基于相似性的剩余可用寿命估计
本示例展示了如何构建完整的剩余可用寿命(RUL)估计工作流,包括预处理、选择趋势特征、通过传感器融合构建健康指标、训练相似RUL估计器以及验证预测性能的步骤。该示例使用来自于的PHM2008挑战数据集的训练数据https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/[1].
数据准备
由于数据集很小,因此可以将整个降级数据加载到内存中。从中下载并解压缩数据集https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/到当前目录。使用helperLoadDatahelper函数,用于加载培训文本文件并将其转换为时间表单元格数组。培训数据包含218个运行到故障模拟。这组测量值称为“集合”。
degradationData = helperLoadData (“train.txt”);degradationData (1:5)
ans=5×1单元阵列{223×26 table} {164×26 table} {150×26 table} {159×26 table} {357×26 table}
每个集合成员是一个包含26列的表。列包含机器ID,时间戳,3个操作条件和21个传感器测量的数据。
头(degradationData {1})
ans =表8×26id时间op_setting_1 op_setting_2 op_setting_3 sensor_1 sensor_2 sensor_3 sensor_4 sensor_5 sensor_6 sensor_7 sensor_8 sensor_9 sensor_10 sensor_11 sensor_12 sensor_13 sensor_14 sensor_15 sensor_16 sensor_17 sensor_18 sensor_19 sensor_20 sensor_21 __ ____ ____________ ____________ ____________ ________ ________ ________ ________ ________ ________________ ________ ________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ _________ 1 1 10.005 0.2501 489.05 604.13 1499.5 1310 10.52 15.49 394.88 2318.9 8770.2 1.26 45.4 - 372.15 2388.1 - 8120.8 8.6216 - 0.03 28.58 - 17.174 368 2319 100 1404 100 518.67 642.13 1584.5 0.0015 - 0.0003 14.6221.61 - 553.67 2388 9045.8 1.3 47.29 521.81 2388.2 8132.9 8.3907 0.03 391 2388 100 38.99 23.362 1 3 8 60 34.999 - 0.8401 449.44 - 555.42 1368.2 1122.5 5.48 194.93 2222.9 8343.9 1.02 41.92 183.26 2387.9 8063.8 9.3557 0.02 334 2223 100 0.7005 20.003 14.83 8.8555 - 1 4 0 491.19 607.03 1488.4 1249.2 9.35 13.65 334.82 2323.8 8721.5 1.08 44.26 314.84 2388.18052.3 9.2231 0.02 364 2324 100 0.8405 42.004 24.42 14.783 - 1 5 40 445 549.52 1354.5 1124.3 3.91 5.71 138.24 2211.8 8314.6 1.02 41.79 130.44 2387.9 8083.7 9.2986 0.02 330 2212 100 10.99 20.003 - 0.7017 6.4025 - 1 6 0 491.19 607.37 1480.5 1258.9 9.35 13.65 334.51 2323.9 8711.4 1.08 44.4 315.36 2388.1 8053.2 9.2276 0.02 24.44 - 14.702 364 2324 100 1 7 420.84 40 445 549.57 1354.4 1131.4 3.91 5.71 139.11 2211.8 8316.9 1.02 42.09 130.16 2387.9 8082 9.3753 0.02 331 2212 100 10.53 6.4254 18 0.0011 0 100 518.67 642.08 1589.5 1407.6 14.62 21.61 553.48
将降级数据分解为训练数据集和验证数据集,以便稍后进行性能评估。
rng (“默认”)%以确保结果的可重复性numEnsemble=长度(退化数据);numFold=5;cv=cv分区(numEnsemble,“KFold”, numFold);trainData =降解数据(training(cv, 1));validationData =降解数据(测试(cv, 1));
指定感兴趣的变量组。
varNames=string(degradationData{1}.Properties.VariableNames);timeVariable=varNames{2};条件变量=变量名(3:5);数据变量=变量名(6:26);
可视化集合数据的样本。
nsample = 10;图helperPlotEnsemble (trainData timeVariable,...[conditionVariables (1:2) dataVariables (1:2)], nsample)
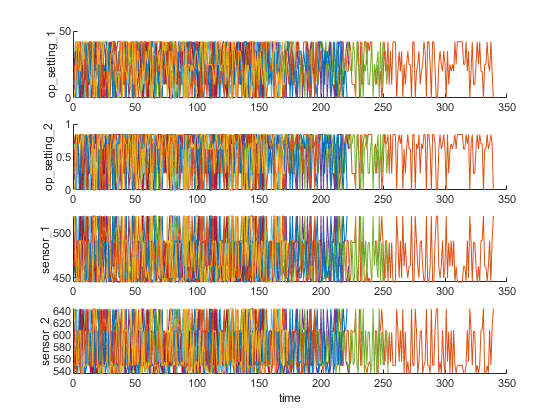
工作制度集群
如前一节所示,在每次运行到故障的测量中,没有明显的趋势显示退化过程。在本节和下一节中,将使用操作条件从传感器信号中提取更清晰的退化趋势。
注意,每个ensemble成员包含3个运行条件:“op_setting_1”、“op_setting_2”和“op_setting_3”。首先,让我们从每个单元格中提取表,并将它们连接到单个表中。
trainDataUnwrap = vertcat (trainData {:});opConditionUnwrap = trainDataUnwrap(:, cellstr(条件变量));
在3D散点图上可视化所有操作点。它清楚地显示了6个区域,每个区域的点都非常接近。
图helperPlotClusters (opConditionUnwrap)
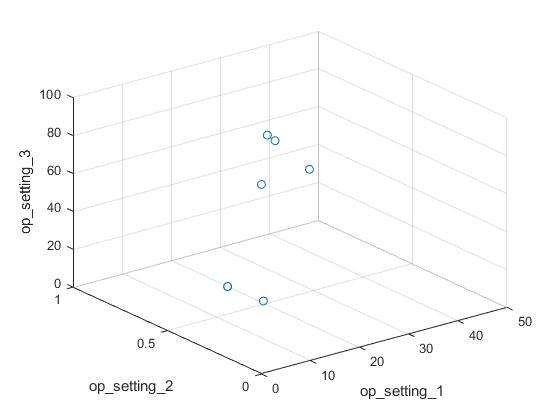
让我们使用集群技术来自动定位这6个集群。这里使用K-means算法。K-means是最流行的聚类算法之一,但它会导致局部最优。在不同的初始条件下多次重复K-means聚类算法,选取代价最小的结果是一个很好的实践。在这种情况下,算法运行5次,结果是相同的。
选择= statset (“显示”,“最后一次”);[clusterIndex,centers]=kmeans(表2阵列(opConditionUnwrap),6,...“距离”,“平方欧几里德”,“复制”5,“选项”、选择);
重复1次迭代,总距离之和= 0.279547。重复2,1次迭代,总距离之和= 0.279547。重复3,1次迭代,总距离之和= 0.279547。重复4,1次迭代,总距离之和= 0.279547。重复5,1次迭代,总距离之和= 0.279547。距离的最佳总和= 0.279547
可视化聚类结果和识别的聚类中心。
图helperPlotClusters(opConditionUnwrap、clusterIndex、Center)
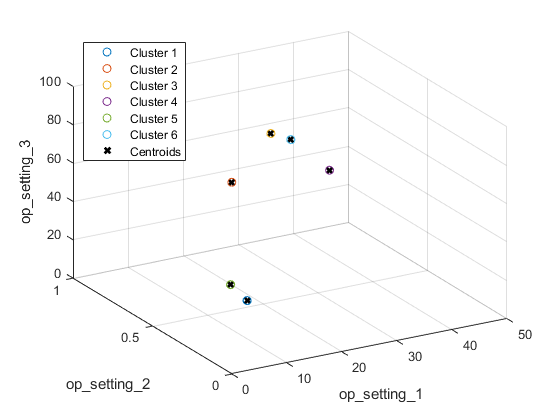
如图所示,聚类算法成功地找到了6种工作状态。
工作制度正常化
让我们对按不同工作机制分组的度量进行标准化。首先,计算每个传感器测量的平均值和标准偏差按上一节中确定的工作机制分组。
centerstats=struct(“的意思是”、表()“SD”表());为v = dataVariables centerstats.Mean.(char(v)) = splitapply(@mean, trainDataUnwrap.(char(v)), clusterIndex);(@std, trainDataUnwrap.(char(v))) = splitapply(@std, trainDataUnwrap.(char(v)), clusterIndex);结束centerstats。的意思是
ans =6×21表sensor_1 sensor_2 sensor_3 sensor_4 sensor_5 sensor_6 sensor_7 sensor_8 sensor_9 sensor_10 sensor_11 sensor_12 sensor_13 sensor_14 sensor_15 sensor_16 sensor_17 sensor_18 sensor_19 sensor_20 sensor_21 ________ ________ ________ ________ ________ ________ ________ ________ ________ _________ _________ _________ _________ _________ __________________ _________ _________ _________ _________ _________ 489.05 604.92 1502.1 1311.4 10.52 15.493 394.32 2319 8784.1 1.26 45.496 371.44 2388.2 8133.9 8.6653 0.03 369.74 2319 100 28.525 17.115 518.67 642.71 1590.7 1409.4 14.62 21.61 553.3 2388.1 9062.3 1.3 47.557 521.36 2388.1 8140.9 8.4442 0.03 393.27 2388 100 38.809 23.285 462.54 536.87 1262.81050.6 7.05 9.0275 175.4 1915.4 8014.9 0.93989 36.808 164.56 2028.3 7878 445 1915 10.916 0.02 307.39 84.93 14.262 8.5552 549.72 1354.7 1128.2 3.91 5.7158 138.62 2212 8327 2388 1.0202 42.163 130.53 8088.4 9.3775 0.02 331.12 2212 1486 100 10.584 6.3515 491.19 607.59 1253.6 9.35 13.657 334.46 2324 8729.1 1.0777 44.466 314.85 2388.2 8065 9.23470.022299 365.45 2324 100 24.447 14.67 449.44 555.82 1366.9 1131.9 5.48 8.0003 194.43 2223 8355.2 1.0203 41.995 183.01 2388.1 8071.1 9.3344 0.02 334.29 2223 100 14.827 8.8966
centerstats。SD
ans =6×21表传感器1传感器1传感器1传感器1传感器1传感器1传感器1传感器1传感器1传感器1传感器1传感器1传感器1传感器1传感器1 1传感器1 1传感器1传感器1传感器1传感器1传感器1 1传感器1传感器1 1传感器1传感器1 1传感器1 1传感器1 1传感器1 1传感器1 1传感器1 1传感器2传感器2传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器4传感器1传感器1传感器1传感器1传感器3传感器1传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器3传感器(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)__________UUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUU0.086753 4.059e-11 0.48566 5.9258 8.8223 3.7307e-14 0.0011406 0.86236 0.068654 20.061 1.2103e-13 0.25937 0.71239 0.069276 17.212 06.6.6 6.6 6.6 6.6.6.6.6.6.6 6.6.6 6.6 6.6 6.6 6.6 6.6.6 6.6.6 6.6 6.6.6.6.6.6.6.4.4.4.4.4.4.4.4.4.4.4.4.4.4.4.4.4.4.4.4.0 0.4.0 0.0 0.0 0 0 0 0.0 0.0 0 0.0 0.0 0 0 0 0 0 0 0 0 0 0 0.0.0.0 0 0.0 0.0 0 0 0 0.0 0.0.0.0.0 0.0 0 0 0 0.0.0.0 0 0 0 0 0 0 0 0 0.0.0.0 0.0.0 0.0.0.0 0 0 0.11212 0 0.12 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7135 2.231e-15 1.417.8.989 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 6 6 6 6 6 6 6 6 6 6 6 6 6 3 3 3 3 3 3 3 3 3 3 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 11 0.069348
每个状态下的统计数据可以用来对训练数据进行归一化。对于每个集合成员,提取每一行的操作点,计算其到每个簇中心的距离,并找到最近的簇中心。然后,对于每个传感器测量,减去平均值并除以该集群的标准偏差。如果标准偏差接近0,则将归一化传感器测量设为0,因为几乎恒定的传感器测量对剩余使用寿命估计没有用处。有关regimeNormalization函数的更多细节,请参阅最后一节“Helper函数”。
trainDataNormalized = cellfun(@(data)...trainData,“UniformOutput”、假);
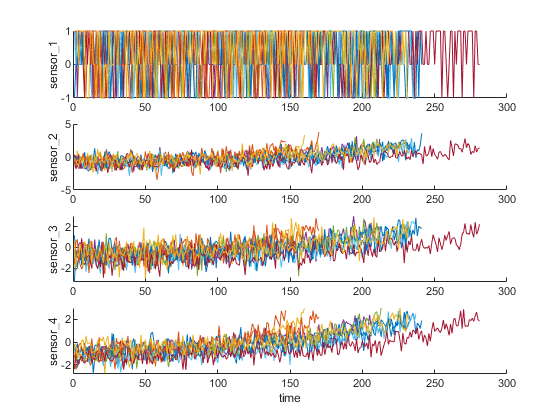
可视化根据工作状态规范化的数据。一些传感器测量的退化趋势在归一化后现现。
figure helperPlotEnsemble(trainDataNormalized, timeVariable, datavvariables (1:4), nsample)
Trendability分析
现在,选择最具趋势的传感器测量值来构建一个用于预测的健康指标。对于每个传感器测量,估计线性退化模型,并对信号的斜率进行排序。
numSensors=长度(数据变量);signalSlope=零(numSensors,1);warn=警告(“关闭”);为ct = 1:numSensors tmp = cellfun(@(tbl) tbl(:, cellstr(dataVariables(ct))), traindatanorized,“UniformOutput”、假);mdl = linearDegradationModel ();%建立模型fit(mdl、tmp);%训练模式signalSlope (ct) = mdl.Theta;结束警告(warn);
对信号斜率进行排序,选择斜率最大的8个传感器。
[~, idx] = sort(abs(signalSlope),“下”);sensorTrended =排序(idx (1:8))
sensorTrended =8×12 3 4 7 11 12 15 17
可视化选定的趋势传感器测量值。
figure helperPlotEnsemble(trainDataNormalized, timeVariable, datavvariables (sensorTrended(3:6)), nsample)
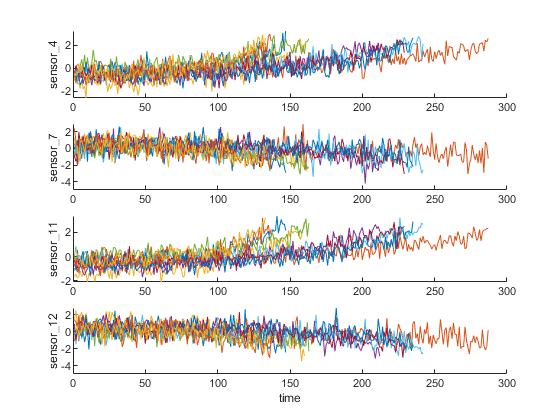
请注意,一些最具趋势性的信号显示出积极的趋势,而另一些则显示出消极的趋势。
构建健康指示器
本节重点介绍将传感器测量结果融合到单个健康指标中,使用该指标训练基于相似性的模型。
假设所有运行到失败的数据都是从健康状态开始的。开始时的健康状况被赋值为1,失败时的健康状况被赋值为0。假定健康状况随时间从1线性下降到0。这种线性退化被用来帮助融合传感器的值。文献[2-5]描述了更复杂的传感器融合技术。
为j=1:numel(trainDataNormalized)data=trainDataNormalized{j};rul=最大值(数据时间)-数据时间;data.health_条件=rul/max(rul);trainDataNormalized{j}=数据;结束
想象健康状况。
图helperPlotEnsemble (trainDataNormalized timeVariable,“health_condition”nsample)
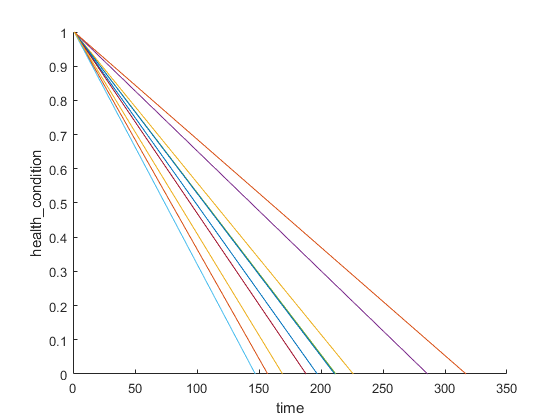
随着退化速度的变化,所有集成成员的健康状况从1变为0。
现在,用最流行的传感器测量作为回归器,拟合健康状况的线性回归模型:
健康状态~ 1 +传感器2 +传感器3 +传感器4 +传感器7 +传感器11 +传感器12 +传感器15 +传感器17
trainDataNormalizedUnwrap = vertcat (trainDataNormalized {:});sensorToFuse = dataVariables (sensorTrended);X = trainDataNormalizedUnwrap{:, cellstr(sensorToFuse)};y = trainDataNormalizedUnwrap.health_condition;regModel = fitlm (X, y);偏见= regModel.Coefficients.Estimate (1)
偏见= 0.5000
权重=regModel.系数.估算(2:结束)
砝码=8×1-0.0308 -0.0308 -0.0536 0.0033 -0.0639 0.0051 -0.0408 -0.0382
通过将传感器测量值与相关权重相乘,构建单个运行状况指示器。
trainDataFused = cellfun(@(data)降解传感器融合(data, sensorToFuse, weights), traindatanorized,...“UniformOutput”、假);
可视化训练数据的融合运行状况指示器。
图HELPERPLOTESSEMBLE(trainDataFused,[],1,nsample)xlabel(“时间”) ylabel (“健康指示器”)标题(的训练数据)
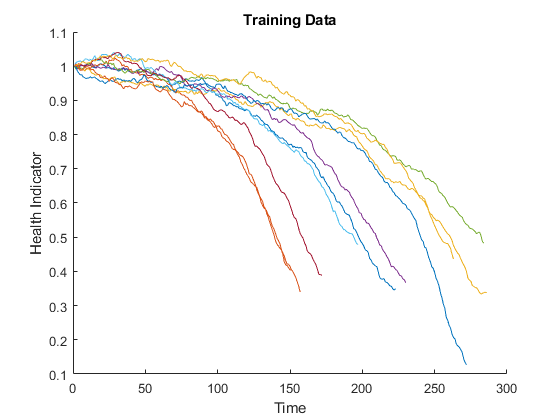
来自多个传感器的数据被融合成一个单一的健康指标。运行状况指示器通过移动平均滤波器进行平滑。更多细节请参阅最后一节中的helper函数“降解传感器融合”。
对验证数据应用相同的操作
对验证数据集重复区域标准化和传感器融合过程。
validationdatornormalize = cellfun(@(data))...validationData,“UniformOutput”,false);validationDataFused=cellfun(@(数据)降级传感器融合(数据、传感器使用、权重),...validationDataNormalized,“UniformOutput”、假);
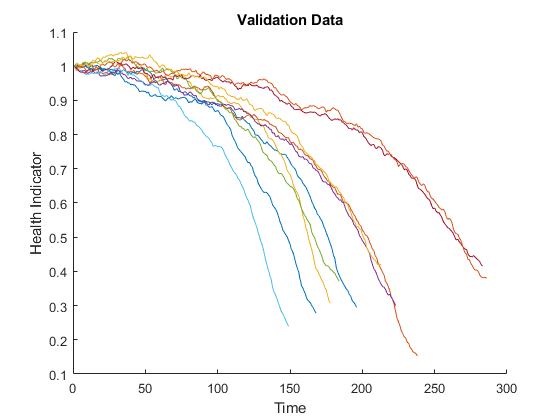
可视化验证数据的运行状况指示器。
图helperPlotEnsemble(validationDataFused, [], 1, nsample)“时间”) ylabel (“健康指示器”)标题(验证数据的)
建立相似规则模型
利用训练数据建立基于残差的相似度RUL模型。在这种情况下,模型试图用一个二阶多项式拟合每个融合数据。
数据间距离 和数据 是由残差的一范数计算的吗
在哪里 机器的运行状况指示器是否正常 , 估计的机器运行状况指示器是否正确 利用机器辨识的二阶多项式模型 .
相似度评分的计算公式如下
在验证数据集中给定一个集合成员,模型将在训练数据集中找到最接近的50个集合成员,并基于这50个集合成员拟合概率分布,并使用分布的中位数作为RUL的估计。
mdl=剩余相似模型(...“方法”,“poly2”,...“距离”,“绝对的”,...“NumNearestNeighbors”, 50岁,...“标准化”1);fit (mdl trainDataFused);
绩效评估
为了评估相似性RUL模型,使用50%、70%和90%的样本验证数据来预测其RUL。
断点=[0.5,0.7,0.9];validationDataTmp=validationDataFused{3};%使用一个验证数据进行说明
在第一个断点之前使用验证数据,该断点占生命周期的50%。
bpidx = 1;validationDataTmp50 = validationDataTmp(1:装天花板(结束*断点(bpidx)):);true = length(validationDataTmp) - length(validationDataTmp50);[estRUL, ciRUL, pdfRUL] = predictRUL(mdl, validationDataTmp50); / /确认数据
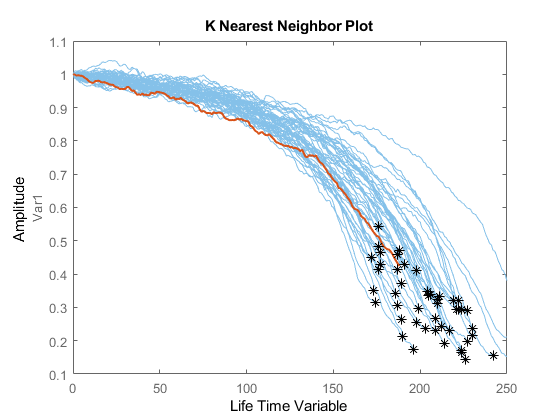
可视化截断为50%的验证数据及其最近的邻居。
图比较(mdl validationDataTmp50);
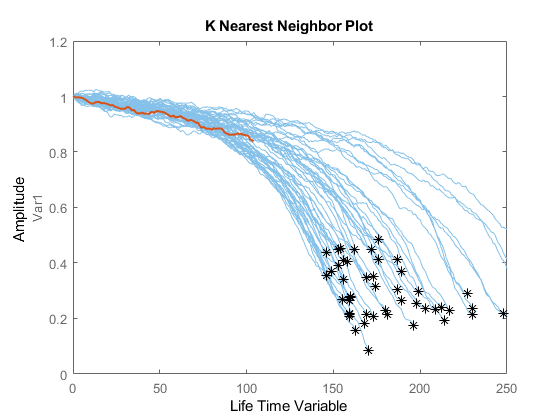
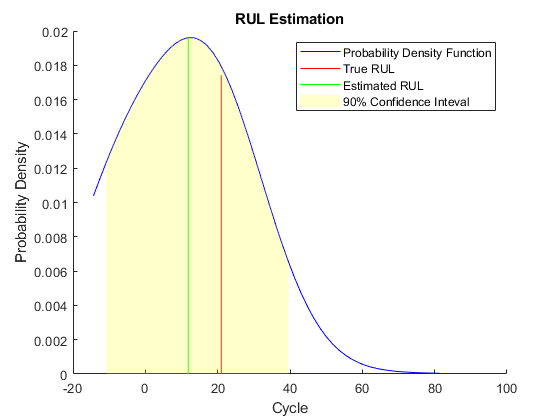
将估计的规则l与真实的规则l进行比较,并将估计的规则l的概率分布可视化。
图helperPlotRULDistribution(trueRUL, estRUL, pdfRUL, ciRUL)
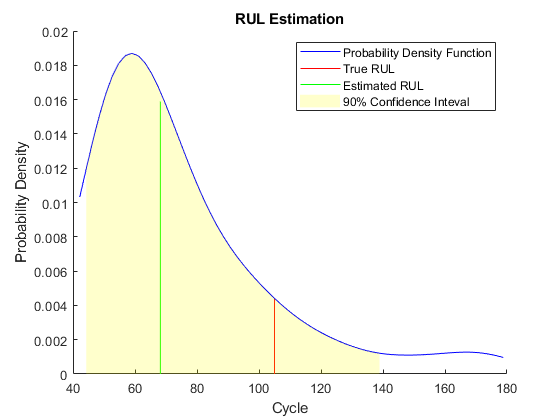
当机器处于中间健康阶段时,估计的RUL和真实的RUL之间存在较大的误差。在本例中,最相似的10条曲线在开始时很接近,但当它们接近失效状态时分叉,导致RUL分布大致有两种模式。
在第二个断点之前使用验证数据,第二个断点占生命周期的70%。
bpidx = 2;validationDataTmp70 = validationDataTmp(1: cell (end*breakpoint(bpidx)),:);true = length(validationDataTmp) - length(validationDataTmp70);[estRUL,ciRUL,pdfRUL] = predictRUL(mdl, validationDataTmp70); / /确认数据图比较(mdl validationDataTmp70);
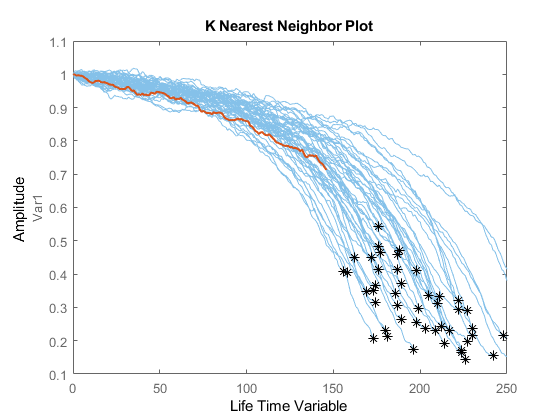
图helperPlotRULDistribution(trueRUL, estRUL, pdfRUL, ciRUL)
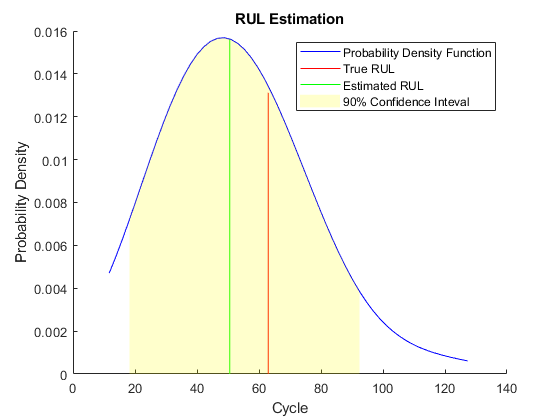
当观察到更多的数据时,RUL估计会增强。
在第三个断点(即生命周期的90%)之前使用验证数据。
bpidx = 3;validationDataTmp90 = validationDataTmp(1: cell (end*breakpoint(bpidx)),:);true = length(validationDataTmp) - length(validationDataTmp90);[estRUL,ciRUL,pdfRUL] = predictRUL(mdl, validationDataTmp90); / /确认数据图比较(mdl validationDataTmp90);
图helperPlotRULDistribution(trueRUL, estRUL, pdfRUL, ciRUL)
当机器接近故障时,RUL估计在本例中得到了更大的增强。
现在,对整个验证数据集重复相同的评估过程,计算每个断点的估计RUL和真实RUL之间的误差。
numValidation =长度(validationDataFused);numBreakpoint =长度(断点);错误= 0 (numValidation, numBreakpoint);为dataIdx=1:numValidation tmpData=validationDataFused{dataIdx};为bpidx = 1:numBreakpoint tmpDataTest = tmpData(1: cell (end*breakpoint(bpidx)),:);trueRUL = length(tmpData) - length(tmpDataTest);[estRUL, ~, ~] = predictRUL(mdl, tmpDataTest);error(dataIdx, bpidx) = estRUL - trueRUL;结束结束
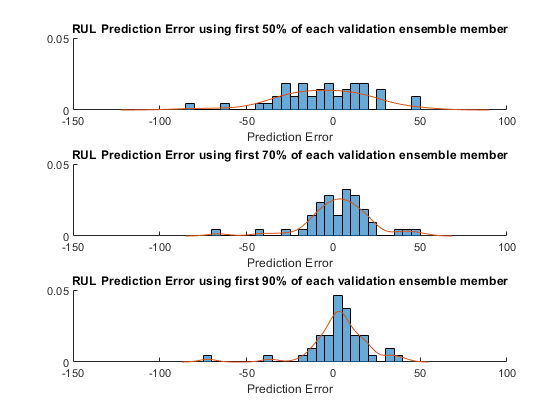
可视化每个断点的误差直方图及其概率分布。
[pdf50,x50]=ksdensity(错误(:,1));[pdf70,x70]=ksdensity(错误(:,2));[pdf90,x90]=ksdensity(错误(:,3));图ax(1)=子批次(3,1,1);保持在直方图(错误(:1),“BinWidth”5,“归一化”,“pdf”)绘图(x50,pdf50)保持远离的包含(预测误差的)标题(“使用每个验证集合成员的前50%的RUL预测错误”) ax(2) = subplot(3,1,2);持有在直方图(错误(:,2),“BinWidth”5,“归一化”,“pdf”) plot(x70, pdf70) hold远离的包含(预测误差的)标题(“使用每个验证集合成员前70%的RUL预测误差”) ax(3) = subplot(3,1,3);持有在直方图(错误(:,3),“BinWidth”5,“归一化”,“pdf”) plot(x90, pdf90) hold远离的包含(预测误差的)标题(“使用每个验证集合成员前90%的RUL预测误差”) linkaxes (ax)
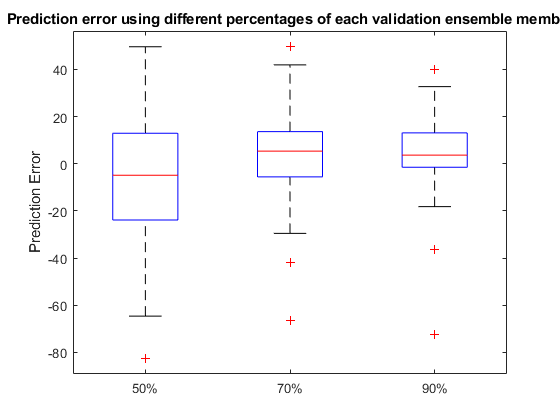
在框图中绘制预测误差,以可视化中值、25-75分位数和离群值。
图箱线图(错误,“标签”, {“50%”,“70%”,“90%”})伊拉贝尔(预测误差的)标题(“使用每个验证集合成员的不同百分比的预测误差”)
计算并可视化预测误差的平均值和标准差。
errorMean =意味着(错误)
平均误差=1×3-5.8944 3.1359 3.3555
误差中值=中值(误差)
errorMedian =1×3-4.8538 5.3763 3.6580
errorSD =性病(错误)
errorSD =1×326.4916 20.0720 18.0313
figure errorbar([50 70 90], errorMean, errorSD,“o”,“MarkerEdgeColor”,“r”) xlim([40,100])“用于RUL预测的验证数据百分比”) ylabel (预测误差的)传说(“具有1个标准差误差条的平均预测误差”,“位置”,“南”)
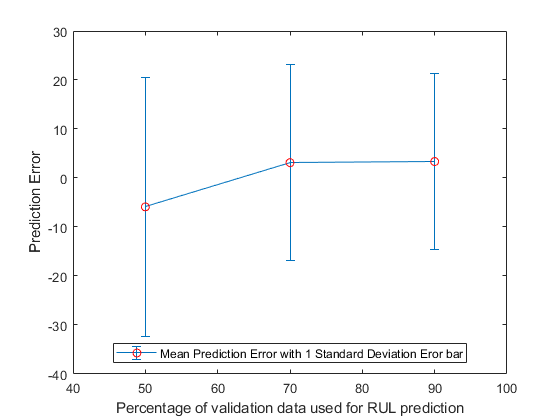
结果表明,随着观测数据的增加,误差更集中在0(更少的异常值)附近。
参考文献
[1] A. Saxena和K. Goebel(2008)。“PHM08挑战数据集”,NASA Ames预测数据存储库(http://ti.arc.nasa.gov/project/prognostic-data-repository), NASA Ames研究中心,Moffett Field, CA
Roemer, Michael J., Gregory J. Kacprzynski, Michael H. Schoeller。“利用健康管理信息融合改进诊断和预后评估。”AUTOTESTCON会议录,2001年。IEEE系统就绪技术会议.IEEE 2001。
戈贝尔,凯,皮耶罗·博尼松。“恒定负荷系统的预测信息融合。”信息融合,2005,第8届国际会议.卷。2。IEEE 2005。
Wang, Peng和David W. Coit。“基于退化建模的具有多种退化措施的系统可靠性预测。”可靠性和可维护性,2004年年度研讨会.IEEE 2004。
[5] Jardine, Andrew KS, Daming Lin和Dragan Banjevic。“对机械诊断和基于状态维护的预测进行了回顾。”机械系统和信号处理20.7 (2006): 1483-1510.
辅助函数
功能数据=区域规范化(数据、中心、centerstats)%对数据的每个观察(行)执行归一化%根据观察所属的群集。conditionIdx = 3:5;dataIdx =第一;%行操作数据{:,dataIdx}=table2array(...rowfun(@(row) localNormalize(row, conditionIdx, dataIdx, centers, centerstats),...数据,“SeparateInputs”、假));结束功能rownormalization = localNormalize(row, conditionIdx, dataIdx, centers, centerstats)%每一行的规范化操作。获得操作点和传感器测量值ops = row(1, conditionIdx);sensor = row(1, dataIdx); / /读取数据找出哪个集群中心是最近的距离=和((中心-操作)。^2,2);[~,idx]=min(距离);用集群的平均值和标准偏差对传感器测量值进行归一化。将NaN和Inf重新赋值为0。rowNormalized = (sensor - centerstats。Mean{idx,:}) ./ centerstats。SD {idx:};isnan(rowNormalized) | isinf(rowNormalized)) = 0;结束功能dataFused =降解sensorfusion (data, sensorToFuse, weights)根据不同的传感器组合测量%对于权重,平滑融合数据并偏移数据%,以便所有数据从1开始%根据权重对数据进行融合dataToFuse=data{:,cellstr(sensorToFuse)};dataFusedRaw=dataToFuse*权重;%用移动平均值平滑融合数据退步=10;向前跨步=10;dataFusedRaw=movmean(dataFusedRaw,[stepBackward-stepForward]);%将数据偏移到1数据融合=数据融合+1-数据融合(1);结束
另请参阅
相关的话题
您还可以从以下列表中选择网站:
