使用强化学习设计器创建代理
的强化学习设计App支万博1manbetx持以下类型的代理。
深Q-Network代理(DQN)
深度确定性政策梯度代理(DDPG)
双延迟深度确定性策略梯度代理(TD3)
近端政策优化代理(PPO)
训练特工使用强化学习设计,必须先创建或导入环境。有关更多信息,请参见为强化学习设计创建MATLAB环境和为强化学习设计万博1manbetx器创建Simulink环境。
创建代理
要创建代理,请在强化学习选项卡,代理部分中,点击新。
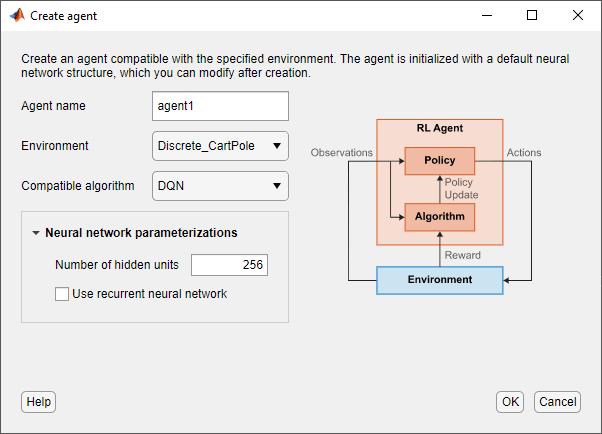
在“创建代理”对话框中输入以下信息。
代理名称—指定您的代理名称。
环境—选择之前创建或导入的环境。
兼容的算法—选择agent训练算法。此列表只包含与您选择的环境兼容的算法。
的强化学习设计App创建具有默认深度神经网络参与者和评论家表示的代理。您可以为默认网络指定以下选项。
隐藏单元数-指定在actor和批评家网络的每个全连接或LSTM层中的单元数。
使用递归神经网络-选择此选项创建actor和critic表示,使用包含LSTM层的循环神经网络。
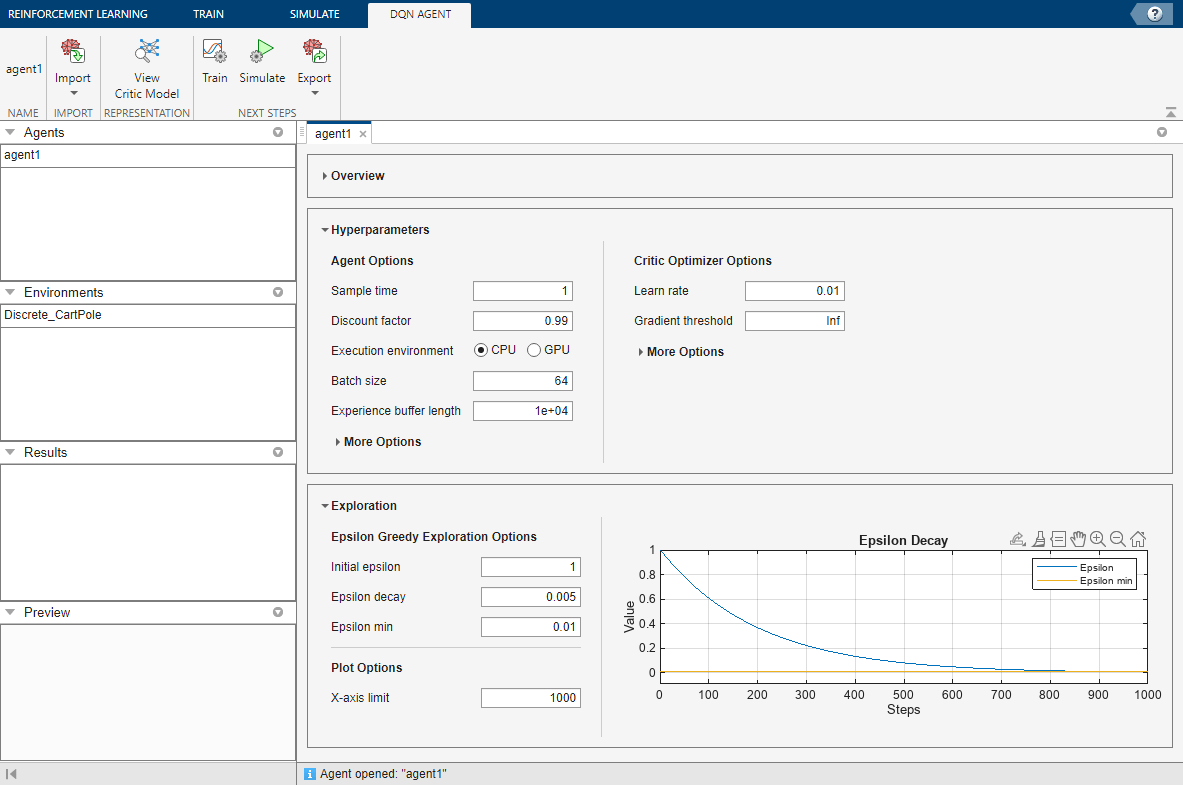
单击,创建代理好吧。
控件中添加新的默认代理代理窗格,并打开用于编辑代理选项的文档。
进口代理商
您还可以从MATLAB中导入代理®工作空间到强化学习设计。要这样做,就得上强化学习选项卡上,单击进口。然后,在选择代理,选择要导入的代理。
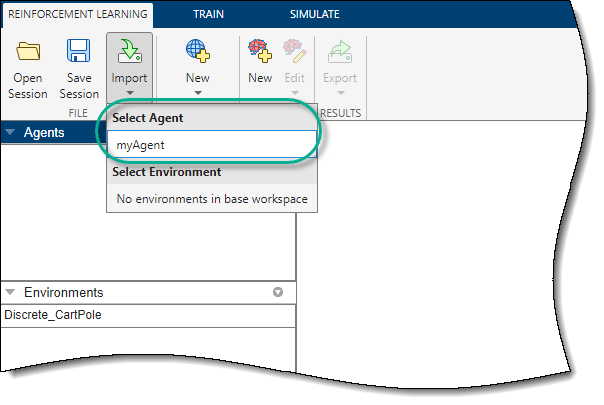
应用程序将新导入的代理添加到代理窗格,并打开用于编辑代理选项的文档。
编辑代理选项
在强化学习设计,您可以在对应的代理文档中编辑代理选项。
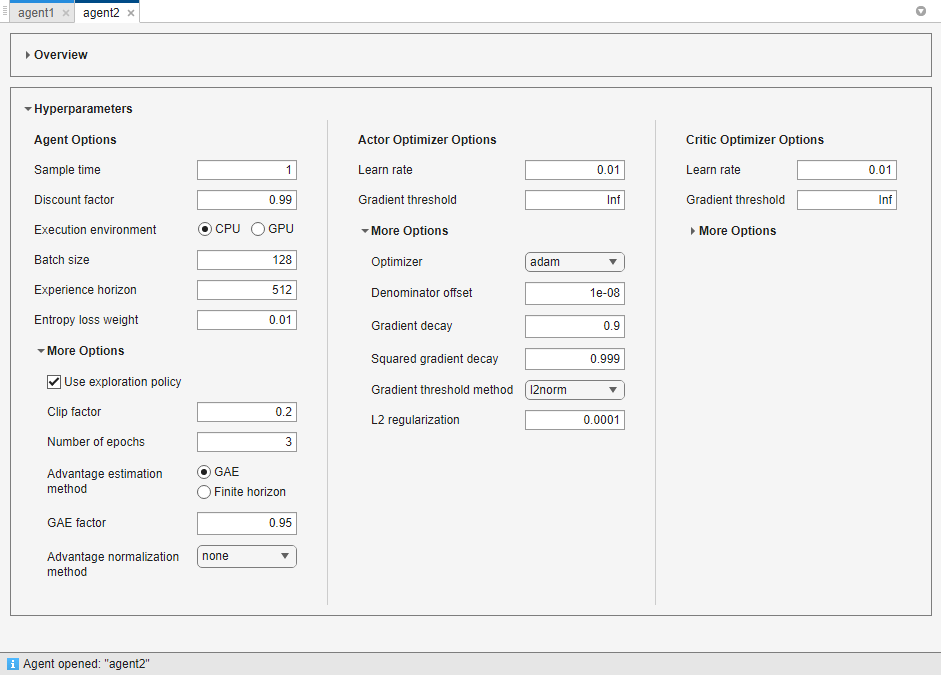
您可以为每个代理编辑以下选项。
剂的选择—代理选项,如样本时间和折扣因子。为所有支持的代理类型指定这些选项。万博1manbetx
探索模型-探索模式选项。PPO代理商没有探索模式。
目标政策平滑模型—目标策略平滑选项,仅支持TD3座席。万博1manbetx
有关这些选项的更多信息,请参见相应的代理选项对象。
rlDQNAgentOptions—DQN代理选项rlDDPGAgentOptions- DDPG代理选项rlTD3AgentOptions- TD3代理选项rlPPOAgentOptions- PPO代理选项
您可以从MATLAB工作区导入代理选项。要为每种代理类型创建选项,请使用上述对象之一。还可以导入以前从强化学习设计应用程序
导入选项,上对应的代理选项卡上,单击进口。然后,在选项,选择一个options对象。该应用程序只列出了MATLAB工作区中兼容的选项对象。
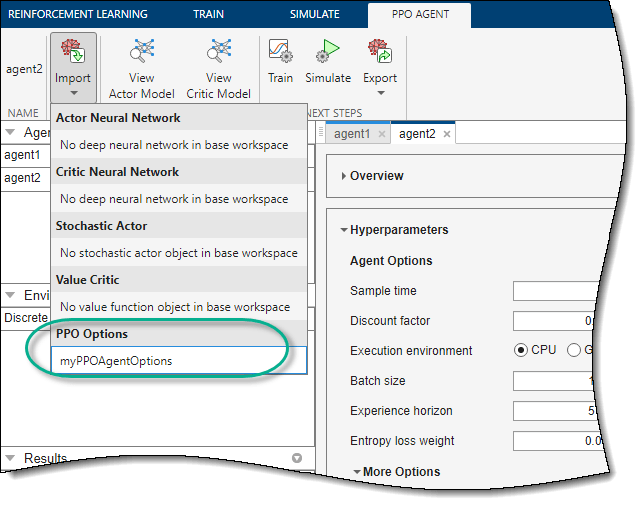
应用程序配置代理选项,以匹配那些在选中的选项对象。
演员和评论家
您可以编辑每个代理的参与者和评论家表示的属性。
DQN代理只有一个评论网络。
DDPG和PPO代理有演员代表和评论家代表。
TD3代理有一个参与者表示和两个评论家表示。当您修改TD3代理的批评表示选项时,更改将应用于两个批评。
您还可以从MATLAB工作区导入参与者和评论家表示。有关创建参与者和评论家表示的更多信息,请参见创建策略和值函数表示。控件中导出的表示形式也可以导入强化学习设计应用程序。
引进演员或批评家的代表,对相应的代理选项卡上,单击进口。然后,在演员或评论家,选择一个具有与代理的规范兼容的动作和观察规范的表示对象。
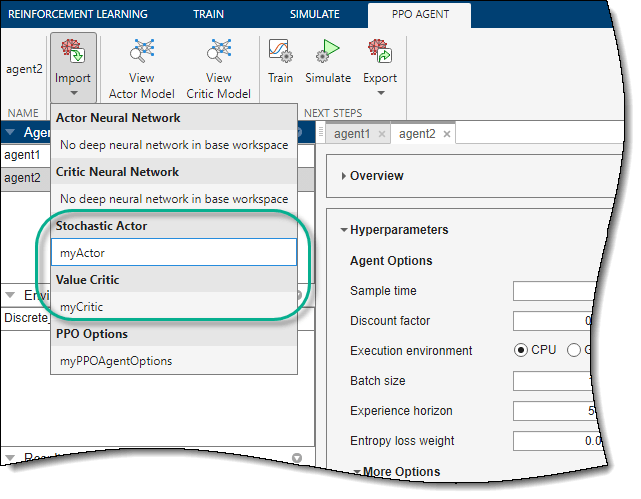
应用程序将代理中的参与者或评论家表示替换为所选表示。如果您为TD3代理导入评论表示,应用程序将替换这两个评论的网络。
改进深度神经网络
要为演员或评论家使用非默认的深度神经网络,必须从MATLAB工作区导入网络。一种常见的策略是导出默认的深度神经网络,使用深层网络设计师App,然后导入回强化学习设计。有关为演员和评论家创建深度神经网络的更多信息,请参见创建策略和值函数表示。
导入一个深度神经网络,就相应的代理选项卡上,单击进口。然后,在演员神经网络或评论家神经网络,选择一个输入和输出层与代理的观察和动作规范兼容的网络。
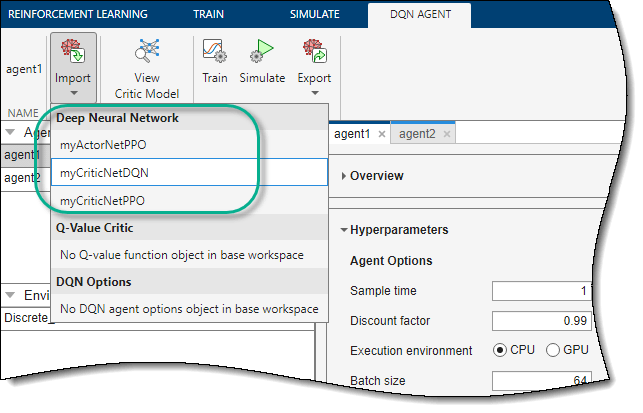
该应用程序在相应的行动者或代理表示中取代了深度神经网络。如果您为TD3代理导入评论网络,应用程序将替换这两个评论的网络。
导出代理和代理组件
对于给定的代理,您可以将以下任何内容导出到MATLAB工作区。
代理
剂的选择
演员或评论家代表
演员或评论家深度神经网络
导出agent或agent组件时,对应上代理选项卡上,单击出口。然后,选择要导出的项。
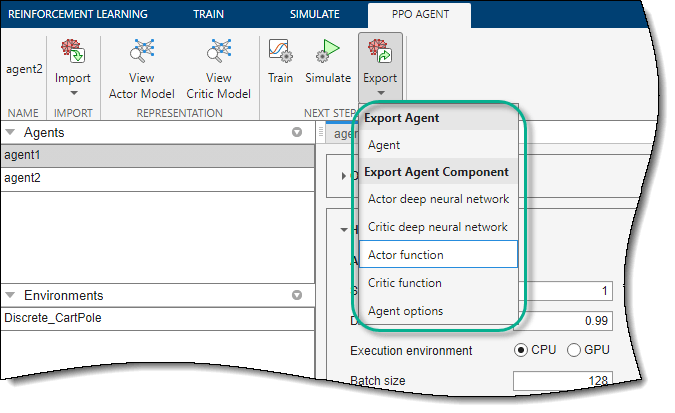
该应用程序在MATLAB工作区中保存了一个代理或代理组件的副本。
另请参阅
相关的话题
你也可以从以下列表中选择一个网站: