生成奖励函数模型预测控制器的伺服电动机
这个例子展示了如何自动生成一个奖励函数从成本和约束规范中定义一个模型预测控制器对象。然后使用生成的回报函数训练强化学习代理。
介绍
您可以使用generateRewardFunction生成一个奖励函数强化学习,从成本和约束中指定一个模型预测控制器。得到的奖励信号是一笔费用(定义的目标函数)和约束违反处罚根据环境的当前状态。
这个例子是基于直流伺服电动机与约束在无边无际的输出(模型预测控制工具箱)例子,你设计一个模型预测控制器的直流电压和轴转矩约束下伺服机构。在这里,您将转换成本和约束规范中定义的货币政策委员会对象到一个奖励功能,用它来训练一个代理控制伺服电动机。
打开这个例子的仿真万博1manbetx软件模型基于上述MPC但已经修改了强化学习的例子。
open_system (“rl_motor”)



创建模型预测控制器
创建电动机的开环动态模型中定义的植物和最大容许扭矩τ使用一个helper函数。
(植物、τ)= mpcmotormodel;
指定输入和输出信号类型MPC控制器。轴角位置,测量第一输出。第二个输出扭矩,是无法计量的。
植物= setmpcsignals(植物,“MV”,1“莫”,1“UO”2);
在操纵变量指定约束,定义一个比例因子。
MV =结构(“最小值”,-220,“马克斯”,220,“ScaleFactor”,440);
施加扭矩限制在前三个预测步骤,并指定比例因子轴位置和扭矩。
OV =结构(“最小值”,{负无穷变化,τ,τ;τ;负)},…“马克斯”,{正无穷,τ;τ,τ;正]},…“ScaleFactor”,{2π* 2 *τ});
为二次成本函数指定权重来实现角位置跟踪。设置为零转矩的重量,从而让它浮在其约束。
重量=结构(“MV”0,“MVRate”,0.1,机汇的,0.1 [0]);
创建一个MPC控制器植物模型与样本的时间0.1年代,预测地平线10步骤和控制的地平线2步骤,使用前面定义的结构重量,操纵变量和输出变量。
mpcobj = mpc(植物,0.1,10、2、重量、MV, OV);
显示控制器的规格。
mpcobj
MPC对象(01 - 9 - 2021上创建14:18:45):- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -采样时间:0.1(秒)预测地平线:10控制层:2植物模型:- - - - - - - - - - - - - - - - 1操纵变量(s) - - > | 4州| | | - - > 1测量输出(s) 0测量扰动(s) - - >输入| 1 | | | - - > 1无边无际的输出(s) 0无边无际的干扰(s) - - > | | 2输出- - - - - - - - - - - - - - - -指数:(输入向量)操纵变量:[1](输出向量)测量输出:[1]无边无际的输出:[2]干扰和噪声模型:输出扰动模型:默认(类型”getoutdist (mpcobj)”)测量噪声模型:默认(缩放后单位增益)重量:ManipulatedVariables: 0 ManipulatedVariablesRate: 0.1000 OutputVariables: 0.1000 [0] ECR: 10000状态估计:默认的卡尔曼滤波器类型(“getEstimator (mpcobj)”)约束:-220 < = 1/2 MV1 (V) < = 220, 1/2 MV1 /速度(V)是无约束,MO1 (rad)无约束-78.54 < = UO1 (Nm) (t + 1) < = 78.54 - -78.54 < = UO1 (Nm) (t + 2) < = 78.54 - -78.54 < = UO1 (Nm) (t + 3) < = 78.54 UO1 (Nm) (t + 4)是不受限制
控制器作用于植物4州,1输入(电压)和2输出信号(角和扭矩)和具有以下规格:
成本函数为被控变量权重,被控变量率和输出变量是0,分别为0.1和0.1 [0]。
被操纵的变量约束-220 v和220 v之间。
被控变量率不受限制。
第一个输出变量(角)是不受约束的,但第二个(转矩)是限制在-78.54和78.54 Nm之间在前三个预测时间在第四步步骤和无约束。
注意,对于强化学习唯一的约束规范预测时间的第一步将使用自奖励计算一个时间步。
生成奖励函数
生成奖励函数代码的规范货币政策委员会对象使用generateRewardFunction。在MATLAB编辑器中显示的代码。
generateRewardFunction (mpcobj)
生成的奖励奖励设计函数是一个起点。您可以修改函数不同的罚函数的选择和调整权重。对于这个示例,对所生成的代码进行以下更改:
规模的原始成本权重
Qy,Qmv和Qmvrate了100倍。默认的外部罚函数方法
一步。改变的方法二次。
更改后,成本和惩罚规范应该如下:
Qy = (10 0);Qmv = 0;Qmvrate = 10;Py =王寅* exteriorPenalty (y, ymin ymax,“二次”);Pmv = Wmv * exteriorPenalty (mv, mvmin mvmax,“二次”);Pmvrate = Wmvrate * exteriorPenalty (mv-lastmv、mvratemin mvratemax,“二次”);
对于这个示例,修改后的代码已经被保存在文件的MATLAB函数rewardFunctionMpc.m。显示生成的回报函数。
类型rewardFunctionMpc.m
函数奖励= rewardFunctionMpc (y, refy, mv, refmv lastmv) % rewardFunctionMpc从MPC规范产生回报。% % % %的描述输入参数:y:输出变量从植物k + 1% refy步:参考输出变量k + 1% mv步:被控变量在k % refmv步:参考被控变量在k % lastmv步:被控变量在k - 1步% %的局限性(MPC和NLMPC): % -奖励计算基于预测地平线的第一步。%因此,信号预览和控制层设置将被忽略。%,不支持在线更新成本和约束。万博1manbetx% - - - - - -自定义不考虑成本和约束规范。%——时变不支持重量和成本约束。万博1manbetx% -混合约束规范不考虑(MPC)。%强化学习工具箱% 02 - jun - 2021 16:05:41 % # codegen从MPC对象% % %规范标准线性范围规定‘州’,‘OutputVariables’,和%的ManipulatedVariables属性ymin =(负-78.5398163397448);ymax = 78.5398163397448[正];mvmin = -220; mvmax = 220; mvratemin = -Inf; mvratemax = Inf; % Scale factors as specified in 'States', 'OutputVariables', and % 'ManipulatedVariables' properties Sy = [6.28318530717959 157.07963267949]; Smv = 440; % Standard cost weights as specified in 'Weights' property Qy = [0.1 0]; Qmv = 0; Qmvrate = 0.1; %% Compute cost dy = (refy(:)-y(:)) ./ Sy'; dmv = (refmv(:)-mv(:)) ./ Smv'; dmvrate = (mv(:)-lastmv(:)) ./ Smv'; Jy = dy' * diag(Qy.^2) * dy; Jmv = dmv' * diag(Qmv.^2) * dmv; Jmvrate = dmvrate' * diag(Qmvrate.^2) * dmvrate; Cost = Jy + Jmv + Jmvrate; %% Penalty function weight (specify nonnegative) Wy = [1 1]; Wmv = 10; Wmvrate = 10; %% Compute penalty % Penalty is computed for violation of linear bound constraints. % % To compute exterior bound penalty, use the exteriorPenalty function and % specify the penalty method as 'step' or 'quadratic'. % % Alternatively, use the hyperbolicPenalty or barrierPenalty function for % computing hyperbolic and barrier penalties. % % For more information, see help for these functions. % % Set Pmv value to 0 if the RL agent action specification has % appropriate 'LowerLimit' and 'UpperLimit' values. Py = Wy * exteriorPenalty(y,ymin,ymax,'step'); Pmv = Wmv * exteriorPenalty(mv,mvmin,mvmax,'step'); Pmvrate = Wmvrate * exteriorPenalty(mv-lastmv,mvratemin,mvratemax,'step'); Penalty = Py + Pmv + Pmvrate; %% Compute reward reward = -(Cost + Penalty); end
集成这个奖励功能,打开MATLAB仿真软件模型中的功能块。万博1manbetx
open_system (“rl_motor /奖励函数”)
附加功能使用以下代码并保存模型。
r = rewardFunctionMpc (y, refy, mv, refmv lastmv);
MATLAB功能块将执行rewardFunctionMpc.m在模拟。
对于这个示例,MATLAB功能块已经修改并保存。
创造一个强化学习环境
环境动力学建模伺服机构子系统。对于这个环境,
观察是参考和实际输出变量(角和扭矩)从去年8次步骤。
行动是电压 应用于伺服电动机。
样品时间是 。
仿真时间 。
指定仿真总时间和样品时间。
Tf = 20;t = 0.1;
对环境创建的观察和操作规范。
numObs = 32;numAct = 1;oinfo = rlNumericSpec ([numObs 1]);ainfo = rlNumericSpec (numAct [1],“LowerLimit”,-220,“UpperLimit”,220);
创建使用强化学习环境rl万博1manbetxSimulinkEnv函数。
env = rl万博1manbetxSimulinkEnv (“rl_motor”,“rl_motor / RL代理”、oinfo ainfo);
创建一个强化学习代理
修复再现性的随机种子。
rng (0)
代理在本例中是一个双延迟深决定性策略梯度(TD3)代理。
创建两个评论家表示。
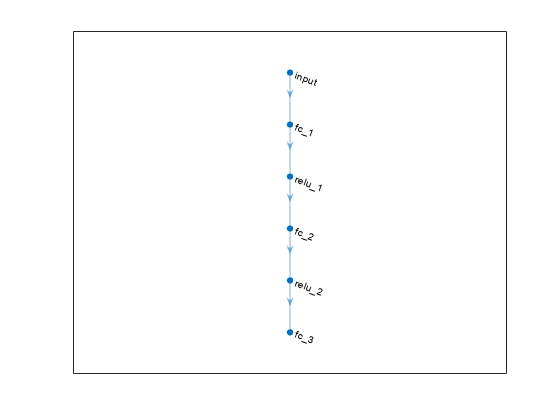
%的批评家cnet = [featureInputLayer numObs,“归一化”,“没有”,“名字”,“状态”)fullyConnectedLayer (128,“名字”,“fc1”)concatenationLayer (1、2、“名字”,“concat”)reluLayer (“名字”,“relu1”)fullyConnectedLayer (64,“名字”,“一个fc3”文件)reluLayer (“名字”,“relu2”)fullyConnectedLayer (1,“名字”,“CriticOutput”));actionPath = [featureInputLayer numAct,“归一化”,“没有”,“名字”,“行动”)fullyConnectedLayer (8,“名字”,“取得”));criticNetwork = layerGraph (cnet);criticNetwork = addLayers (criticNetwork actionPath);criticNetwork = connectLayers (criticNetwork,“取得”,“concat / in2”);criticOptions = rlRepresentationOptions (“LearnRate”1 e - 3,“GradientThreshold”1);摘要= rlQValueRepresentation (criticNetwork oinfo ainfo,…“观察”,{“状态”},“行动”,{“行动”},criticOptions);critic2 = rlQValueRepresentation (criticNetwork oinfo ainfo,…“观察”,{“状态”},“行动”,{“行动”},criticOptions);
创建一个演员表示。
actorNetwork = [featureInputLayer numObs,“归一化”,“没有”,“名字”,“状态”)fullyConnectedLayer (128,“名字”,“actorFC1”)reluLayer (“名字”,“relu1”)fullyConnectedLayer (64,“名字”,“actorFC2”)reluLayer (“名字”,“relu2”)fullyConnectedLayer (numAct“名字”,“行动”));actorOptions = rlRepresentationOptions (“LearnRate”1 e - 3,“GradientThreshold”1);演员= rlDeterministicActorRepresentation (actorNetwork oinfo ainfo,…“观察”,{“状态”},“行动”,{“行动”},actorOptions);
使用指定代理选项rlTD3AgentOptions。代理列车从一种体验缓冲区的最大容量1 e6通过随机选择mini-batches的大小256年。折现系数0.995有利于长期的回报。
agentOpts = rlTD3AgentOptions (“SampleTime”Ts,…“DiscountFactor”,0.995,…“ExperienceBufferLength”1 e6,…“MiniBatchSize”,256);
探索在这个TD3代理是高斯模型。噪声模型添加一个统一的随机值的动作在训练。设置噪声的标准差One hundred.。标准差的速度衰减1 e-5每剂一步到的最小值0.005。
agentOpts.ExplorationModel。StandardDeviationMin = 0.005;agentOpts.ExplorationModel。StandardDeviation = 100;agentOpts.ExplorationModel。StandardDeviationDecayRate = 1 e-5;
创建TD3代理使用演员和评论家表示。TD3代理的更多信息,请参阅rlTD3Agent。
代理= rlTD3Agent(演员,[摘要,critic2], agentOpts);
火车代理
培训代理商,首先使用指定培训选项rlTrainingOptions。对于这个示例,使用以下选项:
运行每个培训最多2000集,每集持久的最多
装天花板(Tf / Ts)时间的步骤。停止训练当代理接收到平均累积奖励大于
2在20.连续集。在这一点上,代理可以跟踪参考信号。
trainOpts = rlTrainingOptions (…“MaxEpisodes”,2000,…“MaxStepsPerEpisode”装天花板(Tf / Ts),…“StopTrainingCriteria”,“AverageReward”,…“StopTrainingValue”2,…“ScoreAveragingWindowLength”,20);
火车代理使用火车函数。培训这个代理是一个计算密集型的过程可能需要几分钟才能完成。节省时间在运行这个例子中,加载一个pretrained代理设置doTraining来假。训练自己代理,集doTraining来真正的。
doTraining = false;如果doTraining trainingStats =火车(代理,env, trainOpts);其他的负载(“rlDCServomotorTD3Agent.mat”)结束
培训的快照进步是如下图所示。你可以期待不同的结果由于训练过程中固有的随机性。




验证控制器响应
验证培训代理的性能,模拟模型和视图的响应范围块。强化学习代理能够跟踪参考角而满足约束力矩和电压。
sim卡(“rl_motor”);




 关闭模式。
关闭模式。
close_system (“rl_motor”)
版权2021年MathWorks公司. .