强化学习代理
强化学习的目标是训练agent在不确定的环境中完成任务。代理从环境接收观察和奖励,并向环境发送操作。奖励是衡量一项行动在完成任务目标方面的成功程度。
该代理包含两个组件:策略和学习算法。
策略是一个映射,它根据来自环境的观察选择操作。通常,策略是带有可调参数的函数逼近器,例如深度神经网络。
学习算法根据行为、观察和奖励不断更新策略参数。学习算法的目标是找到一个最优策略,使任务期间获得的累积奖励最大化。
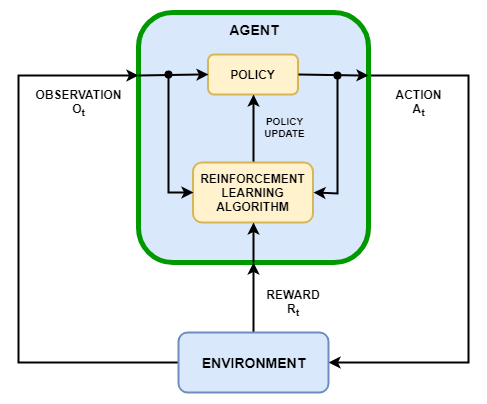
根据学习算法,代理维护一个或多个参数化函数逼近器来训练策略。函数逼近器有两种类型。
批评人士-对于一个给定的观察和行动,评论家会发现任务的长期未来回报的期望值。
演员-对于一个给定的观察,一个参与者找到了最大化长期未来回报的行为
有关创建actor和批评家函数逼近器的更多信息,请参见创建策略和值函数表示。
内置代理
Reinforcement Learning Toolbox™软件提供了以下内置的agent。每个agent都可以在具有连续或离散的观察空间和以下动作空间的环境中进行训练。
| 代理 | 行动 |
|---|---|
| q学习的代理 | 离散 |
| 撒尔沙代理 | 离散 |
| 深Q-Network代理 | 离散 |
| 政策梯度代理 | 离散或连续 |
| 深度确定性策略梯度代理 | 连续 |
| 双延迟深确定性策略梯度代理 | 连续 |
| Actor-Critic代理 | 离散或连续 |
| 近端策略优化代理 | 离散或连续 |
自定义代理
您还可以通过创建自定义代理来使用其他学习算法来培训策略。为此,需要创建一个定制代理类的子类,使用一组必需和可选方法定义代理行为。有关更多信息,请参见自定义代理。
另请参阅
rlACAgent|rlDDPGAgent|rlDQNAgent|rlPGAgent|rlPPOAgent|rlQAgent|rlSARSAAgent