rlPGAgent
策略梯度强化学习代理
描述
策略梯度(PG)算法是一种无模型、在线、基于策略的强化学习方法。PG智能体是一种基于策略的强化学习智能体,它直接计算出使长期收益最大化的最优策略。动作空间可以是离散的,也可以是连续的。
创造
语法
描述
根据观察和操作规范创建代理
代理人=rlPGAgent(观测信息,行动信息,初始选项)初始选项对象。策略梯度代理不支持递归神经网络。万博1manbetx有关初始化选项的更多信息,请参见rlAgentInitializationOptions.
从演员和评论家代表创建代理
代理人=rlPGAgent(演员)UseBaseline代理人的财产为:错误的在这种情况下。
输入参数
性质
目标函数
例子
根据观察和行动规范创建离散策略梯度代理
创建具有离散动作空间的环境,并获取其观察和动作规范。对于本例,加载示例中使用的环境使用深度网络设计器创建代理和使用图像观察训练。此环境有两个观测值:一个50×50的灰度图像和一个标量(摆锤的角速度)。动作是一个标量,有五个可能的元素(扭矩为-2., -1.,0,1.,或2.Nm适用于极点)。
加载预定义环境env=rlPredefinedEnv(“SimplePendulumWithImage-Discrete”);%获得观察和行动规范obsInfo=getObservationInfo(env);actInfo=getActionInfo(env);
代理创建函数随机初始化参与者和批评者网络。您可以通过固定随机生成器的种子来确保重现性。为此,取消下面一行的注释。
% rng (0)
根据环境观察和操作规范创建策略梯度代理。
agent=rlPGAgent(obsInfo,actInfo);
要检查您的代理,请使用getAction从随机观察中返回动作。
getAction(代理,{rand(obsInfo(1.Dimension),rand(obsInfo(2.Dimension)})
ans=1x1单元阵列{[2]}
现在可以在环境中测试和培训代理。
使用初始化选项创建连续策略梯度代理
创造一个具有连续动作空间的环境,并获得其观察和动作规范。对于本示例,请加载示例中使用的环境通过图像观察训练DDPG药剂摆动和平衡摆锤.这个环境有两个观测值:一个50乘50的灰度图像和一个标量(钟摆的角速度)。这个作用是一个标量,表示从-连续范围的扭矩2.到2.Nm。
加载预定义环境env=rlPredefinedEnv(“SimplePendulumWithImage连续”);%获得观察和行动规范obsInfo=getObservationInfo(env);actInfo=getActionInfo(env);
创建一个代理初始化选项对象,指定网络中每个隐藏的完全连接层必须具有128神经元(而不是默认的数字,256)。策略梯度代理不支持循环网络,因此设置万博1manbetxUseRNN选项真正的创建代理时生成错误。
initOpts=rlagentinizationoptions(“NumHiddenUnit”,128);
代理创建函数随机初始化参与者和批评者网络。您可以通过固定随机生成器的种子来确保重现性。为此,取消下面一行的注释。
% rng (0)
根据环境观察和操作规范创建策略梯度代理。
agent=rlPGAgent(obsInfo、actInfo、initOpts);
将批判学习率降低到1e-3。
评论家= getCritic(代理);critic.Options.LearnRate = 1 e - 3;代理= setCritic(代理、批评);
从agent参与者和批评家中提取深层神经网络。
actorNet=getModel(getActor(agent));criticNet=getModel(getCritic(agent));
显示批评网络的各层,并验证每个隐藏的全连接层有128个神经元
临界层
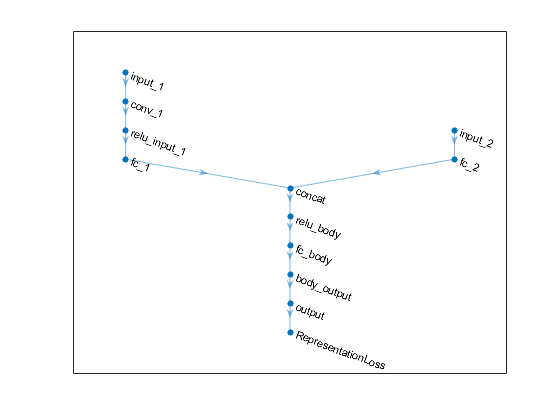
ans=12x1带层的层阵列:1“concat”沿维度2个输入的串联3“relu_body”relu relu 3“fc_body”完全连接128个完全连接的层4“body_输出”relu relu 5“input_1”图像输入50x50x1图像6“conv_1”卷积64 3x1x1带跨步[1]和填充的卷积[0 0 0 0 0]7“relu_输入_1”relu relu 8“fc_1”完全连接128完全连接层9“input_2”图像输入1x1x1图像10“fc_2”完全连接128完全连接层11“output”完全连接1完全连接层12“RepresentationLoss”回归输出均方误差
情节演员和评论家网络
情节(actorNet)

绘图(关键网)
要检查您的代理,请使用getAction从随机观察中返回动作。
getAction(代理,{rand(obsInfo(1.Dimension),rand(obsInfo(2.Dimension)})
ans=1x1单元阵列{[0.9228]}
现在可以在环境中测试和培训代理。
从Actor和Baseline Critic创建一个离散PG代理
创建具有离散动作空间的环境,并获取其观察和动作规范。对于本例,加载示例中使用的环境用基线训练PG Agent控制双积分器系统.从环境中观察到的是一个包含质量的位置和速度的矢量。这个作用是一个标量,表示施加在质量上的力,有三个可能的值(-)2.,0,或2.牛顿)。
加载预定义环境env=rlPredefinedEnv(“DoubleIntegrator-Discrete”);%获取观察和规格信息obsInfo=getObservationInfo(env);actInfo=getActionInfo(env);
创建要用作基线的批评家表示。
%创建一个网络用作潜在的评论家近似器baselineNetwork=[imageInputLayer([obsInfo.Dimension(1)1],“正常化”,“没有”,“姓名”,“状态”) fullyConnectedLayer (8,“姓名”,“基线FC”)雷卢耶(“姓名”,“CriticRelu1”)完全连接层(1,“姓名”,“BaselineFC2”,“BiasLearnRateFactor”, 0)];%为评论家设置一些选项baselineOpts=rlRepresentationOptions(“LearnRate”, 5 e - 3,“梯度阈值”1);%基于网络逼近器创建批评家基线=rlValueRepresentation(基线网络、obsInfo、,“观察”,{“状态”},基线选项);
创建一个参与者表示。
%创建一个用作底层参与者近似器的网络actorNetwork=[imageInputLayer([obsInfo.Dimension(1)1],“正常化”,“没有”,“姓名”,“状态”)完整连接层(numel(actInfo.元素),“姓名”,“行动”,“BiasLearnRateFactor”, 0)];%为演员设置一些选项actorOpts=rlRepresentationOptions(“LearnRate”, 5 e - 3,“梯度阈值”1);%基于网络近似器创建参与者演员= rlStochasticActorRepresentation (actorNetwork obsInfo actInfo,...“观察”,{“状态”},actorOpts);
指定代理选项,并使用环境、actor和评论家创建一个PG代理。
agentOpts=rlPGAgentOptions(...“使用基线”,真的,...“DiscountFactor”, 0.99);代理= rlPGAgent(演员、基线、agentOpts)
agent = rlPGAgent with properties: AgentOptions: [1x1 rl.option.rlPGAgentOptions]
要检查代理,请使用getAction从随机观察返回操作。
getAction(代理,{rand(2,1)})
ans=1x1单元阵列{[2]}
现在可以在环境中测试和培训代理。
从演员和基线评论家创建一个连续的PG代理
创建具有连续动作空间的环境,并获取其观察和动作规范。对于本例,加载示例中使用的双积分连续动作空间环境培训DDPG代理控制双积分系统.
加载预定义环境env=rlPredefinedEnv(“DoubleIntegrator-Continuous”);%获取观测规范信息obsInfo=getObservationInfo(环境)
obsInfo=rlNumericSpec,属性:LowerLimit:-Inf上限:Inf名称:“状态”说明:“x,dx”维度:[2 1]数据类型:“双”
%获取操作规范信息actInfo=getActionInfo(环境)
属性:LowerLimit: -Inf UpperLimit: Inf Name: "force" Description: [0x0 string] Dimension: [1 1] DataType: "double"
在本例中,动作是一个标量输入,表示从-2.到2.牛顿,因此,设置相应的动作信号的上限和下限是一个好主意。当参与者的网络表示具有非线性输出层时,必须这样做,而不是需要相应地缩放以在所需范围内产生输出。
%确保动作空间的上限和下限是有限的actInfo.LowerLimit = 2;actInfo.UpperLimit = 2;
创建要用作基线的批评家表示。策略梯度代理使用rlValueRepresentation基线。对于连续观测空间,可以使用深度神经网络或自定义基表示。对于本例,创建一个深度神经网络作为底层近似器。
%创建一个网络用作潜在的评论家近似器baselineNetwork = [imageInputLayer([obsInfo. baselineNetwork])]尺寸1],“正常化”,“没有”,“姓名”,“状态”) fullyConnectedLayer (8,“姓名”,“BaselineFC1”)雷卢耶(“姓名”,“Relu1”)完全连接层(1,“姓名”,“BaselineFC2”,“BiasLearnRateFactor”, 0)];为评论家设置一些训练选项baselineOpts=rlRepresentationOptions(“LearnRate”, 5 e - 3,“梯度阈值”1);%基于网络逼近器创建批评家基线=rlValueRepresentation(基线网络、obsInfo、,“观察”,{“状态”},基线选项);
策略梯度代理使用rlStochasticActorRepresentation.对于连续动作空间随机参与者,只能使用神经网络作为基础近似器。
观察输入(这里称为myobs)必须接受二维向量,如obsInfo.输出(此处称为myact)还必须是二维向量(是中指定的维数的两倍)肌动蛋白).输出向量的元素依次表示每个动作的所有平均值和所有标准偏差(在本例中只有一个平均值和一个标准偏差)。
标准偏差必须是非负的,而平均值必须在输出范围内,这意味着网络必须有两条独立的路径。第一条路径用于平均值,任何输出非线性都必须缩放,以便能够在输出范围内产生输出。第二条路径用于方差,您必须使用用于强制非负性的softplus或relu层。
%输入路径层(2×1输入,1×1输出)inPath = [imageInputLayer([obsInfo. inPath])]尺寸1],“正常化”,“没有”,“姓名”,“状态”) fullyConnectedLayer (10“姓名”,“ip_fc”)%10乘1输出雷卢耶(“姓名”,“ip_relu”)%非线性fullyConnectedLayer (1,“姓名”,“ip_out”) ];%1乘1输出%平均值的路径层(1×1输入和1×1输出)%使用scalingLayer缩放范围meanPath = [fulllyconnectedlayer (15,“姓名”,“mp_fc1”)%15乘1输出雷卢耶(“姓名”,“mp_relu”)%非线性fullyConnectedLayer (1,“姓名”,“mp_fc2”);%1乘1输出tanhLayer (“姓名”,的双曲正切);%输出范围:(-1,1)scalingLayer (“姓名”,“mp_out”,“规模”,actInfo.上限];%输出范围:(-2N,2N)%路径层的标准偏差(1 × 1输入和输出)%使用softplus图层使其非负sdevPath=[fullyConnectedLayer(15,“姓名”,“vp_fc1”)%15乘1输出雷卢耶(“姓名”,“vp_relu”)%非线性fullyConnectedLayer (1,“姓名”,“vp_fc2”);%1乘1输出softplusLayer (“姓名”,“vp_out”) ];%输出范围:(0,+Inf)将两个输入(沿维度#3)连接起来,形成单个(2 × 1)输出层outLayer=连接层(3,2,“姓名”,“平均值和sdev”);添加层到layerGraph网络对象actorNet=图层图(inPath);actorNet=addLayers(actorNet,meanPath);actorNet=addLayers(actorNet,sdevPath);actorNet=addLayers(actorNet,outLayer);%连接层:平均值路径输出必须连接到连接层的第一个输入actorNet=连接层(actorNet,“ip_out”,“mp_fc1/in”);%连接inPath的输出到meanPath的输入actorNet=连接层(actorNet,“ip_out”,“vp_fc1 /”);%连接inPath的输出到variancePath的输入actorNet=连接层(actorNet,“mp_out”,“mean&sdev /三机一体”);%将meanPath的输出连接到mean&sdev输入#1actorNet=连接层(actorNet,“vp_out”,“mean&sdev / in2”);%连接sdevPath的输出到mean&sdev input #2%绘图网络情节(actorNet)

为参与者指定一些选项,并使用深层神经网络创建随机参与者表示actorNet.
%为演员设置一些选项actorOpts=rlRepresentationOptions(“LearnRate”, 5 e - 3,“梯度阈值”1);%基于网络近似器创建参与者actor=rl随机因素表示(actorNet、obsInfo、actInfo、,...“观察”,{“状态”},actorOpts);
指定代理选项,并使用actor、baseline和agent选项创建PG代理。
agentOpts=rlPGAgentOptions(...“使用基线”,真的,...“DiscountFactor”, 0.99);代理= rlPGAgent(演员、基线、agentOpts)
agent = rlPGAgent with properties: AgentOptions: [1x1 rl.option.rlPGAgentOptions]
要检查代理,请使用getAction从随机观察返回操作。
getAction(代理,{rand(2,1)})
ans=1x1单元阵列{[0.0347]}
现在可以在环境中测试和培训代理。
提示
对于连续动作空间
rlPGAgent代理不强制执行操作规范设置的约束,因此必须在环境中强制执行操作空间约束。
另见
深度网络设计器|rlAgentInitializationOptions|rlPGAgentOptions|rlStochasticActorRepresentation|rlValueRepresentation
你也可以从以下列表中选择一个网站: