使用文本文件中的数据的文件集成数据存储
在预测维护算法设计中,系统数据常常采用纯文本格式,如逗号分隔值(CSV)。此示例演示如何创建和使用fileEnsembleDatastore对象来管理以这种格式存储的数据集合。
整体数据
为示例提取压缩数据。
解压缩fleetdata.zip提取压缩文件
该合唱团由十个文件,fleetdata_01.txt,...,fleetdata_10.txt,每一个都包含一组汽车中的一辆汽车的数据。每个文件包含五个未标记的数据列,对应于下列值的每日读数:
里程表读数在一天结束的时候,在英里
燃料当天食用,以加仑
当天最高转速
一天中引擎的最高温度,以摄氏度为单位
一天结束时引擎灯的状态(0 = off, 1 = on)
每个文件包含大约80到120天的操作数据。本例中的数据集是人为制造的,与实际船队数据不一致。
配置集成数据存储
创建一个fileEnsembleDatastore对象来管理数据。
位置= pwd;扩展=' . txt ';fensemble = fileEnsembleDatastore(位置,延伸部);
配置集成数据存储以使用提供的功能readFleetData.m从文件中读取数据。
目录(fullfile (matlabroot,'例子',“predmaint”,'主要'))确保函数在路径上fensemble.ReadFcn = @readFleetData;
因为数据文件中的列没有标记,函数readFleetData将预定义的标签附加到相应的数据。配置集成数据变量以匹配其中定义的标签readFleetData。
fensemble。DataVariables = [“里程表”;“FuelConsump”;“MaxRPM”;“MaxTemp”;“EngineLight”]。
功能readFleetData还分析该文件名返回从其收集数据的车的ID,数从1到10。这ID是合奏独立变量。
fensemble.IndependentVariables =“ID”;
将所有数据变量和自变量指定为从集成数据存储中读取的选定变量。
fensemble。选择edVariables = [fensemble.IndependentVariables;fensemble.DataVariables]; fensemble
fensemble = fileEnsembleDatastore与属性:ReadFcn:@readFleetData WriteToMemberFcn:[] DataVariables:[5X1字符串] IndependentVariables: “ID” ConditionVariables:为0x0字符串] SelectedVariables:[6X1字符串] READSIZE:1个NumMembers:10 LastMemberRead:为0x0字符串]文件:[10×字符串]
读取整体数据
当你打电话读在集成数据存储中,它使用readFleetData从第一个集合成员中读取选择的变量。
DATA1 =读(fensemble)
数据1 =1×6表ID里程表FuelConsump MaxRPM MaxTemp EngineLight __ _________________ _________________ _________________ _________________ _________________ 1 x1时间表}{120}{120 x1时间表{120 x1时间表}{120 x1时间表}{120}x1的时间表
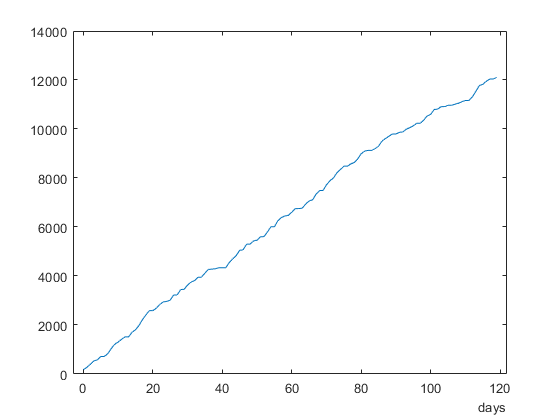
检查并绘制里程表数据。
odo1 = data1.Odometer {1}
odo1 =120×1的时间表时间VAR1 _______ ______0天180.041天266.762天396.013天535.194天574.315天714.826天714.827天821.448天1030.59天1213.410天1303.411天1416.912天1513.513天1513.514天1697.1 15天1804.6⋮
图(odo1.Time,odo1.Var1)
计算为舰队的该成员的平均油耗。此值是在最后一天的里程表读数,所消耗的总燃料划分。
fuelConsump1 = data1.FuelConsump {1} .Var1;totalConsump1 =总和(fuelConsump1);totalMiles1 = odo1.Var1(结束);mpg1 = totalMiles1 / totalConsump1
mpg1 = 22.3086
来自所有集成成员的批处理数据
如果你叫读再次,它从下一个集合构件中读取数据并前进LastMemberRead的属性fensemble以反映该集合的文件名。您可以重复处理步骤来计算该成员的平均油耗。在实践中,自动读取和处理数据的过程更有用。为此,将集合数据存储重置为未读取任何数据的状态。然后遍历集合并为每个成员执行读取和处理步骤,返回一个包含每辆车的ID和平均油耗的表。(如果您有并行计算工具箱™,您可以使用它来加速大型数据集成的处理。)
mpgData = 0 (10,2);为10个集合成员预分配数组CT = 1;而hasdata(fensemble)数据=读(fensemble);ODO = data.Odometer {1} .Var1;fuelConsump = data.FuelConsump {1} .Var1;totalConsump =总和(fuelConsump);MPG = ODO(前端)/ totalConsump1;ID = data.ID;mpgData(CT,:) = [ID,MPG];CT = CT + 1;结束mpgTable = array2table (mpgData,“VariableNames”{“ID”,“英里”})
mpgTable =10×2表ID MPG __ ______ 1 22.309 2 19.327 3 20.816 4 27.464 5 18.848 6 22.517 7 27.018 8 27.284 9 17.149 10 26.37
