火车
在指定环境中列车加固学习代理
描述
例子
训练钢筋学习代理
中配置的代理火车PG代理可以平衡车杆系统示例,在相应的环境中。从环境中观察是载体包含推车的位置和速度,以及杆的角位置和速度。该动作是具有两个可能元素的标量(应用于推车的-10或10个牛顿的力)。
加载包含环境的文件和已为其配置的PG代理。
加载rltrainexample.mat.
使用一些培训参数使用rltringOptions.。这些参数包括训练的最大剧集数,每集的最大步骤以及终止训练的条件。在此示例中,每集使用最多1000个剧集和500个步骤。当前五个剧集的平均奖励达到500时,指示培训停止。创建默认选项集并使用点表示法来更改一些参数值。
训练= rltringOptions;训练.maxepisodes = 1000;训练.maxstepperepisode = 500;训练.StoptrainingCriteria =“平均”;trainOpts。StopTrainingValue = 500;trainOpts。ScoreAveragingWindowLength = 5;
在培训期间,火车命令可以保存给予良好结果的候选代理商。进一步配置培训选项以在剧集奖励超过500时保存代理。将代理保存到名为的文件夹救护人。
训练.SaveAgentCriteria =“EpisodeReward”;训练.SaveagentValue = 500;训练.SaveAgentDirectory =“Savedagents”;
最后,关闭命令行显示。打开Reinforcement Learning Episode Manager,这样您就可以直观地观察训练进度。
训练。verbose = false;训练.Plots =.“培训 - 进展”;
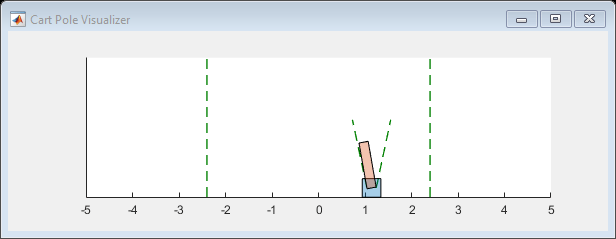
您现在准备训练PG代理商。对于在此示例中使用的预定义推车环境,您可以使用阴谋生成车杆系统的可视化。
情节(env)
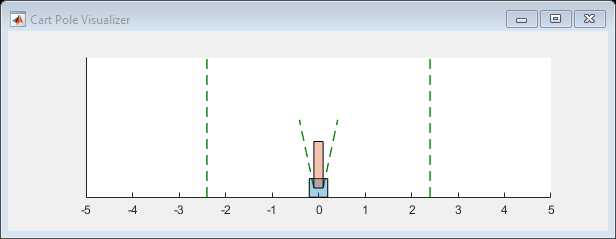
当您运行此示例时,可视化和Reinforcement Learning Episode Manager都会随着每个培训章节而更新。将它们并排放在屏幕上观察进程,并训练代理。(此计算可能需要20分钟或更长时间。)
trainingInfo =火车(代理,env, trainOpts);
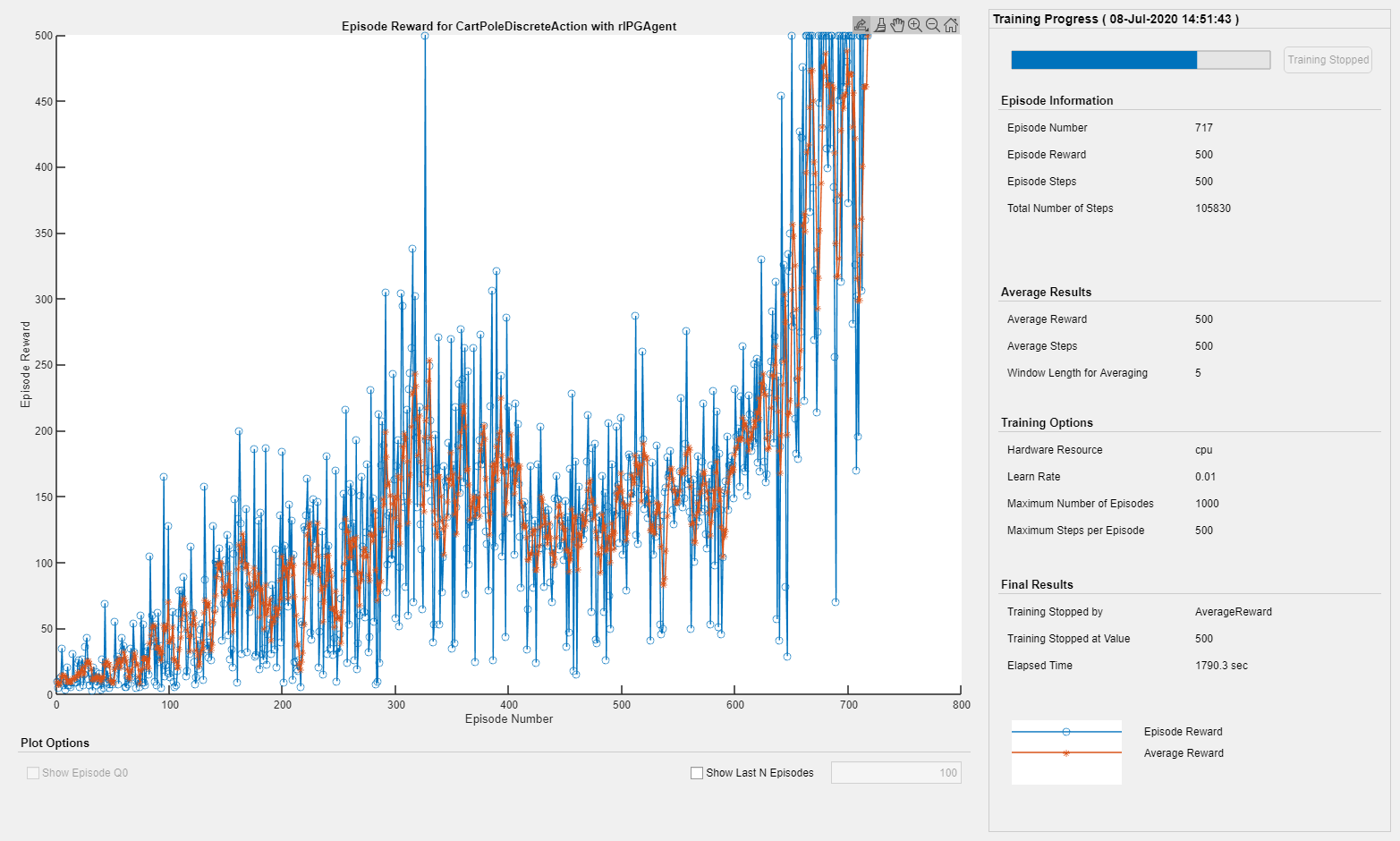
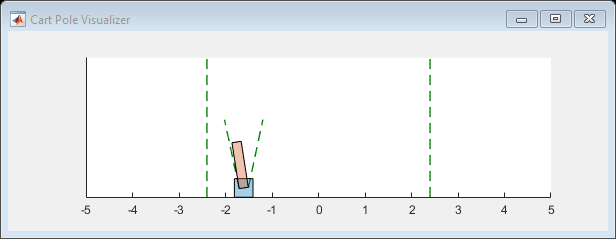
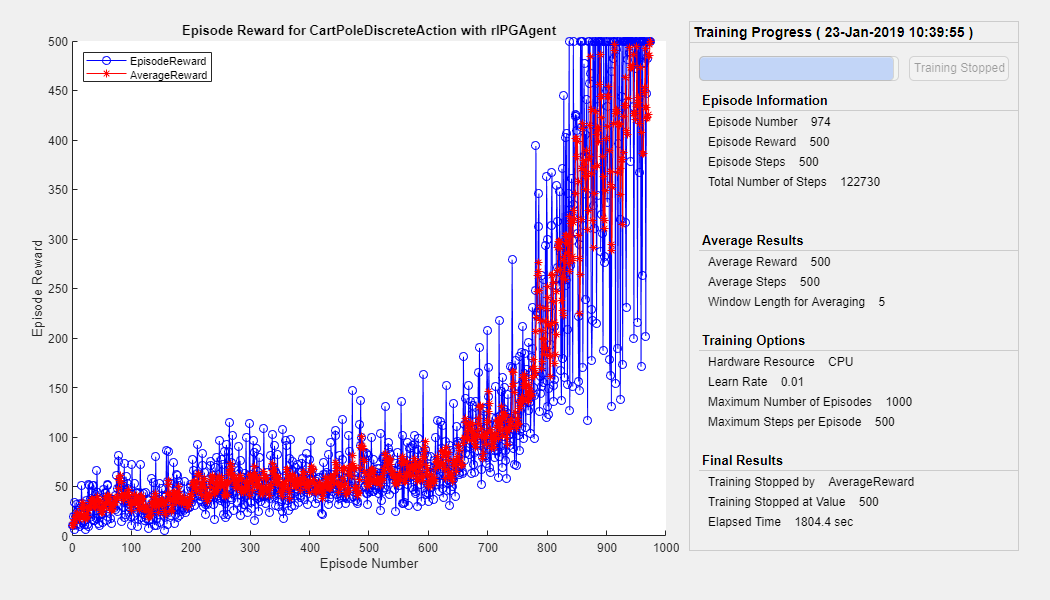
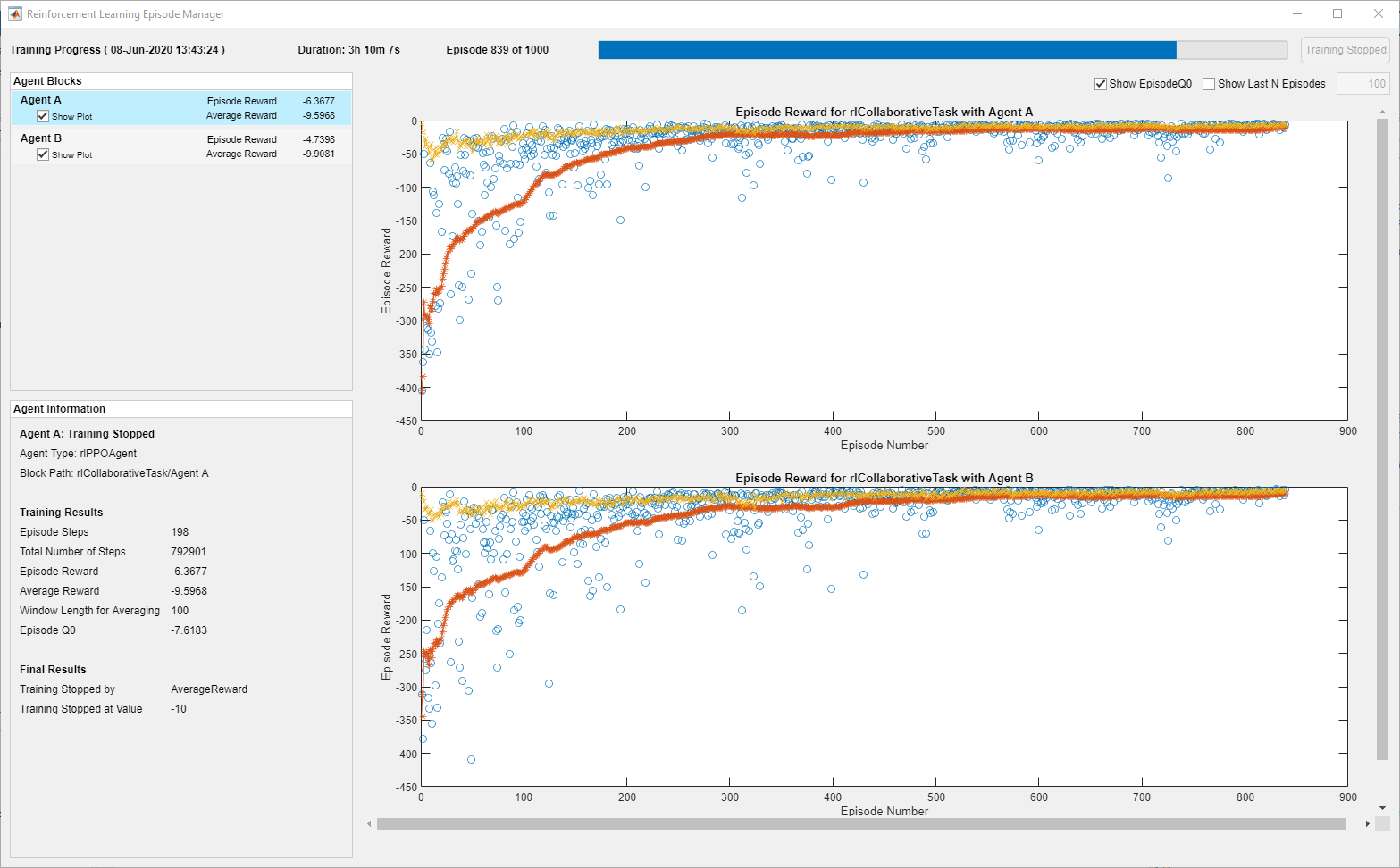
Episode Manager表明,培训成功达到了在前五个集中的500次奖励的终止条件。在每个训练集,火车更新代理人在上一个集中学习的参数。训练终止时,您可以使用培训的代理模拟环境以评估其性能。在培训期间,环境绘制在模拟期间更新。
simoptions = rlsimulation选项('maxsteps',500);体验= SIM(ENV,Agent,SimOptions);
培训期间,火车保存磁盘符合指定条件的代理RAPROOPS.SAVEAGENTCRITERA.和训练.SaveAgentValue.。要测试任何一种代理的性能,您可以从您指定的文件夹中的数据文件中加载数据训练.SaveAgentDirectory.,并使用该代理模拟环境。
培训多个代理商执行协作任务
这个例子展示了如何在Simulink®环境中设置多智能体培训课程。万博1manbetx在本例中,训练两个代理协作执行移动对象的任务。
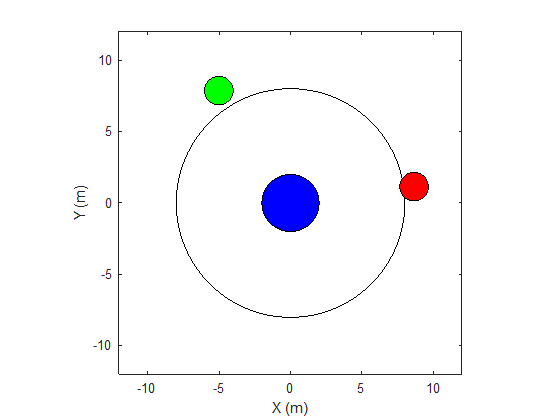
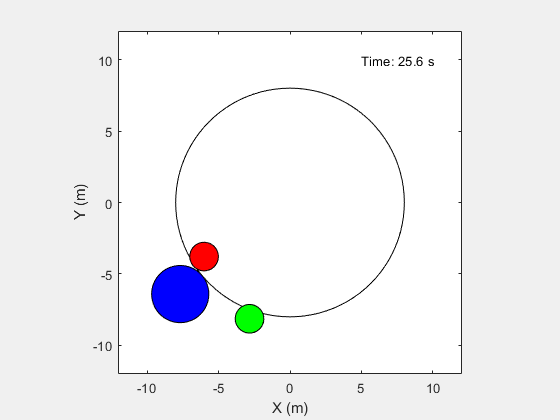
本例中的环境是一个无摩擦的二维表面,包含用圆表示的元素。目标物体C用半径为2米的蓝色圆圈表示,机器人A(红色)和B(绿色)用半径为1米的小圆圈表示。机器人试图通过碰撞施加力,将物体C移动到半径为8米的圆环外。环境中的所有元素都有质量,并遵循牛顿运动定律。此外,单元与环境边界之间的接触力被建模为弹簧和质量阻尼系统。这些元素可以通过在X和Y方向施加外力在表面上移动。在第三维中没有运动系统的总能量是守恒的。
创建此示例所需的参数集。
rlcollaborativetaskparams.
打开Simulin万博1manbetxk模型。
mdl =“rlcollaborativetask”;Open_System(MDL)
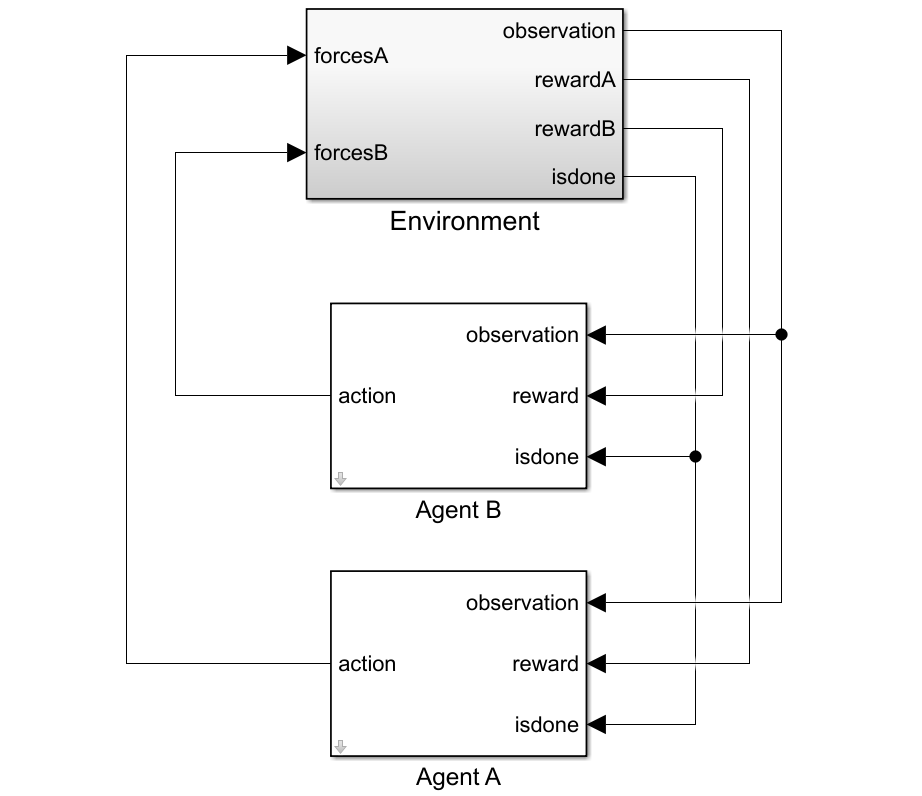
对于这个环境:
在x和y方向上,二维空间在-12μm到12μm中界定。
接触弹簧的刚度值为100n /m,阻尼值为0.1 N/m/s。
agent共享相同的位置、A、B、C的速度和上一次时间步长的动作值。
当物体C在圆环外移动时,模拟终止。
在每步,代理商都会收到以下奖励:
这里:
和 分别为代理A和代理B所获得的奖励。
是两个代理接收的团队奖励,因为对象C移动更接近环的边界。
和 是agent A和agent B所收到的局部惩罚,基于它们与物体C的距离和距离最后一个时间步骤的动作大小。
物体c从环的中心的距离。
和 是代理A和对象C和代理B和对象C之间的距离。
和 是来自最后一次步骤的代理A和B的动作值。
此示例使用具有离散动作空间的近端策略优化(PPO)代理。要了解有关PPO代理商的更多信息,请参阅近端政策优化代理。代理商在导致运动的机器人上应用外力。每次步骤,代理都选择动作 ,在那里 是以下是外部应用力的以下成对之一。
创建环境
要创建多代理环境,请使用字符串数组指定代理的块路径。此外,使用单元阵列指定观察和操作规范对象。单元格数组中规范对象的顺序必须与块路径阵列中指定的顺序匹配。当在环境创建时的Matlab工作空间中可用代理时,观察和操作规范阵列是可选的。有关创建多代理环境的更多信息,请参阅Rl万博1manbetxsimulinkenv.。
为环境创建I/O规格。在本例中,代理是同构的,具有相同的I/O规范。
%观察数numobs = 16;%行动数量numact = 2;%最大外力值(N)maxF = 1.0;每个代理的I / O规范oinfo = rlnumericspec([numobs,1]);ainfo = rlfinitesetspec({[-maxf -maxf] [-maxf 0] [-maxf maxf] [0 -maxf] [0 0 0] [0 maxf] [maxf -maxf] [maxf 0] [maxf maxf]};oinfo.name =.“观察”;ainfo.name =.“力量”;
创建Simulink环万博1manbetx境接口。
Blks = [“rlcollaborativetask /代理A”那“rlcollaborativetask /代理b”];Obsinfos = {oinfo,oinfo};Actinfos = {AINFO,AINFO};Env = Rl万博1manbetxsimulinkenv(MDL,BLK,OBSINFOS,ACTINFOS);
为环境指定重置函数。重置功能重新汲取确保机器人从每个集发作开始的随机初始位置开始。
env.resetfcn = @(in)Resetrobots(在,RA,RB,RC,边界);
创造代理人
PPO代理人依靠演员和批评者表示来学习最佳政策。在该示例中,代理能够为演员和评论家维持基于神经网络的函数近似器。
创建批评神经网络和表示。批评网络的输出是状态值函数 对于国家 。
%重置随机种子以提高再现性RNG(0)%批评网络批评= [......FeatureInputLayer(oinfo.dimension(1),“归一化”那'没有任何'那'名称'那“观察”)全连接列(128,'名称'那'批判福尔'那'掌控itializer'那'他')剥离('名称'那'rictrelu1')全连接层(64,'名称'那'批判性]那'掌控itializer'那'他')剥离('名称'那“CriticRelu2”)全连接列(32,'名称'那'批判液3'那'掌控itializer'那'他')剥离('名称'那“CriticRelu3”) fullyConnectedLayer (1,'名称'那'批评')];%批评意见批评= rlrepresentationOptions('学习',1E-4);批评= rlvaluerepresentation(批判性,oinfo,'观察',{“观察”},批评);批评= rlvalueerepresentation(批评,oinfo,'观察',{“观察”},批评);
actor网络的输出是概率 在某个状态下采取每个可能的行动对 。创建演员神经网络和表示。
%演员网络actorNetwork = [......FeatureInputLayer(oinfo.dimension(1),“归一化”那'没有任何'那'名称'那“观察”)全连接列(128,'名称'那'actorfc1'那'掌控itializer'那'他')剥离('名称'那'ACTORRELU1')全连接层(64,'名称'那'Actorfc2'那'掌控itializer'那'他')剥离('名称'那'ACTORRELU2')全连接列(32,'名称'那'Actorfc3'那'掌控itializer'那'他')剥离('名称'那'ACTORRELU3')全连接列(numel(ainfo.elements),'名称'那'行动')softmaxlayer('名称'那“sm”)];%演员表示Actoropts = RlRepresentationOptions('学习',1E-4);Actora = rlstochasticRoreEntentation(Actornetwork,Oinfo,Ainfo,......'观察',{“观察”},actoropts);Actorb = rlstochasticRoreEntation(Actornetwork,Oinfo,Ainfo,......'观察',{“观察”},actoropts);
创建代理商。两个代理商都使用相同的选项。
代理选项= rlppoagentoptions(......'经验热诚',256,......“ClipFactor”, 0.125,......'entropylossweight',0.001,......“MiniBatchSize”,64,......'numechoch',3,......'vieildereextimatemethod'那'gae'那......'Gafactor',0.95,......“SampleTime”,ts,......'贴花因子', 0.9995);agentA = rlPPOAgent (actorA criticA agentOptions);agentB = rlPPOAgent (actorB criticB agentOptions);
在培训期间,代理商收集经验,直到达到256个步骤或摘要的体验视界,然后从迷你批次的64个经验中培训。此示例使用0.125的客观函数剪辑因子,以提高培训稳定性和0.9995的折扣因子,以鼓励长期奖励。
培训代理商
指定以下培训代理人的培训选项。
运行大多数1000次剧集的培训,每个集发作持续最多5000个时间步长。
当一个代理的平均奖励超过100个连续事件是-10或更多时停止训练。
maxEpisodes = 1000;maxSteps = 5 e3;trainOpts = rlTrainingOptions (......'maxepisodes',maxepisodes,......'maxstepperepisode',maxsteps,......'scoreaveragingwindowlength',100,......'plots'那'培训 - 进步'那......'stoptrinaincriteria'那“AverageReward”那......'stoptriningvalue',-10);
要训练多个代理,请指定一个代理数组火车功能。数组中的代理顺序必须匹配环境创建期间指定的代理块路径的顺序。这样做可确保代理对象链接到环境中的适当I / O接口。培训这些代理人可能需要几个小时才能完成,具体取决于可用的计算能力。
垫文件rlCollaborativeTaskAgents包含一组预制代理。您可以加载文件并查看代理的性能。训练代理人,套装用圆形到真的。
dotraining = false;如果dotraining stats =火车([Agenta,Agentb],Env,训练);别的加载('rlcollaborativetaskagents.mat');结尾
下图显示了培训进度的快照。由于培训过程中的随机性,您可以期待不同的结果。
模拟代理
模拟环境中的训练有素的代理。
simoptions = rlsimulation选项('maxsteps',maxsteps);exp = sim(env,[Agenta Agentb],SimOptions);
有关代理模拟的更多信息,请参阅RlsimulationOptions.和SIM。
输入参数
输出参数
提示
火车在培训进展时更新代理商。要保留原始代理参数以供稍后使用,请将代理保存到MAT文件。默认情况下,调用
火车打开钢筋学习剧集管理器,允许您可视化培训的进度。Episode Manager Plot显示每个剧集,运行平均奖励价值和批评估计的奖励问:0.(对于具有批评者的代理人)。Episode Manager还显示各种剧集和培训统计数据。要关闭钢筋学习剧集管理器,请设置情节选择训练到“没有任何”。如果您使用有可视化的预定义环境,则可以使用
情节(env)可视化环境。如果你打电话情节(env)在培训之前,然后在培训期间可视化更新,允许您可视化每个集的进度。(对于自定义环境,必须实现自己的环境阴谋方法。)培训在规定的条件时终止
训练满意。要终止正在进行的培训,请在加强学习集团管理器中,单击停止培训。因为火车在每个集中更新代理,您可以通过呼叫恢复培训火车(代理人,env,训练)同样,在第一次呼叫期间没有丢失训练有素的参数火车。在培训期间,您可以保存满足指定条件的候选代理
训练。例如,即使尚未满足终止培训的整体条件,您还可以保存剧集奖励超出某个值的任何代理。火车将保存的代理存储在您指定的文件夹中的MAT文件中训练。例如,已保存的代理可能有用,以允许您在长期运行培训过程中测试生成的候选代理。有关保存标准和保存位置的详细信息,请参阅rltringOptions.。
算法
一般来说,火车执行以下迭代步骤:
初始化
代理人。对于每一次集:
重置环境。
获得初始观察S.0.来自环境。
计算初始操作一种0.=μ.(S.0.)。
将当前操作设置为初始操作(一种←一种0.)并将当前观察设置为初始观察(S.←S.0.)。
虽然剧集未完成或终止:
使用动作步骤环境一种获得下一个观察S.'和奖励R.。
从体验集中学习(S.那一种那R.那S.')。
计算下一个动作一种'=μ.(S.')。
使用下一个操作更新当前操作(一种←一种'),并将当前的观测值更新为下一个观测值(S.←S.')。
如果满足环境中定义的剧集终端条件,则打破。
如果训练终止条件定义
训练满足,终止培训。否则,开始下一个剧集。
具体情况火车执行这些计算取决于您的代理和环境的配置。例如,如果配置环境,则重置每个剧集开始时的环境可以包括随机化初始状态值。
扩展功能
您还可以从以下列表中选择一个网站: