基于深度学习网络的语音去噪
这个例子展示了如何使用深度学习网络去噪语音信号。这个例子比较了应用于同一任务的两种类型的网络:全连接网络和卷积网络。
介绍
语音去噪的目的是去除语音信号中的噪声,同时提高语音的质量和清晰度。本例展示了使用深度学习网络从语音信号中去除洗衣机噪声的方法。该示例比较了应用于同一任务的两种类型的网络:完全连接网络和卷积网络。
问题摘要
考虑在8 kHz时采样的以下语音信号。
[cleanAudio,fs]=音频读取(“SpeechDFT-16-8-mono-5秒波形”); 声音(音频,fs)
将洗衣机噪声添加到语音信号中。设置噪声功率,使信噪比(SNR)为零dB。
噪声=音频读取(“洗衣机- 16 - 8 mono - 1000 - secs.mp3”);%从噪波文件中的随机位置提取噪波段= randi(numel(noise) - numel(cleanAudio) + 1,1,1);noiseSegment = noise(ind:ind + numel(cleanAudio) - 1);speechPower =总和(cleanAudio。^ 2);noisePower =总和(noiseSegment。^ 2);noisyAudio = cleanAudio + sqrt(speechPower/noisePower) * noisessegment;
听嘈杂的语音信号。
声音(Noisyaudio,FS)
可视化原始和嘈杂的信号。
t=(1/fs)*(0:numel(cleanAudio)-1;子地块(2,1,1)地块(t,cleanAudio)标题(“干净的音频”)网格在次要情节(2,1,2)情节(t, noisyAudio)标题(“嘈杂的音频”)包含(“时间”)网格在

语音去噪的目的是从语音信号中去除洗衣机噪声,同时最小化输出语音中不希望出现的伪影。
检查数据集
此示例使用Mozilla公共语音数据集的子集[1.]培训和测试深度学习网络。数据集包含讲短句的主题的48 kHz录制。下载数据集并解压缩下载的文件。
网址='http://ssd.mathworks.com/万博1manbetxsupportfiles/audio/commonvoice.zip';downloadfolder = tempdir;datafolder = fullfile(downloadlefolder,“大众之声”);如果~exist(数据文件夹,“dir”)disp('正在下载数据集(956 MB)…')解压缩(URL,DownloadFolder)终止
使用音频数据存储为培训集创建数据存储。以性能成本加快示例的运行时,设置reduceDataset到真正的.
adsTrain=音频数据存储(完整文件(数据文件夹,“火车”),“包含子文件夹”,true);还原的状态集=真正的;如果简化数据集adsTrain=随机(adsTrain);adsTrain=子集(adsTrain,1:1000);终止

使用读获取数据存储中第一个文件的内容。
[音频,adsTrainInfo]=读取(adsTrain);
听语音信号。
声音(音频,adstraininfo.samplerate)
绘制语音信号。
图t=(1/adsTrainInfo.SampleRate)*(0:numel(音频)-1);绘图(t,音频)标题(“示例性语音信号”)包含(“时间”)网格在

深度学习系统概述
基本的深度学习训练方案如下图所示。请注意,由于语音通常低于4khz,您首先将干净和嘈杂的音频信号采样到8khz,以减少网络的计算负载。预测器和目标网络信号分别是噪声和纯净音频信号的幅值谱。网络的输出是去噪后信号的幅值谱。回归网络使用预测输入来最小化其输出和输入目标之间的均方误差。去噪后的音频通过输出幅度谱和噪声信号的相位被转换回时域[2.].

使用短时傅里叶变换(STFT)将音频变换到频域,窗口长度为256个样本,重叠率为75%,并使用汉明窗口。通过删除对应于负频率的频率样本(因为时域语音信号是真实的,这不会导致任何信息丢失),可以将频谱向量的大小减小到129。预测器输入由8个连续的带噪STFT向量组成,因此每个STFT输出估计是基于当前带噪STFT和7个先前带噪STFT向量计算的。
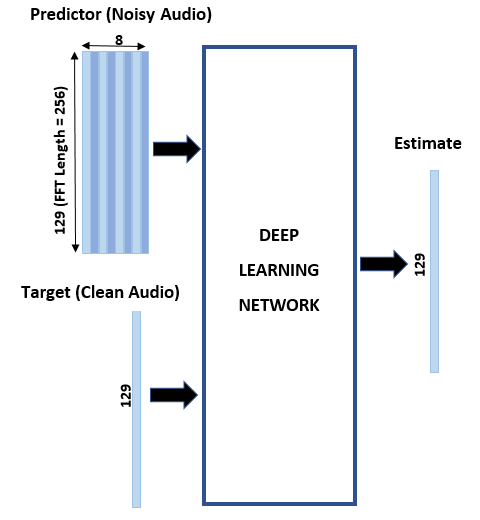
短期融资目标和预测因素
本节说明了如何从一个训练文件生成目标和预测信号。
一、定义系统参数:
windowLength=256;win=hamming(windowLength,“定期”);重叠=圆形(0.75 * windowlength);fftlength = windowlength;Inputfs = 48E3;FS = 8E3;NumFeatures = FFTLength / 2 + 1;numsegments = 8;
创建一个dsp.samplerateconverter.(DSP系统工具箱)对象将48 kHz音频转换为8 kHz。
src=dsp.0转换器(“输入采样器”,Inputfs,......“OutputSampleRate”,财政司司长,......“带宽”,7920);
使用读从数据存储中获取音频文件的内容。
音频=阅读(adsTrain);
确保音频长度是采样率转换器抽取因子的倍数。
decimationFactor = InputFS / FS;L =楼层(NUMER(音频)/抽取物质);音频=音频(1:DecimationFactor * L);
将音频信号转换为8 kHz。
音频=src(音频);重置(src)
从洗衣机噪声矢量创建随机噪声段。
Randind = randi(numel(noise) - numel(audio),[1 1]);noise = noise(randind: randind + numel(audio) - 1);
在语音信号中加入噪声,使其信噪比为0 dB。
noisePower =总和(noiseSegment。^ 2);CleanPower = Sum(音频。^ 2);noisesement = noisesegment。* sqrt(CleanPower / Noispower);noisyaudio =音频+ noisesement;
使用st从原始和噪声音频信号生成幅值STFT向量。
cleanSTFT=stft(音频,'窗户'赢'overlaplencth'重叠“FFTLength”,fft长度);cleanSTFT=abs(cleanSTFT(numFeatures-1:end,:);noisestft=stft(noiseyaudio,'窗户'赢'overlaplencth'重叠“FFTLength”,ffTLength);noisestft=abs(noisestft(numFeatures-1:end,:);
从有噪声的STFT生成8段训练预测信号。连续预测值之间的重叠为7段。
noisestft=[noisestft(:,1:numSegments-1),noisestft];stftSegments=0(numFeatures,numSegments,size(noisestft,2)-numSegments+1);对于索引=1:size(noisySTFT,2)-numSegments+1 stftSegments(:,:,index)=(noisySTFT(:,index:index+numSegments-1));终止
设定目标和预测因素。两个变量的最后一个维度对应于由音频文件生成的不同预测器/目标对的数量。每个预测器是129乘8,每个目标是129乘1。
目标=cleanSTFT;规模(目标)
ans=1×2129 544
预测值=标准时间段;规模(预测因素)
ans=1×3129 8 544
使用高阵列提取特征
为了加快处理速度,请使用高数组从数据存储中所有音频文件的语音片段中提取特征序列。与内存中的数组不同,高数组通常在调用聚集此延迟评估使您能够快速处理大型数据集。当您最终使用聚集,Matlab在可能的情况下结合了排队的计算,并通过数据占据最小次数。如果您有并行计算工具箱™,则可以在本地MATLAB会话中或在本地并行池中使用高阵列。如果安装了MATLAB®PartinalServer™,您还可以在群集中运行高阵列计算。
首先,将数据存储转换为高数组。
复位(adsTrain)T=高(adsTrain)
正在使用连接到并行池的“本地”配置文件启动并行池(parpool)(工作进程数:6)。
T=M×1高单元阵列{234480×1 double}{210288×1 double}{282864×1 double}{292080×1 double}{410736×1 double}{303600×1 double}{326640×1 double}{233328×1 double}::
显示表明行数(与数据存储中的文件数相对应)M未知。M是占位符,直到计算完成。
从tall表格中提取目标和预测器幅值STFT。此操作将创建新的tall数组变量以用于后续计算。函数HelperGenerateSpeechDenoisingFeatures执行中已突出显示的步骤短期融资目标和预测因素部分。这赛尔芬命令适用于HelperGenerateSpeechDenoisingFeatures添加到数据存储中每个音频文件的内容。
[targets,predictors]=cellfun(@(x)HelperGenerateSpeechDenoisingFeatures(x,noise,src),T,“统一输出”、假);
使用聚集评估目标和预测因素。
[目标,预测值]=聚集(目标,预测值);
使用并行池“local”计算tall表达式:-通过1/1:在42秒内完成计算在1分钟36秒内完成
将所有特征标准化为零均值和统一标准差是一种很好的做法。
分别计算预测值和目标值的平均值和标准偏差,并使用它们来规范化数据。
预测=猫({}):3,预测指标;noisyMean =意味着(预测(:));noisyStd =性病(预测(:));predictors(:) = (predictors(:) - noisyMean)/noisyStd;目标=猫({}):2、目标;cleanMean =意味着(目标(:));cleanStd =性病(目标(:));targets(:) = (targets(:) - cleanMean)/cleanStd;
将预测因素和目标重塑为深度学习网络所期望的维度。
预测=重塑(预测、大小(预测,1),大小(预测,2),1,大小(预测,3));目标=重塑(目标1 1、大小(目标1),大小(目标2));
您将在培训期间使用1%的数据进行验证。验证可用于检测网络过度拟合培训数据的情况。
随机将数据拆分为培训和验证集。
inds=randperm(大小(预测器,4));L=round(0.99*大小(预测器,4));TrainPredicts=Predicts(:,:,:,inds(1:L));trainTargets=targets(:,:,:,:,inds(1:end));validateTargets=targets(:,:,:,inds(1:end));
全连接层语音去噪
首先考虑一个由全连接层组成的去噪网络。完全连接层中的每个神经元都与前一层的所有激活相连接。一个完全连接的层将输入乘以一个权重矩阵,然后添加一个偏置向量。权重矩阵和偏差向量的维数由该层神经元的数量和前一层激活的数量决定。
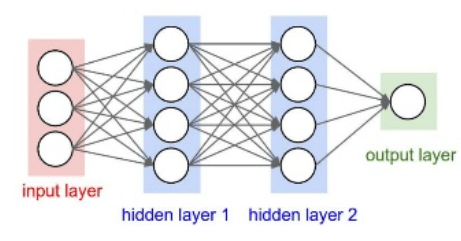
定义网络的层。将输入大小指定为图像大小NUM特征-借-NumSegments(本例中为129×8)。定义两个隐藏的完全连接的层,每个层有1024个神经元。由于是纯线性系统,所以在每个隐藏的完全连接层后面都有一个校正线性单元(ReLU)层。批量标准化层标准化输出的平均值和标准偏差。添加一个包含129个神经元的完全连接层,然后是回归层。
图层= [imageInputlayer([NumFeatures,NumSegments])全连接列
接下来,指定网络的培训选项。设置最大时代到3.因此,网络通过训练数据进行3次传递小批量的128.这样网络一次可以查看128个训练信号。指定绘图像“培训 - 进展”当迭代次数增加时,生成显示培训进度的地块。放冗长的到错误的禁用将与绘图中显示的数据相对应的表输出打印到命令行窗口。指定洗牌像“每个时代”在每个历元开始时洗牌训练序列。指定LearnRateSchedule到“分段”每次经过一定数量的纪元(1)时,将学习率降低指定的系数(0.9)。设置验证数据验证预测器和目标。放验证频繁以便每个历元计算一次验证均方误差。这个例子使用自适应矩估计(Adam)求解器。
miniBatchSize = 128;选项=培训选项(“亚当”,......“最大时代”3.......“初始学习率”1 e-5......“最小批量大小”,小批量,......“洗牌”,“每个时代”,......“情节”,“培训 - 进展”,......“冗长”假的,......“验证职业”、地板(大小(trainPredictors, 4) / miniBatchSize),......“LearnRateSchedule”,“分段”,......“LearnRateDropFactor”,0.9,......“LearnRateDropPeriod”1.......“验证数据”,{validatePredictors,validateTargets});
使用指定的培训选项和层体系结构培训网络列车网络。由于培训集很大,培训过程可能需要几分钟。若要下载并加载预先培训的网络,而不是从头开始培训网络,请设置溺爱到错误的.
dotraining =.真正的;如果doTraining denoiseNetFullyConnected = trainNetwork(trainPredictors,trainTargets,layers,options);其他的网址=“http://ssd.mathworks.com/万博1manbetxsupportfiles/audio/SpeechDenoising.zip”;downloaddnetfolder = tempdir;netfolder = fullfile(downloadnetfolder,'SpeepDenoising');如果~exist(netFolder,“dir”)disp('正在下载预训练网络(1个文件-8 MB)…')解压缩(URL,DownloadNetFolder)终止s=加载(完整文件(netFolder,“denoisenet.mat”)); denoiseNetFullyConnected=s.denoiseNetFullyConnected;cleanMean=s.cleanMean;cleanStd=s.cleanStd;Noisyman=s.Noisyman;noisestd=s.noisestd;终止

计算网络完全连接层中的权重数。
重量=0;对于index = 1:numel(denoisenetluelyconnected.layers)如果isa(表示完全连接的层(索引),“nnet.cnn.layer.FullyConnectedLayer”)numWeights=numWeights+nummel(表示完全连接的层(索引).Weights);终止终止fprintf(“权重数为%d。\n”,单位重量);
权重的数量为2237440。
用卷积层去噪
考虑一个使用卷积层而不是完全连接层的网络[3.].二维卷积层对输入应用滑动滤波器。该层通过沿输入垂直和水平移动滤波器,计算权重和输入的点积,然后添加偏差项,从而卷积输入。卷积层通常比完全连接层包含更少的参数。
定义[中描述的完全卷积网络的图层3.,由16个卷积层组成。前15个卷积层为3层一组,重复5次,滤波器宽度分别为9、5、9,滤波器数量分别为18、30、8。最后一个卷积层的滤镜宽度为129和1。在该网络中,只在一个方向(沿频率维度)进行卷积,除第一层外,所有层沿时间维度的滤波器宽度均设为1。与全连接网络类似,卷积层之后是ReLu层和批处理归一化层。
图层= [ImageInputLayer([NumFeatures,NumSegments])卷积2dlayer([9 8],18,“跨步”100年[1],“填充”,“相同”)batchNormalizationLayer reluLayer repmat(......[卷积2dlayer([5 1],30,“跨步”100年[1],“填充”,“相同”)BatchnormalizationLayer Rufulayer卷积2dlayer([9 1],8,“跨步”100年[1],“填充”,“相同”)batchNormalizationLayer reluLayer卷积2Dlayer([9 1],18,“跨步”100年[1],“填充”,“相同”)BatchnormalizationLayer Ruilulayer],4,1)卷积2dlayer([5 1],30,“跨步”100年[1],“填充”,“相同”)BatchnormalizationLayer Rufulayer卷积2dlayer([9 1],8,“跨步”100年[1],“填充”,“相同”)BatchnormalizationLayer Rufulayer卷积2dlayer([129 1],1,“跨步”100年[1],“填充”,“相同”)回归层次];
培训选项与完全连接网络的选项相同,不同之处在于允许验证目标信号的尺寸符合回归层预期的尺寸。
选项=培训选项(“亚当”,......“最大时代”3.......“初始学习率”1 e-5......“最小批量大小”,小批量,......“洗牌”,“每个时代”,......“情节”,“培训 - 进展”,......“冗长”假的,......“验证职业”、地板(大小(trainPredictors, 4) / miniBatchSize),......“LearnRateSchedule”,“分段”,......“LearnRateDropFactor”,0.9,......“LearnRateDropPeriod”1.......“验证数据”,{validatePredictors,permute(validateTargets,[3 1 2 4])});
使用指定的培训选项和层体系结构培训网络列车网络。由于培训集很大,培训过程可能需要几分钟。若要下载并加载预先培训的网络,而不是从头开始培训网络,请设置溺爱到错误的.
dotraining =.真正的;如果DotTraining DenoiseFullyConvolutional=列车网络(列车预测器、排列(列车目标[3 1 2 4])、层、选项);其他的网址=“http://ssd.mathworks.com/万博1manbetxsupportfiles/audio/SpeechDenoising.zip”;downloaddnetfolder = tempdir;netfolder = fullfile(downloadnetfolder,'SpeepDenoising');如果~exist(netFolder,“dir”)disp('正在下载预训练网络(1个文件-8 MB)…')解压缩(URL,DownloadNetFolder)终止s=加载(完整文件(netFolder,“denoisenet.mat”));denoisenetlulyconstooldal = s.denoisenetfullycollycollyal;Cleanmean = S.Cleanmean;cleanstd = s.cleanstd;noisymean = s.noisymean;Noisystd = S.Noisystd;终止

计算网络完全连接层中的权重数。
重量=0;对于索引=1:numel(denoiseNetFullyConvolutional.Layers)如果isa(非完整协同进化层(索引),“nnet.cnn.layer.Convolution2DLayer”)numWeights=numWeights+numel(denoiseNetFullyConvolutional.Layers(index).Weights);终止终止fprintf(“卷积层中的权重数为%d\n”,单位重量);
卷积层中的重量数为31812
测试去噪网络
在测试数据集中读取。
adstest = audiodataStore(fullfile(datafolder,“测试”),“包含子文件夹”,真的);
从数据存储读取文件的内容。
[cleanAudio, adsTestInfo] =阅读(adsTest);
确保音频长度是采样率转换器抽取因子的倍数。
L=地板(numel(清洁音频)/决策系数);cleanAudio=cleanAudio(1:决定因子*L);
将音频信号转换为8 kHz。
CleanAudio = SRC(CleanAudio);重置(SRC)
在此测试阶段,您将使用培训阶段未使用的洗衣机噪音破坏语音。
噪声=音频读取(“洗衣机- 16 - 8 mono - 200 - secs.mp3”);
从洗衣机噪声矢量创建随机噪声段。
randind=randi(numel(噪音)-numel(清洁音频),[1]);noiseSegment=noise(randind:randind+numel(清洁音频)-1);
在语音信号中加入噪声,使其信噪比为0 dB。
noisePower=sum(noiseSegment.^2);cleanPower=sum(cleanAudio.^2);noiseSegment=noiseSegment.*sqrt(cleanPower/noisePower);NoiseAudio=cleanAudio+noiseSegment;
使用st从噪声音频信号生成幅值STFT向量。
noisestft=stft(noiseyaudio,'窗户'赢'overlaplencth'重叠“FFTLength”,ffTLength);NoisePhase=角度(NoiseStft(numFeatures-1:end,:);NoiseStft=abs(NoiseStft(numFeatures-1:end,:);
从有噪声的STFT生成8段训练预测信号。连续预测值之间的重叠为7段。
noisySTFT = [noisySTFT(:,1:numSegments-1) noisySTFT];predictors = 0 (numFeatures, numSegments, size(noisySTFT,2) - numSegments + 1);对于索引=1:(大小(noisestft,2)-numSegments+1)预测值(:,:,index)=noisestft(:,index:index+numSegments-1);终止
通过训练阶段计算的平均值和标准偏差来对预测器进行归一化。
预测因子(:)=(预测因子(:)-noisyman)/noisyStd;
使用预测通过两个训练有素的网络。
predictors =重塑(predictors, [numFeatures,numSegments,1,size(predictors,3)]);STFTFullyConnected = predict(denoiseNetFullyConnected, predictors);STFTFullyConvolutional = predict(denoiseNetFullyConvolutional, predictors);
根据培训阶段使用的平均值和标准偏差调整输出。
STFTFullyConnected(:)=cleanStd*STFTFullyConnected(:)+cleanMean;STFTFullyConvolutional(:)=cleanStd*STFTFullyConvolutional(:)+cleanMean;
将单面STFT转换为居中的STFT。
STFTFullyConnected=STFTFullyConnected.*exp(1j*噪声相位);STFTFullyConnected=[conj(STFTFullyConnected(end-1:-1:2,:);STFTFullyConnected];STFTFullyConvolutional=挤压(STFTFullyConvolutional)。*exp(1j*噪声相位);STFTFullyConvolutional=[conj(STFTFullyConvolutional(end-1:-1:2,:);STFTFullyConvolutional];
计算去噪语音信号。伊斯特夫特执行逆STFT。使用带噪STFT向量的相位重建时域信号。
DenoiseDaudoullyConnected=istft(STFTFullyConnected,......'窗户'赢'overlaplencth'重叠......“FFTLength”,fft长度,“共轭对称”,对);DenoiseDaudoullyConvolutional=istft(STFTFullyConvolutional,......'窗户'赢'overlaplencth'重叠......“FFTLength”,fft长度,“共轭对称”,真的);
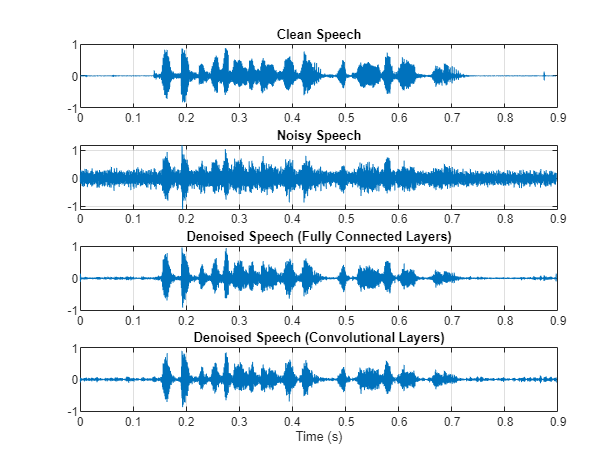
绘制干净、嘈杂和去噪的音频信号。
t=(1/fs)*(0:numel(denoisedAudioFullyConnected)-1);图子图(4,1,1)图(t,cleanAudio(1:numel(denoisedAudioFullyConnected)))标题(“清洁演讲”)网格在子地块(4,1,2)地块(t,noisyAudio(1:numel(DenoiseDaudoully连通)))名称(“嘈杂的演讲”)网格在子地块(4,1,3)地块(t,表示完全连接)名称(“去噪语音(全连接层)”)网格在子地块(4,1,4)地块(t,DenoiseDaudoullyConvolutional)名称(“去噪语音(卷积层)”)网格在xlabel(“时间”)

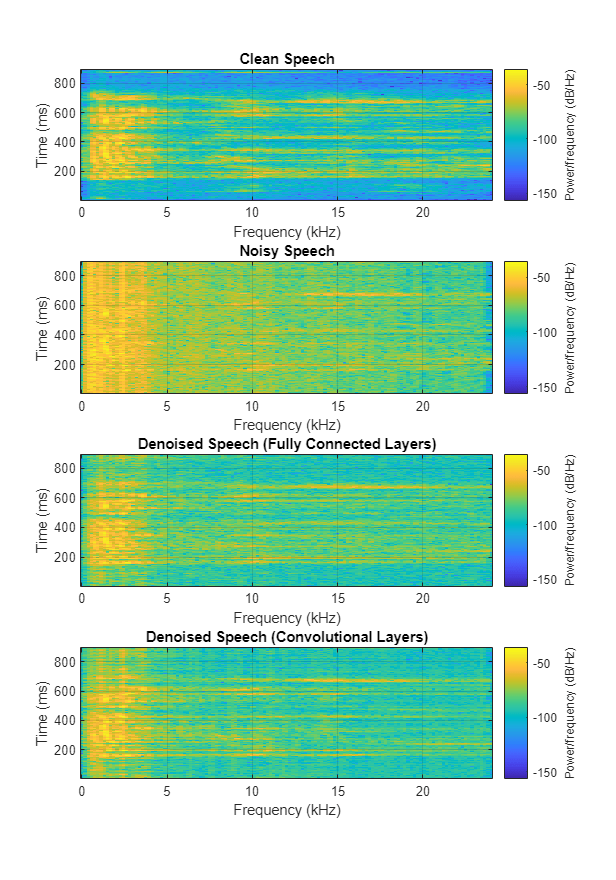
绘制干净、嘈杂和去噪的光谱图。
h=图;子图(4,1,1)频谱图(cleanAudio、win、overlap、ffTLength、fs);标题(“清洁演讲”)网格在子批次(4,1,2)光谱图(“嘈杂的演讲”)网格在次要情节(4 1 3)谱图(ffTLength denoisedAudioFullyConnected,赢,重叠,fs);标题(“去噪语音(全连接层)”)网格在子图(4,1,4)频谱图(denoisedaudiofullyconstoolly,Win,重叠,FFTLength,FS);标题(“去噪语音(卷积层)”)网格在p=get(h,“位置”); 设置(h,“位置”,[p(1) 65 p(3) 800]);

听这嘈杂的演讲。
声音(Noisyaudio,FS)
通过完全连接的图层从网络中聆听去噪语音。
声音(DenoisedAudiofullyConnected,FS)
通过卷积层收听来自网络的去噪语音。
声音(DenoisedAudiofullycollyoollyal,FS)
听干净的演讲。
声音(音频,fs)
您可以通过调用测试去噪网。该函数生成上面突出显示的时域和频域图,并返回干净、嘈杂和去噪的音频信号。
[cleanAudio、NoiseAudio、DenoiseAudoFullyConnected、DenoiseAudoFullyConvolutional]=测试数据网络(adsTest、DenoiseAudoFullyConnected、DenoiseAudoFullyConvolutional、NoiseMan、NoiseySTD、cleanMean、cleanStd);
实时应用
上一节的程序将噪声信号的整个频谱传递到预测.这不适用于要求低延迟的实时应用程序。
跑SpeemDenoiseRealtimeApp.有关如何模拟媒体的媒体的实时版本的示例。该应用程序使用具有完全连接的图层的网络。音频帧长度等于STFT跳尺寸,即0.25 * 256 = 64个样本。
SpeemDenoiseRealtimeApp.启动用户界面(UI)设计用于与模拟交互。用户界面允许您调整参数,结果立即反映在模拟中。您还可以启用/禁用对去噪输出进行操作的噪声门,以进一步降低噪声,以及调整噪声门的攻击时间、释放时间和阈值。您可以收听来自用户界面的嘈杂、干净或去噪音频。

示波器绘制干净的、有噪声的和去噪的信号,以及噪声门的增益。

工具书类
[1]https://voice.mozilla.org/en
[2]“基于深度学习的语音去噪实验”,Ding Liu, Paris Smaragdis, Minje Kim, INTERSPEECH, 2014。
[3] “用于语音增强的完全卷积神经网络”,Se Rim Park,李金元,INTERSPEECH,2017年。
您还可以从以下列表中选择网站:
