拉卡金特
行动者-批评家强化学习代理
描述
行为者-批评(AC)代理实现行为者-批评算法,如A2C和A3C,这是无模型的、在线的、基于政策的强化学习方法。行动者-评论家代理直接优化策略(行动者),并使用评论家来估计回报或未来的回报。动作空间可以是离散的,也可以是连续的。
有关详细信息,请参阅Actor-Critic代理。有关不同类型强化学习代理的更多信息,请参阅强化学习代理.
创造
语法
描述
根据观察和操作规范创建代理
代理人= rlACAgent (观测信息,行动信息,初始选项)初始选项对象。行动者-评论家代理不支持递归神经网络。万博1manbetx有关初始化选项的更多信息,请参见rlAgentInitializationOptions.
输入参数
性质
对象的功能
例子
根据观察和行动规范创建离散的参与者-批评家代理
创建具有离散动作空间的环境,并获取其观察和动作规范。对于本例,加载示例中使用的环境使用Deep Network Designer创建代理并使用图像观察进行培训.这个环境有两个观测值:一个50乘50的灰度图像和一个标量(钟摆的角速度)。这个动作是一个标量,有五个可能的元素(一个扭矩是-2, -1,0,1,或2Nm适用于摆动杆)。
%加载预定义的环境env = rlPredefinedEnv (“SimplePendulumWithImage-Discrete”);%获得观察和行动规范obsInfo=获取观测信息(env);actInfo=getActionInfo(env);
代理创建函数随机初始化演员和评论家网络。您可以通过固定随机生成器的种子来确保再现性。为此,请取消对以下行的注释。
%rng(0)
根据环境观察和行动规范创建一个演员-评论家代理。
agent=rlACAgent(obsInfo、actInfo);
要检查您的代理,请使用getAction从随机观察返回操作。
getAction(代理,{兰特(obsInfo (1) .Dimension),兰德(obsInfo (2) .Dimension)})
ans =1x1单元阵列{[2]}
现在可以在环境中测试和培训代理。
使用初始化选项创建连续的参与者-评论家代理
创造一个具有连续动作空间的环境,并获得其观察和动作规范。对于本示例,请加载示例中使用的环境通过图像观察训练DDPG药剂摆动和平衡摆锤.这个环境有两个观测值:一个50乘50的灰度图像和一个标量(钟摆的角速度)。这个作用是一个标量,表示从-连续范围的扭矩2到2Nm。
%加载预定义的环境env = rlPredefinedEnv (“SimplePendulumWithImage-Continuous”);%获得观察和行动规范obsInfo=获取观测信息(env);actInfo=getActionInfo(env);
创建一个代理初始化选项对象,指定网络中每个隐藏的完全连接层必须具有128神经元(而不是默认数量,256).Actor批评家代理不支持重复网络,因此设置万博1manbetxUseRNN选择真正的在创建代理时生成错误。
initOpts=rlagentinizationoptions(“NumHiddenUnit”, 128);
代理创建函数随机初始化演员和评论家网络。您可以通过固定随机生成器的种子来确保再现性。为此,请取消对以下行的注释。
%rng(0)
根据环境观察和行动规范创建一个演员-评论家代理。
代理= rlACAgent (obsInfo actInfo initOpts);
将批评家学习率降低到1e-3。
批评家=Get批评家(代理);critic.Options.LearnRate=1e-3;agent=set批评家(agent,批评家);
从agent参与者和批评家中提取深层神经网络。
actorNet=getModel(getActor(agent));criticNet=getModel(getCritic(agent));
显示批评网络的各层,并验证每个隐藏的全连接层有128个神经元
criticNet。层
ans=12x1带层的层阵列:1“concat”沿维度2个输入的串联3“relu_body”relu relu 3“fc_body”完全连接128个完全连接的层4“body_输出”relu relu 5“input_1”图像输入50x50x1图像6“conv_1”卷积64 3x1x1带跨步[1]和填充的卷积[0 0 0 0 0]7“relu_输入_1”relu relu 8“fc_1”完全连接128完全连接层9“input_2”图像输入1x1x1图像10“fc_2”完全连接128完全连接层11“output”完全连接1完全连接层12“RepresentationLoss”回归输出均方误差
情节演员和评论家网络
情节(actorNet)
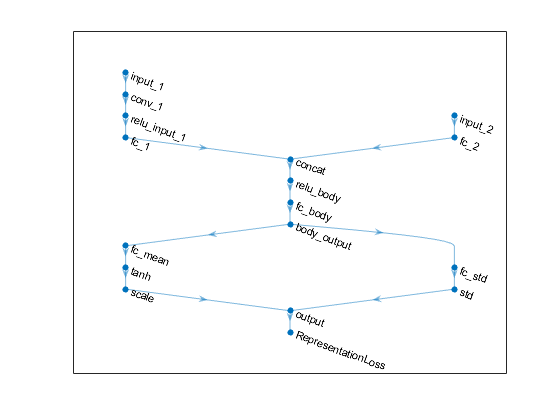
情节(criticNet)

要检查您的代理,请使用getAction从随机观察返回操作。
getAction(代理,{兰特(obsInfo (1) .Dimension),兰德(obsInfo (2) .Dimension)})
ans =1x1单元阵列{[0.9228]}
现在可以在环境中测试和培训代理。
从演员和评论家中创建离散的演员-评论家代理
创建具有离散动作空间的环境,并获取其观察和动作规范。对于本例,加载示例中使用的环境培训DQN代理以平衡大车杆系统。该环境具有四维观测向量(小车位置和速度、极角和极角导数)和具有两个可能元素(任意一个力)的标量作用-10或+10N应用在购物车上)。
%加载预定义的环境env = rlPredefinedEnv (“CartPole离散型”);获得观察规范obsInfo = getObservationInfo (env)
obsInfo=rlNumericSpec,属性:LowerLimit:-Inf上限:Inf名称:“CartPole状态”说明:“x、dx、θ、dtheta”维度:[4 1]数据类型:“双”
获得动作规格actInfo = getActionInfo (env)
actInfo=rlFiniteSetSpec,属性为:元素:[-10 10]名称:“CartPole操作”说明:[0x0字符串]维度:[1]数据类型:“双”
代理创建函数随机初始化演员和评论家网络。您可以通过固定随机生成器的种子来确保再现性。为此,请取消对以下行的注释。
%rng(0)
创建一个评论家表示。
%在批评家中创建网络作为近似器使用%必须具有四维输入(4个观察值)和标量输出(值)[imageInputLayer([4 1 1],]),“正常化”,“没有”,“名字”,“状态”)完全连接层(1,“名字”,“CriticFC”));为评论家设置选项criticOpts = rlRepresentationOptions (“LearnRate”, 8 e - 3,“GradientThreshold”1);%创建评论家(演员评论家代理使用值函数表示)评论家= rlValueRepresentation (criticNetwork obsInfo,“观察”,{“状态”}, criticOpts);
创建一个参与者表示。
%创建网络以用作参与者中的近似器%必须具有4维输入和2维输出(操作)[imageInputLayer([4 1 1],]),“正常化”,“没有”,“名字”,“状态”)完全连接层(2,“名字”,“行动”));%为演员设置选项actorOpts = rlRepresentationOptions (“LearnRate”, 8 e - 3,“GradientThreshold”1);%创建行动者(行动者-评论家行动者使用随机行动者表示)演员= rlStochasticActorRepresentation (actorNetwork obsInfo actInfo,...“观察”,{“状态”}, actorOpts);
指定代理选项,并使用参与者、评论家和代理选项对象创建AC代理。
agentOpts = rlACAgentOptions (“NumStepsToLookAhead”32岁的“DiscountFactor”, 0.99);代理= rlACAgent(演员、评论家、agentOpts)
agent=rlACAgent,具有以下属性:AgentOptions:[1x1 rl.option.rlACAgentOptions]
要检查您的代理,请使用getAction从随机观察返回操作。
getAction(代理,{rand(4,1)})
ans =1x1单元阵列{[-10]}
现在可以在环境中测试和培训代理。
从演员和评论家创建连续的演员-评论家代理
创建一个具有连续行动空间的环境,并获取其观察和行动规范。对于本例,加载示例中使用的双积分连续动作空间环境培训DDPG Agent控制双积分系统.
%加载预定义的环境env = rlPredefinedEnv (“双积分连续”);获得观察规范obsInfo = getObservationInfo (env)
obsInfo=rlNumericSpec,属性:LowerLimit:-Inf上限:Inf名称:“状态”说明:“x,dx”维度:[2 1]数据类型:“双”
获得动作规格actInfo = getActionInfo (env)
actInfo=rlNumericSpec,属性:LowerLimit:-Inf上限:Inf名称:“强制”说明:[0x0字符串]维度:[1]数据类型:“双”
在本例中,动作是一个标量输入,表示范围为-的力2到2因此,相应地设定动作信号的上下限是个好主意。当参与者的网络表示具有非线性输出层,需要相应地进行缩放以产生期望范围内的输出时,就必须这样做。
%确保动作空间的上限和下限是有限的actInfo.LowerLimit=-2;actInfo.UpperLimit=2;
演员和评论家网络是随机初始化的。您可以通过修复随机生成器的种子来确保再现性。为此,请取消注释以下行。
%rng(0)
创建一个评论家表示。演员-评论家代理使用rlValueRepresentation对于批评家。对于连续观测空间,可以使用深度神经网络或自定义基表示。对于本例,创建深度神经网络作为基础近似器。
%在批评家中创建网络作为近似器使用它必须以观测信号为输入,并产生一个标量值[errorcode] [errorcode]错误码尺寸1],“正常化”,“没有”,“名字”,“状态”) fullyConnectedLayer (10“名字”,"fc_in") reluLayer (“名字”,“relu”)完全连接层(1,“名字”,“出”));为评论家设置一些训练选项criticOpts = rlRepresentationOptions (“LearnRate”, 8 e - 3,“GradientThreshold”1);%从网络中创建批评家表示评论家=rlValueRepresentation(评论家网、obsInfo、,“观察”,{“状态”}, criticOpts);
演员-评论家代理使用随机表示.对于在连续动作空间中操作的随机参与者,只能使用深度神经网络作为潜在的近似器。
观察输入(这里称为myobs)必须接受二维向量,如obsInfo.输出(这里称为myact)也必须是一个二维向量(是肌动蛋白).输出向量的元素依次表示每个动作的所有平均值和所有标准偏差(在本例中,只有一个平均值和一个标准偏差)。
事实上,标准差必须是非负的,而平均值必须落在输出范围内,这意味着网络必须有两个独立的路径。第一个路径是针对平均值的,任何输出非线性必须进行缩放,以便它能在输出范围内产生输出。第二种方法是标准偏差,必须使用软加或ReLU层来强制非负性。
%输入路径层(2×1输入和1×1输出)inPath = [imageInputLayer([obsInfo. inPath])]尺寸1],“正常化”,“没有”,“名字”,“状态”) fullyConnectedLayer (10“名字”,“ip_fc”)%10乘1输出reluLayer (“名字”,“伊普雷鲁”)%非线性fullyConnectedLayer (1,“名字”,“ip_out”) ];% 1乘1输出%路径层的平均值(1乘1输入和1乘1输出)%使用scalingLayer缩放范围meanPath=[fullyConnectedLayer(15,“名字”,“mp_fc1”)% 15 × 1输出reluLayer (“名字”,“mp_relu”)%非线性fullyConnectedLayer (1,“名字”,“mp_fc2”);% 1乘1输出tanhLayer (“名字”,的双曲正切);%输出范围:(-1,1)scalingLayer (“名字”,“mp_out”,“规模”actInfo.UpperLimit)];%输出范围:(-2N,2N)%路径层的标准偏差(1 × 1输入和输出)%使用softplus图层使输出为非负sdevPath=[fullyConnectedLayer(15,“名字”,“vp_fc1”)% 15 × 1输出reluLayer (“名字”,“vp_relu”)%非线性fullyConnectedLayer (1,“名字”,“vp_fc2”);% 1乘1输出softplusLayer (“名字”,“vp_out”) ];%输出范围:(0,+Inf)将两个输入(沿维度#3)连接起来,形成单个(2 × 1)输出层支出= concatenationLayer (3 2“名字”,“平均值和sdev”);添加层到layerGraph网络对象actorNet=layerGraph(inPath);actorNet=addLayers(actorNet,meanPath);actorNet=addLayers(actorNet,sdevPath);actorNet=addLayers(actorNet,outLayer);%连接层:平均值路径输出必须连接到连接层的第一个输入actorNet = connectLayers (actorNet,“ip_out”,“mp_fc1/in”);%将inPath的输出连接到meanPath输入actorNet = connectLayers (actorNet,“ip_out”,“vp_fc1/in”);%连接inPath输出到sdevPath输入actorNet = connectLayers (actorNet,“mp_out”,“平均值和sdev/in1”);将meanPath的输出连接到mean&sdev输入#1actorNet = connectLayers (actorNet,“vp_out”,“平均值和sdev/in2”);%将sdevPath的输出连接到均值和sdev输入#2%绘图网络情节(actorNet)
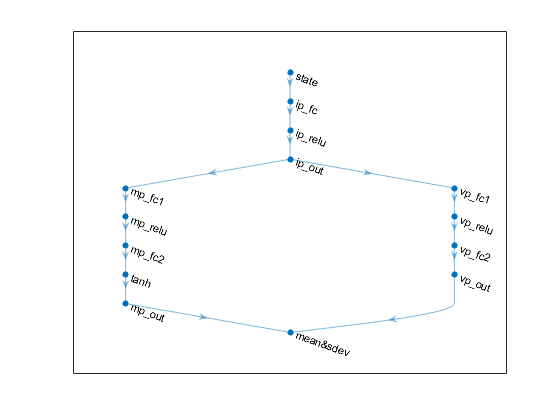
为参与者指定一些选项,并使用深度神经网络创建随机参与者表示actorNet.
为演员设置一些训练选项actorOpts = rlRepresentationOptions (“LearnRate”, 8 e - 3,“GradientThreshold”1);%使用网络创建参与者actor=rl随机因素表示(actorNet、obsInfo、actInfo、,...“观察”,{“状态”}, actorOpts);
指定代理选项,并使用actor、critic和agent选项创建AC代理。
agentOpts = rlACAgentOptions (“NumStepsToLookAhead”32岁的“DiscountFactor”, 0.99);代理= rlACAgent(演员、评论家、agentOpts)
agent=rlACAgent,具有以下属性:AgentOptions:[1x1 rl.option.rlACAgentOptions]
要检查您的代理,请使用getAction从随机观察返回操作。
getAction(代理,{rand(2,1)})
ans =1x1单元阵列{[0.6668]}
现在可以在环境中测试和培训代理。
提示
对于连续的动作空间,
拉卡金特对象不强制执行动作规范设置的约束,因此必须在环境中强制执行动作空间约束。
你也可以从以下列表中选择一个网站: