rlddpgagent.
深度确定性政策梯度加固学习代理
描述
深度确定性政策梯度(DDPG)算法是一个演员 - 评论家,无模型,在线,禁止策略加强学习方法,这些禁止措施方法计算了最大化长期奖励的最佳政策。动作空间只能是连续的。
有关更多信息,请参阅深度确定性政策梯度代理。有关不同类型的强化学习代理商的更多信息,请参阅加固学习代理人。
创建
句法
描述
从观察和行动规范创建代理
代理人= rlddpgagent(观察税收那ActionInfo.)观察税收和行动规范ActionInfo.。
代理人= rlddpgagent(观察税收那ActionInfo.那初学者)初学者目的。有关初始化选项的详细信息,请参阅rlagentinitializationOptions.。
指定代理选项
代理人= rlddpgagent(___那代理选项)代理选项财产到代理选项输入参数。在上一个语法中的任何输入参数后使用此语法。
输入参数
特性
对象功能
火车 |
在指定环境中列车加固学习代理 |
SIM |
在指定环境中模拟培训的钢筋学习代理 |
努力 |
从代理商或演员代表获取行动给定环境观察 |
工作者 |
获取钢筋学习代理人的演员代表 |
setActor. |
设置钢筋学习代理的演员代表 |
透镜 |
获取钢筋学习代理人的批评奖学金 |
setcritic. |
设定批评批评学习代理的代表 |
生成policyfunction. |
创建评估培训的强化学习代理策略的功能 |
例子
从观察和操作规范创建DDPG代理
创建具有连续动作空间的环境,并获得其观察和动作规范。对于此示例,请加载示例中使用的环境火车DDPG代理控制双积分系统。从环境中观察是含有质量的位置和速度的载体。该动作是代表一种力的标量,从而连续地测量 -2至2牛顿。
%加载预定义环境Env = Rlpredefinedenv(“双凝胶组连续”);%获得观察和行动规范ObsInfo = GetobservationInfo(ENV);Actinfo = GetActionInfo(Env);
代理创建函数随机初始化演员和批评网络。您可以通过固定随机发生器的种子来确保再现性。为此,取消注释以下行。
%rng(0)
从环境观察和操作规范中创建一个策略渐变代理。
代理= rlddpgagent(Obsinfo,Actinfo);
检查您的代理人,使用努力从随机观察返回动作。
GetAction(代理,{rand(ObsInfo(1).dimension)})
ans =.1x1细胞阵列{[0.0182]}
您现在可以在环境中测试和培训代理人。
使用初始化选项创建DDPG代理
创建具有连续动作空间的环境,并获得其观察和操作规范。对于此示例,请加载示例中使用的环境培训DDPG代理以摇摆和平衡摆动图像观察。该环境有两个观察结果:50×50灰度图像和标量(摆动的角速度)。动作是表示扭矩连续的标量 -2至2纳米。
%加载预定义环境Env = Rlpredefinedenv(“SimpleEdpulumWithimage-insult”);%获得观察和行动规范ObsInfo = GetobservationInfo(ENV);Actinfo = GetActionInfo(Env);
创建代理初始化选项对象,指定网络中的每个隐藏的完全连接图层必须具有128.神经元(而不是默认号码,256.)。
Initopts = rlagentinitializationOptions('numhidendentunit',128);
代理创建函数随机初始化演员和批评网络。您可以通过固定随机发生器的种子来确保再现性。为此,取消注释以下行。
%rng(0)
从环境观测和操作规范中创建DDPG代理。
代理= rlddpgagent(Obsinfo,Actinfo,Enitopts);
将批评评论率降低到1E-3。
评论家=克罗里特(代理人);批评.Options.Learnrate = 1E-3;代理= setcritic(代理商,批评者);
从代理演员和评论家中提取深度神经网络。
ActORNET = GetModel(GetAttor(代理));批评= getModel(accritic(代理));
显示批评网络的层,并验证每个隐藏的完全连接层是否有128个神经元
批评
ANS = 14x1层阵列具有层数:1'求解'沿尺寸3的输入串联连接3 2'Relu_Body'Relu 3'FC_Body'完全连接的128完全连接的第4层Body_Output'Relu Relu 5'Infum_1'图像输入50x50x1图像6'conv_1'卷积64 3x3x1卷曲升级[1 1]和填充[0 0 0 0] 7'Relu_Input_1'Relu Relu 8'FC_1'完全连接的128完全连接的第9层Input_2'图像输入1x1x1图像10'FC_2'完全连接的128完全连接层11'Input_3'图像输入1x1x1图像12'fc_3'完全连接的128完全连接的层13'输出'完全连接的1完全连接的第14层'表示数值均值均值
情节演员和批评网络
情节(ACTORNET)
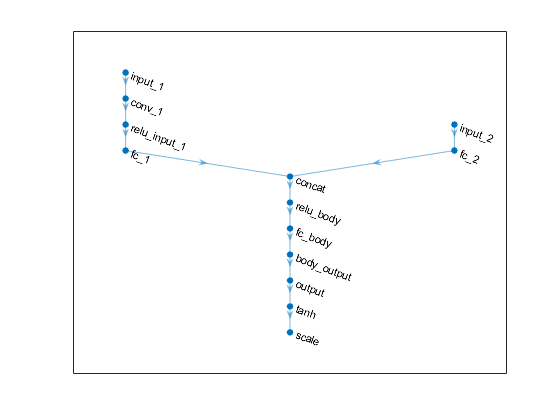
情节(批评)

检查您的代理人,使用努力从随机观察返回动作。
GetAction(代理,{rand(ObsInfo(1).dimiles),Rand(Obsinfo(2).dimension)})
ans =.1x1细胞阵列{[-0.0364]}
您现在可以在环境中测试和培训代理人。
从演员和评论家创建DDPG代理
创建具有连续动作空间的环境,并获得其观察和操作规范。对于此示例,请加载示例中使用的环境火车DDPG代理控制双积分系统。从环境中观察是含有质量的位置和速度的载体。动作是表示连续测距的标量 -2至2牛顿。
Env = Rlpredefinedenv(“双凝胶组连续”);ObsInfo = GetobservationInfo(ENV);Actinfo = GetActionInfo(Env);
创造批评者代表。
%创建一个用于用作底层批评的网络近似值equentpath = imageInputLayer([ObsInfo.dimension(1)1],'正常化'那'没有任何'那'名称'那'状态');ActionPath = ImageInputLayer([Numel(ActInfo)1 1],'正常化'那'没有任何'那'名称'那'行动');commonpath = [concatenationlayer(1,2,'名称'那'concat')四raticallayer('名称'那'二次')全康连接层(1,'名称'那'endicevalue'那'biaslearnratefactor',0,'偏见',0)];批判性=图表图(州路);批评网络= addlayers(批判性,ActionPath);批评网络= addlayers(批判性,commonpath);批评网络= ConnectLayers(批评者,'状态'那'concat / In1');批评网络= ConnectLayers(批评者,'行动'那'concat / In2');%为评论家设置一些选项批评= rlrepresentationOptions('学习',5e-3,'gradientthreshold',1);%基于网络近似器创建批评者评论家= rlqvalueerepresentation(批评,undernfo,Actinfo,......'观察',{'状态'},'行动',{'行动'},批评);
创建一个演员表示。
%创建一个用于用作底层演员近似器的网络ActorNetWork = [ImageInputLayer([ObsInfo.dimension(1)1 1],'正常化'那'没有任何'那'名称'那'状态')全连接列(Numel(Actinfo),'名称'那'行动'那'biaslearnratefactor',0,'偏见',0)];%为演员设置一些选项Actoropts = RlRepresentationOptions('学习',1e-04,'gradientthreshold',1);%基于网络近似器创建ActorActor = RLDETerminyActorRepresentation(Actornetwork,Obsinfo,Actinfo,......'观察',{'状态'},'行动',{'行动'},actoropts);
指定代理选项,并使用环境,演员和批评者创建DDPG代理。
代理= rlddpgagentoptions(......'采样时间',env.ts,......'targetsmoothfactor',1e-3,......'经验BufferLength',1E6,......'贴花因子',0.99,......'minibatchsize',32);代理= rlddpgagent(演员,批评者,代理商);
检查您的代理人,使用努力从随机观察返回动作。
GetAction(代理,{rand(2,1)})
ans =.1x1细胞阵列{[-0.4719]}
您现在可以在环境中测试和培训代理人。
使用经常性神经网络创建DDPG代理
对于此示例,请加载示例中使用的环境火车DDPG代理控制双积分系统。从环境中观察是含有质量的位置和速度的载体。动作是表示连续测距的标量 -2至2牛顿。
Env = Rlpredefinedenv(“双凝胶组连续”);
获取观察和行动规范信息。
ObsInfo = GetobservationInfo(ENV);Actinfo = GetActionInfo(Env);
创造批评者代表。创建经常性神经网络,使用sequenceInputlayer.作为输入层并包括一个lstmlayer.作为其他网络层之一。
equentpath = sequenceInputlayer(ObsInfo.dimension(1),'正常化'那'没有任何'那'名称'那'myobs');ActionPath = sequenceInputLayer(Numel(ActInfo),'正常化'那'没有任何'那'名称'那“界面”);commonpath = [concatenationlayer(1,2,'名称'那'concat')剥离('名称'那'relu')LSTMLAYER(8,'OutputMode'那'顺序'那'名称'那'lstm')全康连接层(1,'名称'那'endicevalue'那'biaslearnratefactor',0,'偏见',0)];批判性=图表图(州路);批评网络= addlayers(批判性,ActionPath);批评网络= addlayers(批判性,commonpath);批评网络= ConnectLayers(批评者,'myobs'那'concat / In1');批评网络= ConnectLayers(批评者,“界面”那'concat / In2');
为评论家设置一些选择。
批评= rlrepresentationOptions('学习',5e-3,'gradientthreshold',1);
基于网络近似器创建批评者。
评论家= rlqvalueerepresentation(批评,undernfo,Actinfo,......'观察',{'myobs'},'行动',{“界面”},批评);
创建一个演员表示。
由于评论家有一个经常性网络,因此演员也必须具有经常性网络。为演员定义反复性神经网络。
ACTORNETWORK = [sequenceInputlayer(ObsInfo.dimension(1),'正常化'那'没有任何'那'名称'那'myobs')LSTMLAYER(8,'OutputMode'那'顺序'那'名称'那'lstm')全连接列(Numel(Actinfo),'名称'那“界面”那'biaslearnratefactor',0,'偏见',0)];
设置actor选项。
Actoropts = RlRepresentationOptions('学习',1e-04,'gradientthreshold',1);
创建演员。
Actor = RLDETerminyActorRepresentation(Actornetwork,Obsinfo,Actinfo,......'观察',{'myobs'},'行动',{“界面”},actoropts);
指定代理选项,并使用环境,演员和批评者创建DDPG代理。要使用具有复制神经网络的DDPG代理,您必须指定一个Sequencelength.大于1。
代理= rlddpgagentoptions(......'采样时间',env.ts,......'targetsmoothfactor',1e-3,......'经验BufferLength',1E6,......'贴花因子',0.99,......'sequencelength'20,......'minibatchsize',32);代理= rlddpgagent(演员,批评者,代理商);
检查您的代理人,使用努力从随机观察返回动作。
GetAction(代理,{ObsInfo.dimension})
ans =.1x1细胞阵列{[-0.1483]}
您现在可以在环境中测试和培训代理人。
也可以看看
深网络设计师|rlagentinitializationOptions.|rlddpgagentoptions.|RLDETerminyActorRepresentation|rlqvalueerepresentation
您还可以从以下列表中选择一个网站: