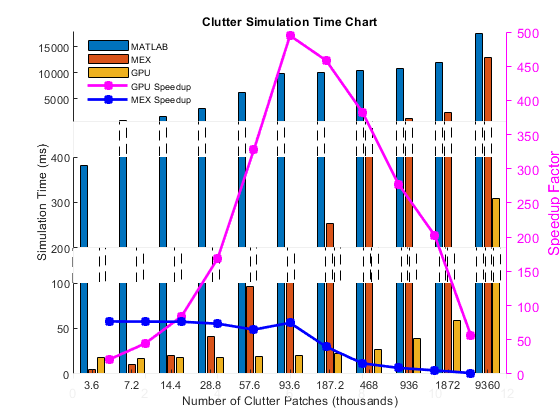
从图中可以看出,一般情况下GPU的仿真速度提高了几十倍,有时甚至上百倍。两个有趣的发现是:
当杂波小块的数量较少时,只要数据能够被适配到GPU内存中,GPU的性能几乎是恒定的。但MATLAB解释器不是这样。
一旦杂乱补丁的数量变大,数据就不能再适合GPU内存。因此,GPU在MATLAB解释器上提供的速度开始下降。然而,对于近千万的杂波补丁,GPU仍然提供超过50倍的加速。
仿真速度提高,由于代码生成小于GPU速度提高,但仍显著。代码生成的phased.ConstantGammaClutter预先计算所收集的杂波作为恒定值的阵列。对于较大的杂波数补丁阵列的尺寸变得过大,从而降低了速度的提高,由于存储器管理的开销。代码生成需要访问MATLAB编码器,但不需要特殊的硬件。
其他仿真时序结果
尽管本例中使用的模拟计算了数百万个杂波块,但是得到的数据立方体的大小为200x6x10,表示每个脉冲、6个通道和10个脉冲中只有200个范围样本。与实际问题相比,这个数据立方体很小。本例选择这些参数来展示使用GPU或代码生成的好处,同时确保示例在MATLAB解释器中在合理的时间内运行。一些使用较大数据立方体大小的模拟得到以下结果:
45倍的加速度使用GPU的模拟,产生50个脉冲为50个元素的ULA与5000范围的样本在每个脉冲,即。,一个5000x50x50的数据立方体。距离分辨率是10米。该雷达的总方位角为60度,每个杂波块的方位角为1度。最大杂波范围为50公里。杂波斑块总数为30.5万个。
使用上面的例子相同的模拟的GPU,除了与180度方位覆盖和最大杂波范围60倍的加速度等于地平线范围(约130公里)。在这种情况下,混乱的补丁总数为2356801。
总结
本例比较了使用MATLAB解释器、GPU或代码生成来模拟杂波返回的性能。结果表明,与MATLAB解释器相比,GPU和代码生成有较大的速度改进。
